
💡 구현해야 하는 기능
화자분리가 가능한 speech to text 구현하기
🤔 어려웠던 점
음성 데이터를 텍스트로 바꾸는 것은 파이썬 라이브러리로 가능했지만, 화자분리라는 문제가 보다 간편한 방법인 라이브러리 사용을 방해했다.
✅ 해결책
그래서 조원분들과 코치님과 함께 찾아본 결과
를 사용하기로 했다!
네이버에서는 stt api로 클로바 스피치 외에 CLOVA Speech Recognition(CSR)를 제공한다. 하지만 우리는 클로바 스피치를 선택하였다.
👩💻 API 비교
CSR을 쓰지 않고 clova speech를 선택한 이유!
1. CSR 사용에 실패했다.ㅎㅎ
- 1분 이상의 오디오 인식이 가능하다.
- 화자분리가 가능하다!
Clova Speech API 사용 방법
다들 api 사용하는거 쉽다고하는데 나는 아직 초보자라그런가? 다들 어렵단말 안하기로 약속했나? 너무 어려웠다!
api 사용은 네이버에서 제공해주는 문서를 참고했다. 백번천번참고했다.
🔻이제 api 사용법을 알아보도록 하자!🔻
1. 회원가입 및 로그인
네이버 api를 사용하기 위해 네이버 클라우드 플랫폼 회원가입을 당연히 한다.
2. 이용 신청하기
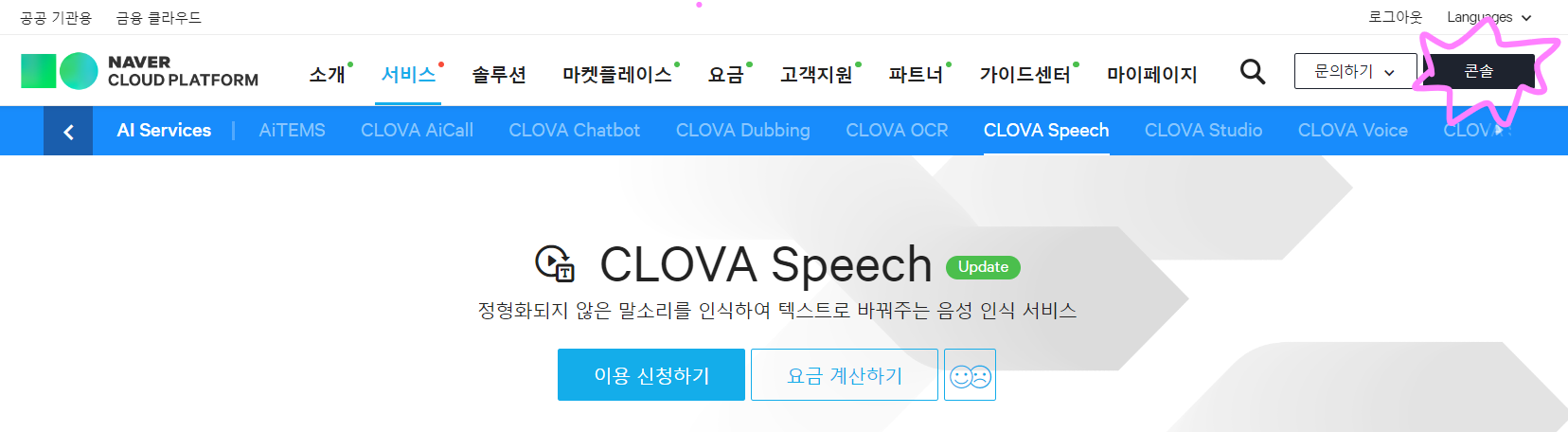
신청 방법은 두 가지가 있다.
선택1. 위 사진에 표시되어있는 콘솔을 클릭하여 ai service에서 기능 선택
선택2. 화면 가운데 이용 신청하기 버튼을 누른다.
설치해야 할 것도 두 가지가 있다.
필수1. clova speech: https://www.ncloud.com/product/aiService/clovaSpeech
필수2. object storage: https://www.ncloud.com/product/storage/objectStorage
clova speech는 스피치와 object storage 버킷을 신청해야한다. 버킷에 있는 데이터를 스피치에 넣는 방식으로 이루어지기 때문에!
위에 해당 사이트를 적어놓았다.
3. 버킷, 도메인 생성
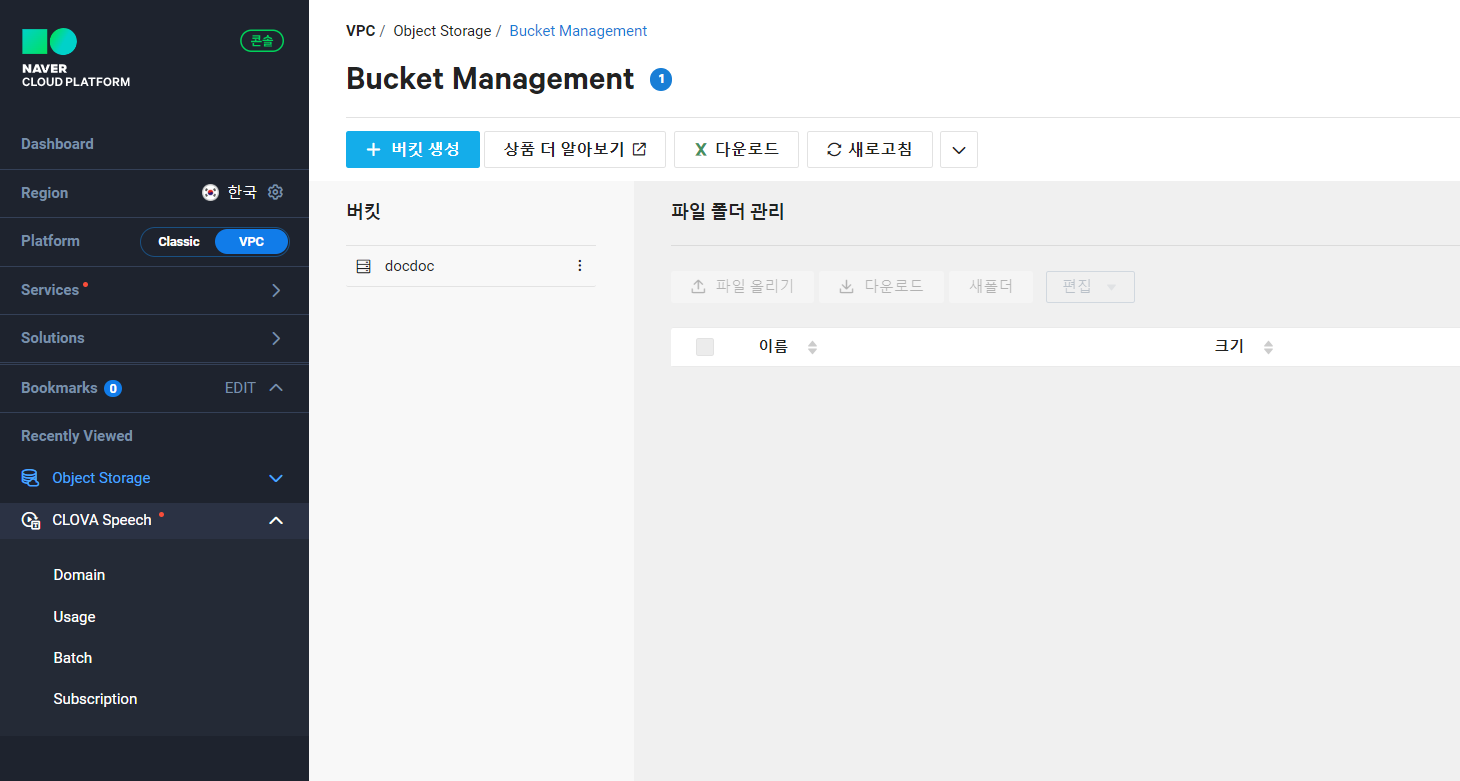
1) object storage에 먼저 들어가 +버킷을 생성한다.
2) clova speech에서 도메인을 생성한다.
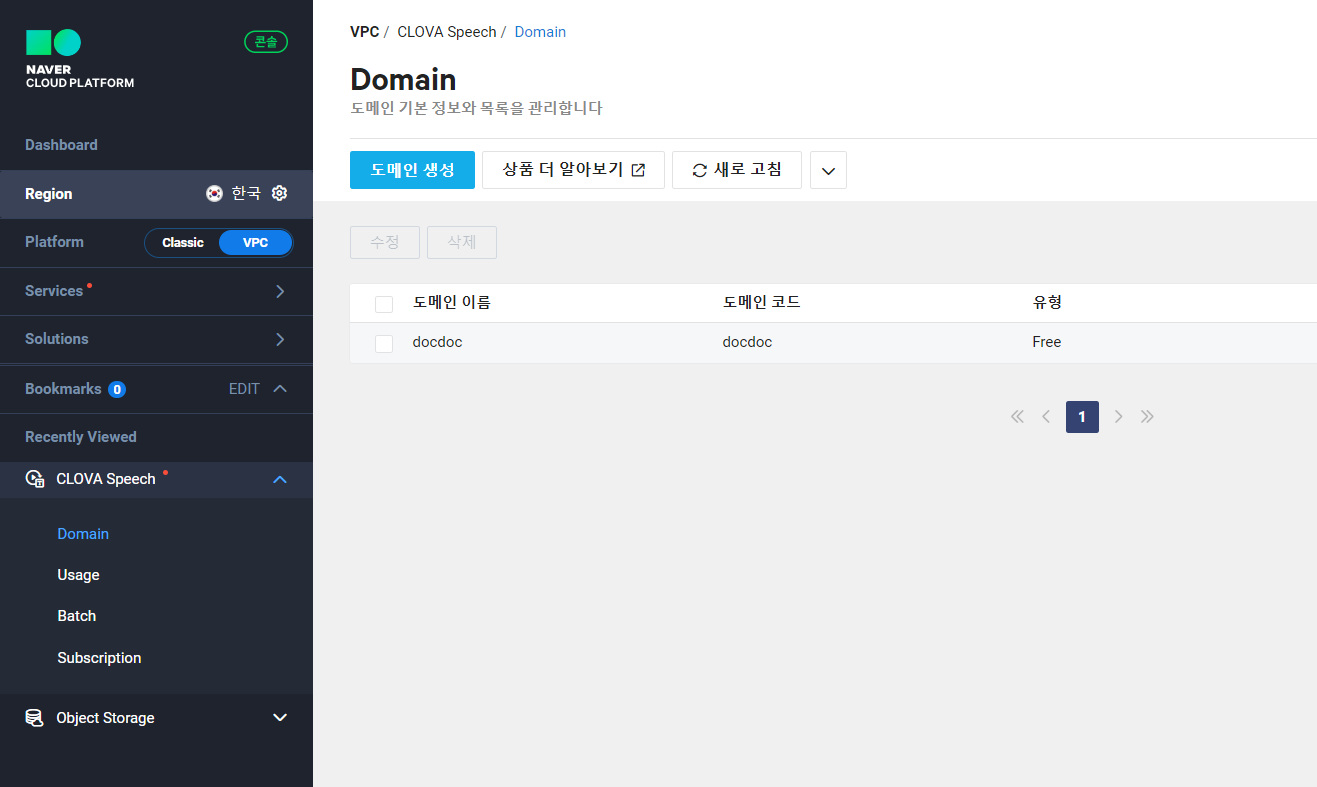
생성 후 빌더실행을 통해 api 근황을 더 자세히 확인할 수 있다.
4. 코드 입력 후 실행
이제 문서에 있는 코드를 입력해 음성 파일을 넣고 실행시키면 된다!
말로하면 이렇게 간단할 수가 없다.
나는 문서이해를 못해서 꽤나 해멨기 때문에 문서를 설명해보려 한다.
CLOVA Speech API
해당 api를 사용하기 위해 두 가지 요소가 발급된다.
- 호출 URL: 이 URL을 사용하여 API 요청을 보내게 된다. domain/setting/Invoke Key에서 확인할 수 있다.
- 시크릿 키: API 요청의 인증에 사용되는 비밀 키이다. 유료(Basic) 플랜을 선택했다면 노출되지않게 본인만 알고있기!
CLOVA Speech API 사용법
각 방식 중 원하는 것을 골라 쓰면 된다.
🌐 요청
-
object storage에 음성 파일 저장해 사용(스토리지 url로 인식 요청)
💨 실패함(datakey값을 도당체 찾을수가없음) -
외부에서 접속가능한 파일의 고유 url로 요청
💨 시도안해봄 -
로컬에서 파일 업로드해서 요청
💨 제일 쉽고 성공함! 로컬의 어느곳에 저장하고 주소를 가져다쓰면 끝!
🌐 응답
-
sync(동기)
💨 나는 이 방법을 썼다. 응답으로 당장 json 형식의 결과를 볼 수 있기 때문에!당장!
💨 vscode에서 ipynb로 실행했고 아래와 같은 json 결과가 당 장 출력되었다. 굿👍💋

-
async(비동기)
💨 입력한 callback url주소 또는 object storage에 인식 결과를 리턴받는다.
Examples
api 활용을 위한 코드들이 여러 언어로 제공되어있다.
나는 파이썬을 사용했고 기존 코드에서 아래와 같은 내용을 필요에 맞게 수정하였다.
✔ 요청 방식을 storage에서 로컬파일 url로 설정
✔ 응답 방식(completion)값을 sync로 설정
✔ 발화자 구분을 위해 diarization을 True로 설정
추가작업
위 examples까지가 문서 내용이였고, 원하는 기능을 위해 아래 코드를 추가해주었다. 출력결과(json)에서 필요한 내용(화자구분이 된 텍스트)만 추출하는 코드이다.
if __name__ == '__main__':
res = ClovaSpeechClient().req_upload(file='korean.m4a', completion='sync')
result = res.json()
# Extract speaker-segmented results
segments = result.get('segments', [])
speaker_segments = []
for segment in segments:
speaker_label = segment['speaker']['label']
text = segment['text']
speaker_segments.append({'speaker': speaker_label, 'text': text})
# Print speaker-segmented results
for speaker_segment in speaker_segments:
speaker_label = speaker_segment['speaker']
text = speaker_segment['text']
print(f'Speaker {speaker_label}: {text}')🔻 결과

ㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎ힇ㄱㅎ긕 ㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎ
블로그는 한개짜리 글이지만 정말 정말 오래걸렸다. 정말로 휴
성공!
