
🎉새로운 프로젝트가 시작됐다!
한국은행 경제통계시스템 조회에 관한 프로젝트로, 주피터 노트북에서 pandas와 numpy를 활용해 데이터를 다룰 예정이다.
데이터 사이언티스트 직업체험이 시작되는 늑김이다~!
본격적으로 프로젝트 진행에 앞서, 오늘은 pandas와 numpy를 이용한 데이터 생성 실습을 해보겠다.
새로운 프로젝트니까 workspace에 economic이라는 새 폴더를 만들어주었다. 거기에 플젝을 진행할 예정이다.
1. 주피터 노트북 시작
우선 chatGPT에게 주피터 노트북을 사용해야하는 이유에 대해 물어보았다.

주피터는 데이터를 시각화하기 좋아서 활용도가 높다고 한다. 데분전용 환경같다!
1) 비주얼 스튜디오 코드 시작
비주얼 스튜디오 코드에서 주피터를 시작하려 한다.
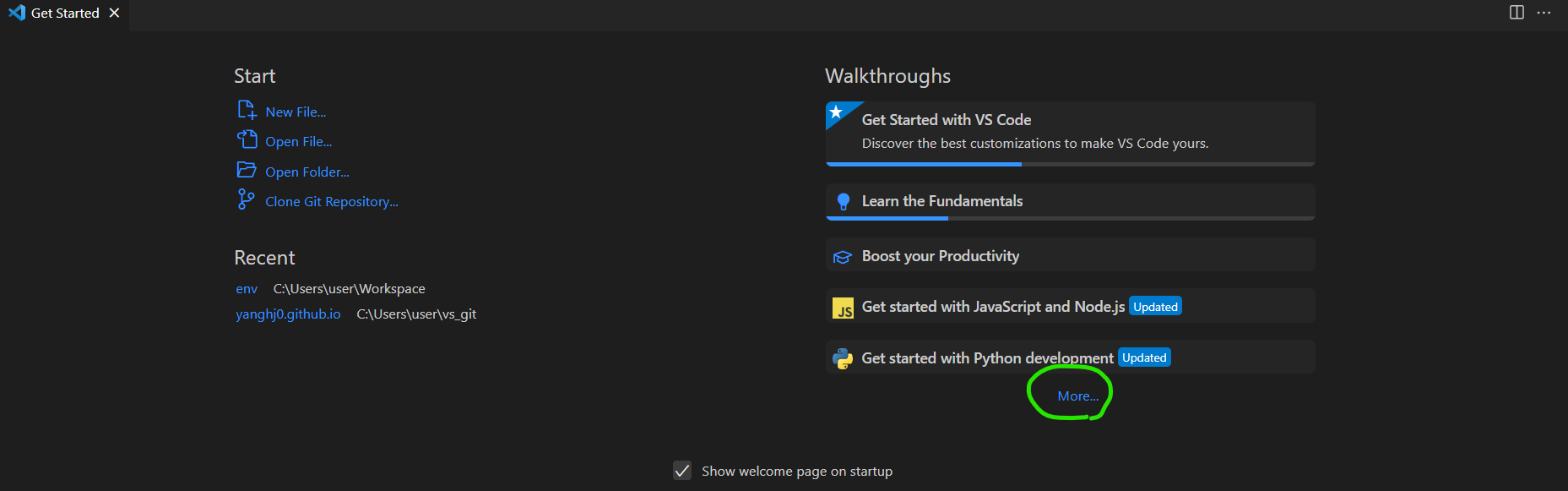
사진의 연두색 동그라미를 눌러 jupyer notebook이라고 검색하면 get started with jupyter notebook이 뜬다. 이는 주피터를 시작하는 방법을 알려주는 화면이다.
2) 주피터 노트북 생성
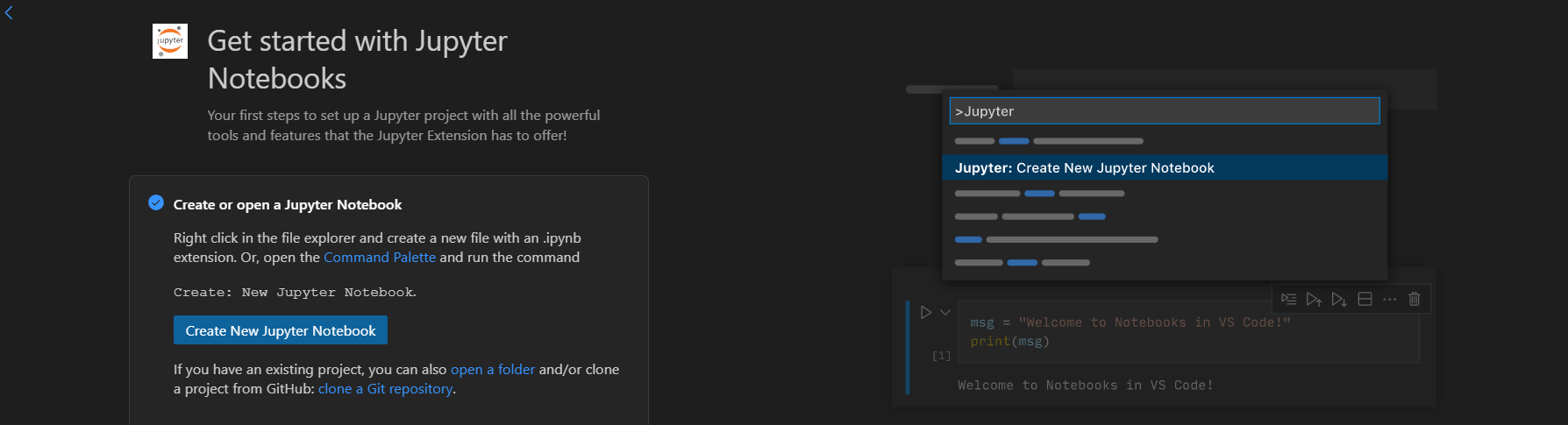
📍 화면 속의 파란글자인 command palette를 클릭해 jupyter notebook을 생성하거나
📍 상단의 view - command palette - jupyter notebook
📍 또는 ctrl+shift+p를 눌러 jupyter notebook을 입력해주면 된다.
실행하면 아래와 같이 창이 생기는 것을 확인할 수 있다!
주피터 생성완료!
3) 주피터 커널 선택
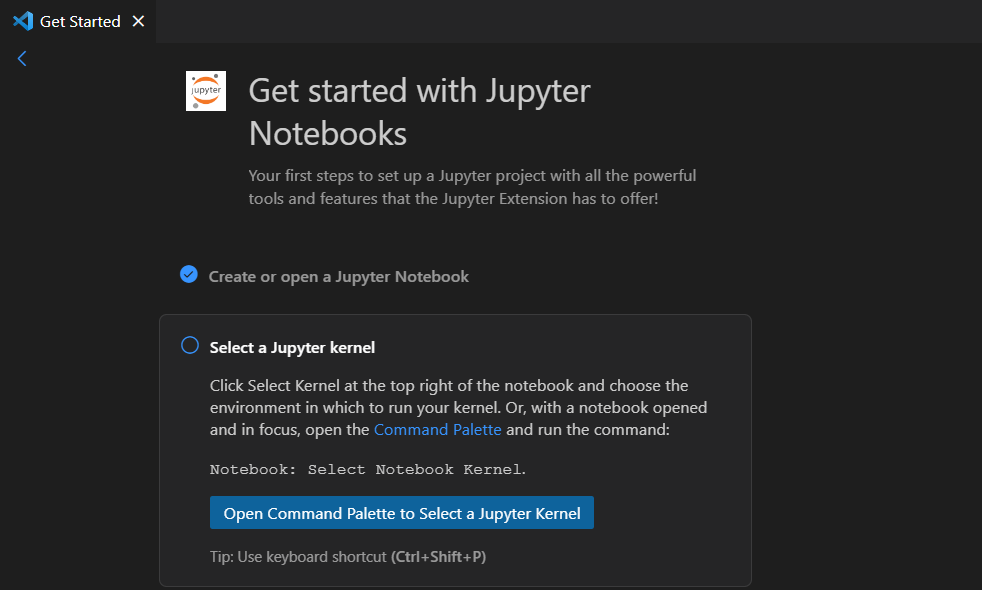
화면에서 설명하는 것 처럼 command palette에 들어가 notebook kernel이라고 입력하면
Notebook: Select Notebook Kernel이라고 뜬다. 이를 클릭해주면!
아무일도안일어나지만 암튼 눌러주라니까누름
🖐️여기서잠깐! 가상환경을 만들어주고 가자!
아래 사진을 보면 생성된 주피터 노트북이 python 글로벌 환경에서 돌아가는 것을 알 수 있다. 안전하게 가상환경을 만들어 그 안에서 실행하겠다!
(1) 터미널 열기
(2) 가상환경 생성
python -m venv env위 코드를 입력해 env라는 가상환경을 만들어준다.
(3) 환경 변경
사진 속 초록부분을 클릭해 방금 만든 가상환경인 env로 바꿔준다.
2. 실습- 타이타닉 셋
1) 데이터 셋 준비
실습은 다음 레퍼런스에 따라 진행해 보았다.
ref: https://code.visualstudio.com/docs/datascience/data-science-tutorial#_prepare-the-data
위 사이트인 visual studio code에서 제공하는 titanic set을 활용할 것이다. Prepare the data 목차로 가 OpenML.org를 클릭하면 다운받을 수 있다.
다운받은 파일을 economic에 옮겨주었다. 아래와 같이 파일이 열린다.
2) pandas, numpy 임포트
데이터 수집을 위해서는 pandas와 numpy를 임포트해주어야 한다.
(1) 주피터 노트북에 아래와 같이 입력한다. titanic.csv파일을 data라는 이름으로 읽는다는 코드이다.
import pandas as pd
import numpy as np
data = pd.read_csv('titanic3.csv')(2) 터미널에 pandas를 설치한다.
pip install pandasnumpy는 pandas를 설치하면 자동으로 설치되어 따로 코드를 입력해주지 않아도 된다.
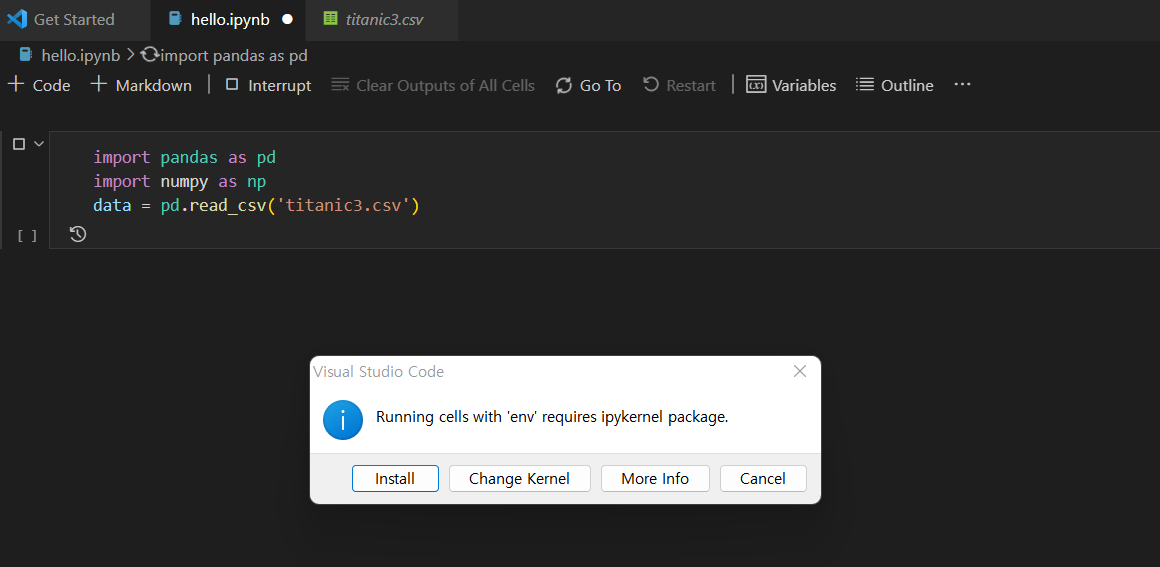
설치가 완료되어 코드를 실행시키면 다음과 같이 뜬다. jupyter extension을 위한 패키지 이다. install을 눌러 설치해주면 된다.
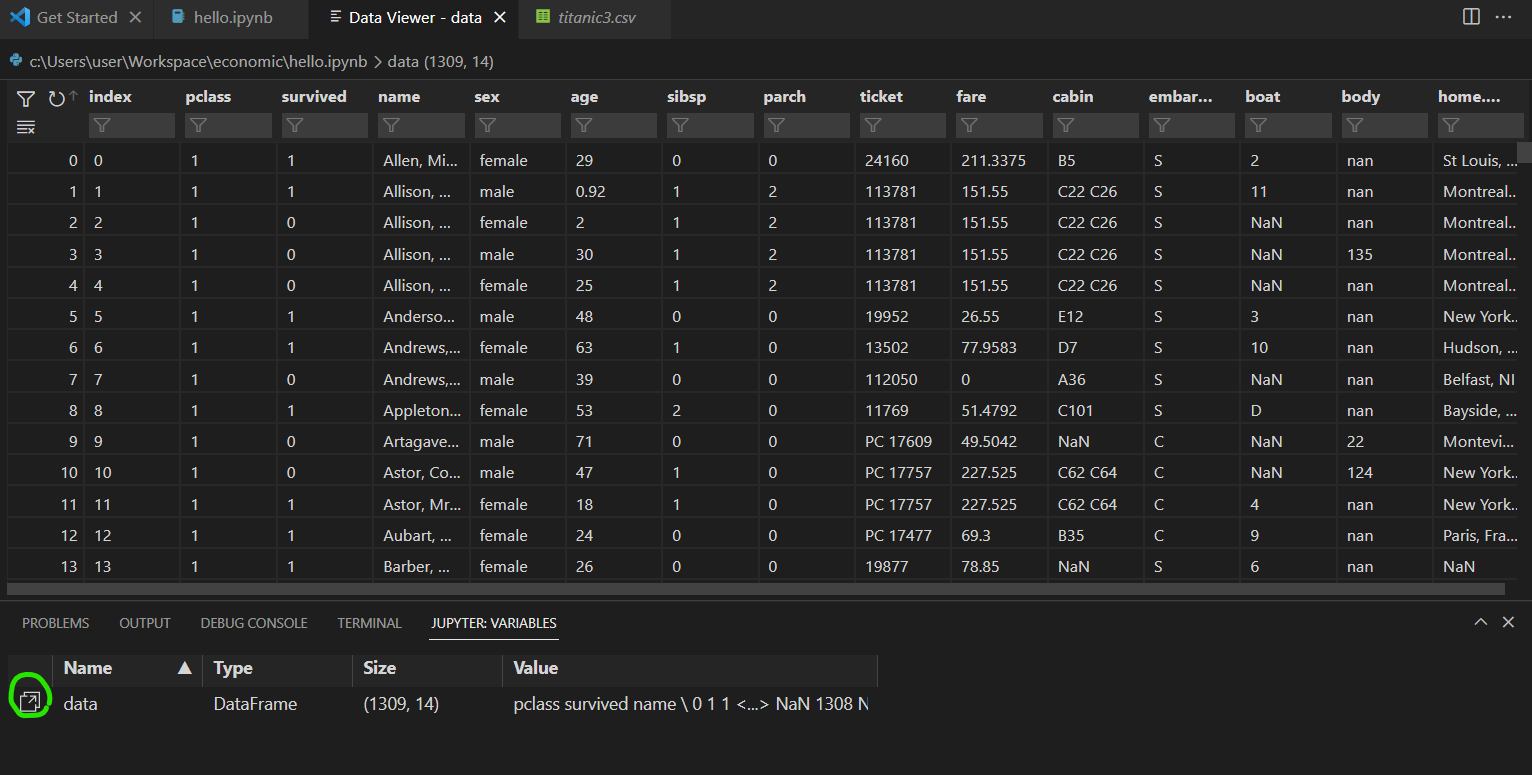
실행한 후, variables를 클릭하면 data의 정보를 볼 수 있다.
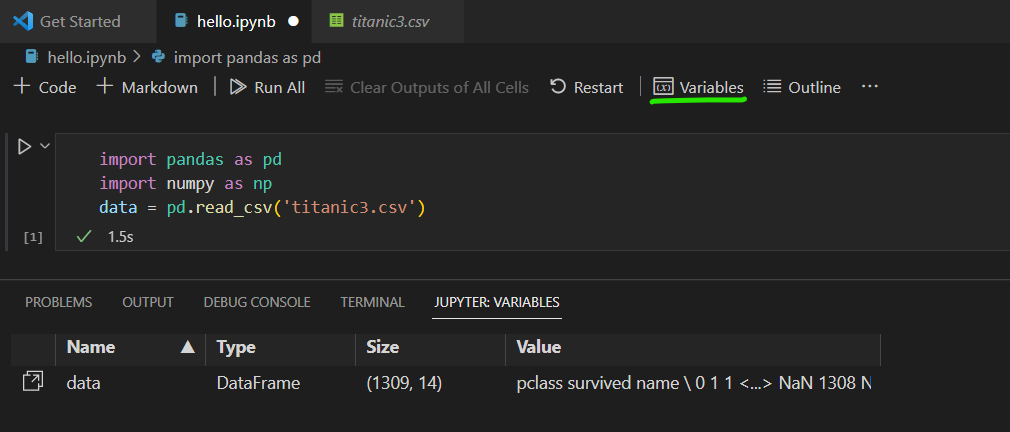
초록 동그라미를 눌러주면 상세 데이터를 보기편하게 확인할 수 있다.
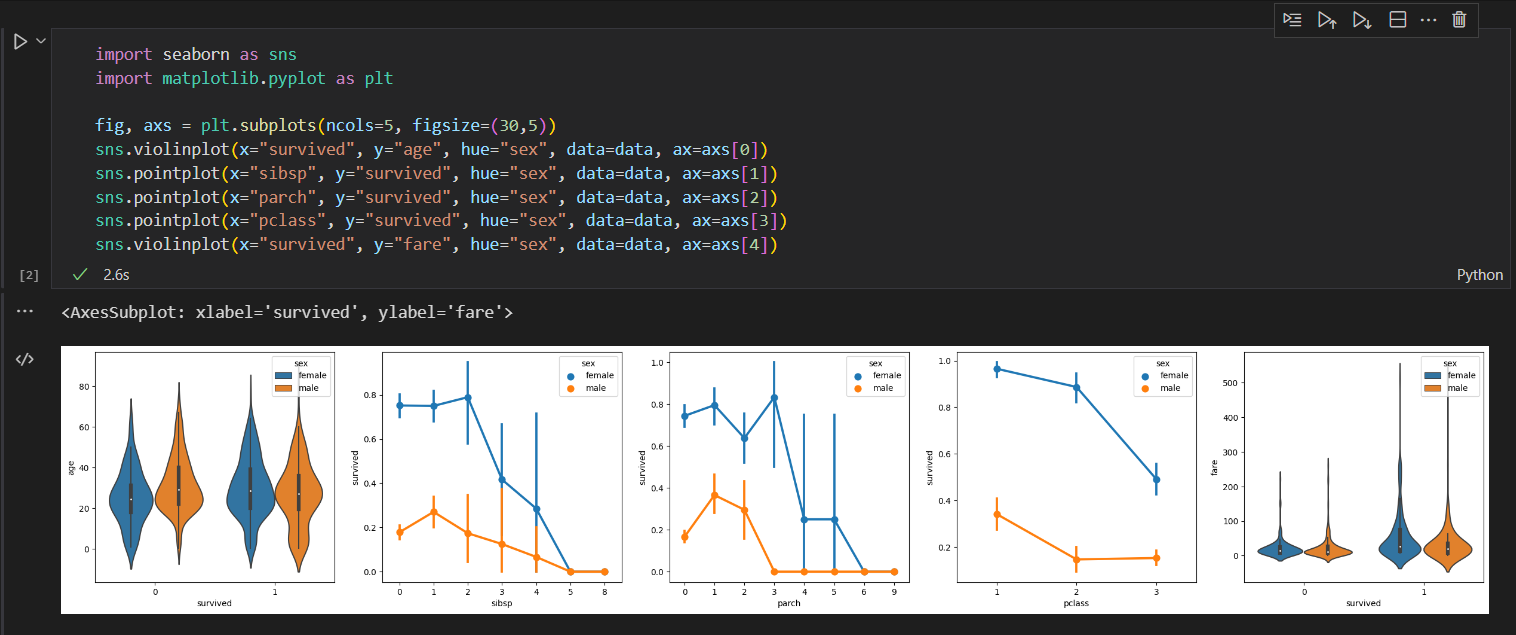
3) 데이터 시각화 - seaborn
표로 제시된 데이터를 보기 편하게 seaborn으로 시각화해보겠다.
코드는 아래와 같다. 데이터를 5가지 방법으로 나타내는 코드이다.
import seaborn as sns
import matplotlib.pyplot as plt
fig, axs = plt.subplots(ncols=5, figsize=(30,5))
sns.violinplot(x="survived", y="age", hue="sex", data=data, ax=axs[0])
sns.pointplot(x="sibsp", y="survived", hue="sex", data=data, ax=axs[1])
sns.pointplot(x="parch", y="survived", hue="sex", data=data, ax=axs[2])
sns.pointplot(x="pclass", y="survived", hue="sex", data=data, ax=axs[3])
sns.violinplot(x="survived", y="fare", hue="sex", data=data, ax=axs[4])당!연!히 설치되지 않은 seaborn 부분에 오류가 생길것이다.
터미널에 pip install seaborn 을 입력해 설치해준다.
설치 후 실행하면 아래와 같이 나온다!!
짱!!!!!!!!!!!!!!!!!!!!!!!!!
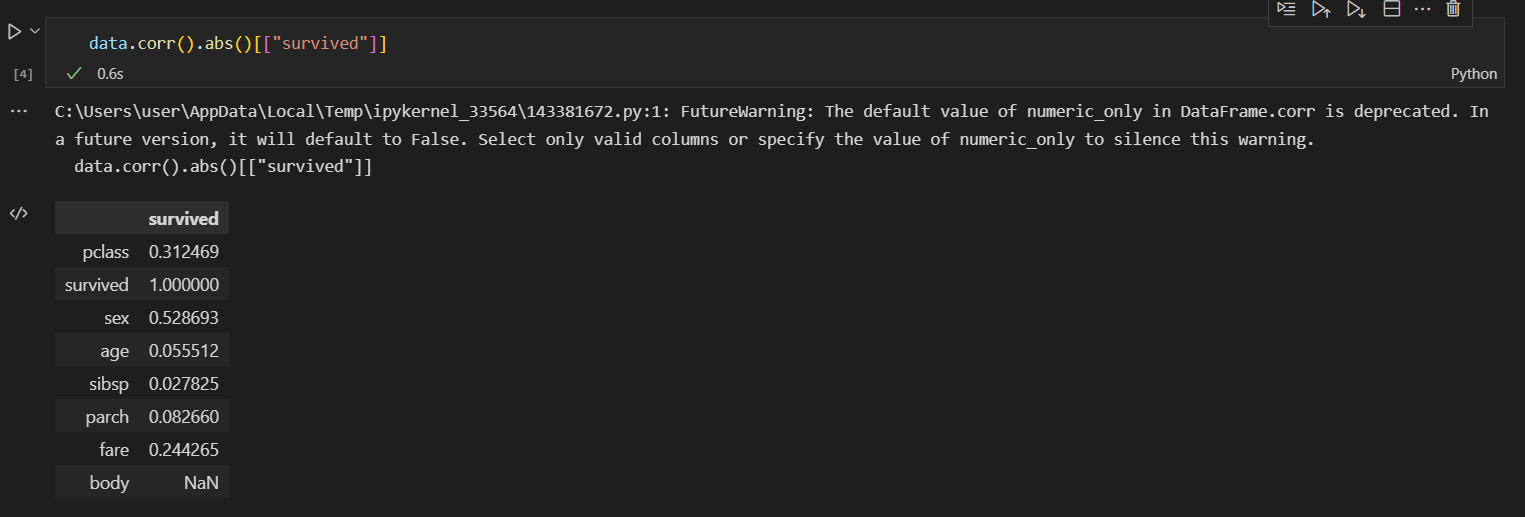
4) 값 대체
다음은 상관 분석을 위한 데이터 값 대체를 해보았다. male, female이라는 단어를 0과 1로 바꿔주면서 상관성 분석을 하려한다.
data.replace({'male': 1, 'female': 0}, inplace=True)5) 상관성 분석
아래는 상관분석 코드이다. 상관도에 따라 값이 나열되었다. 성별 - 나이 - 가족관계유무 등의 순으로 생존률이 높다는 것을 볼 수 있다.
data.corr().abs()[["survived"]]🔻실행 결과
6) 가정을 통한 분석
🤔타이타닉 호에 가족이 함께 탔을 경우(가족관계유무) 생존률이 높을까?
🤔서로 도와 탈출했으니 생존률이 높지 않을까?
라는 가정을 따로 변수로 만들어 상관분석을 다시 진행해보았다.
data['relatives'] = data.apply (lambda row: int((row['sibsp'] + row['parch']) > 0), axis=1)
data.corr().abs()[["survived"]]가족이 함께 탑승했을 경우 1, 그렇지 않을 경우를 1로 계산하였다.
🔻실행 결과
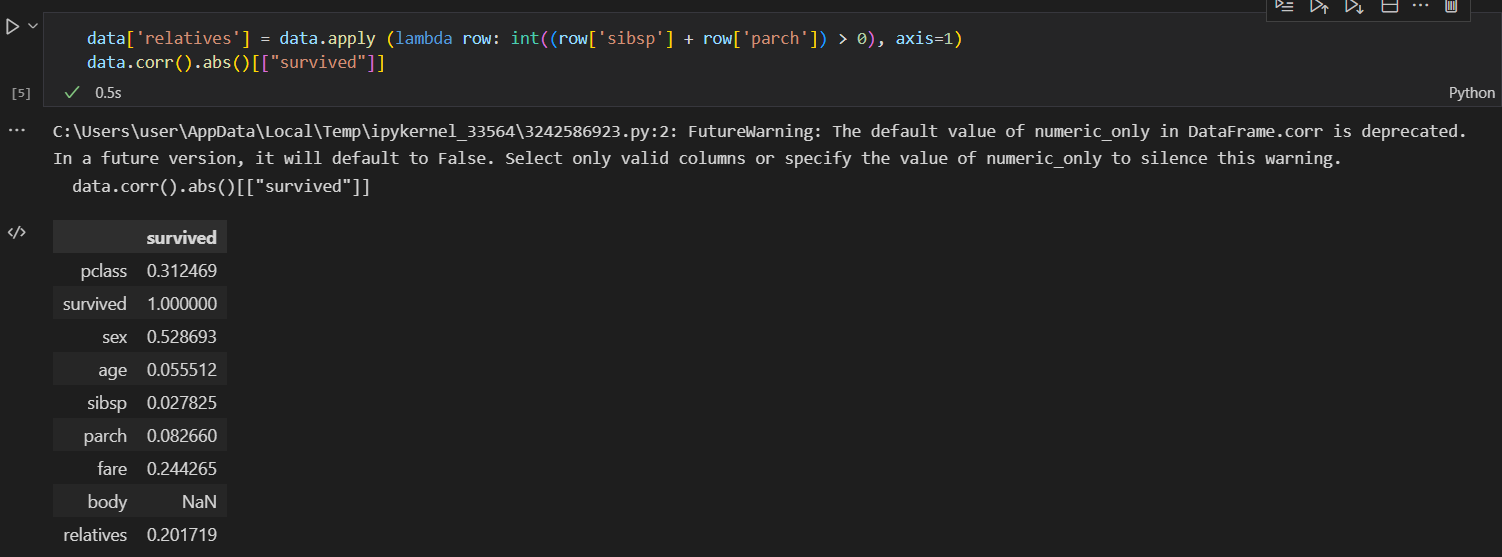
분석 결과, 가족의 유무가 fare보다 낮은 것을 확인할 수 있었다. fare은 지불한 요금을 의미한다. 가족 유무보다 높은 탑승료를 지불한 사람들이 생존률이 높음을 알 수 있다.
7) nan값 제거
마지막으로, nan 값을 제거하여 추후 훈련데이터로 사용할 시 오류가 나지 않게 하였다.
data = data[['sex', 'pclass','age','relatives','fare','survived']].dropna()ㄲ
