
2021년 2학기부터 2022년 1학기까지 약 1년간 진행했던 졸업프로젝트가 드디어 막을 내렸다.
학기중이건 방학이건 쉴틈없이 달려와서 그런지 막상 끝나니까 시원섭섭하다.
일년간 내가 겪었던 모든 문제 해결의 경험과 감정들을 다 기록해두지 않아서 잘 기억이 안 나지만 최대한 복기해보고자 한다.
🍊 About 코소롱
🏄🏻 간단 정리
Why - 졸업 프로젝트!
What - 소멸위기에 처한 사투리 보전을 위한 제주어 오디오북
Who - 콩쥐와 두꺼비팀(김민주, 이채은, 정수진, 진정현)
How - 기계학습과 음성합성을 통해 사투리 발화 모듈을 만든 뒤, 이를 서버와 연결함
When - 대략 1년 (2021년 09월 ~ 2022년 6월)
📖 프로젝트 설명
코소롱은 사용자로부터 표준어 텍스트를 입력 받고 이를 제주어 오디오북으로 변환하는 웹 서비스이다.
언어학적으로 중요한 의미를 지니는 제주어를 보전할 필요성을 알리고 제주어에 대한 흥미를 고취시키는 것을 목적으로 한다.
🏆 수상
이화여자대학교 컴퓨터공학전공 2022학년도 1학기 졸업프로젝트 우수상
🙋 나의 역할
내가 맡은 부분은 음성합성과 백엔드이다.
음성합성
제주어의 억양을 살려 발화하는 음성합성 모델
사용 기술
- Glow-TTS
- TensorFlow
- Google Colab
학습 데이터셋으로 kaggle에 공개되어있는 제주어 단일 화자의 발화 음성 오디오 1만개 문장을 사용했다.
이 13시간 47분 분량의 데이터를 Glow-TTS에 학습시켜 제주어의 억양을 살려 발화할 수 있도록 했다.
백엔드
Flask를 사용한 딥러닝 서버
사용 기술
- Flask
- Docker
- AWS EC2
기계학습 모델과 음성합성 모델을 Flask 서버에 올리고, 모델의 inference 결과를 API 서버(Django)에 넘겨주는 기능을 구현했다.
🏗 System Architecture

✌️ 결과물
제주어 번역 및 발화
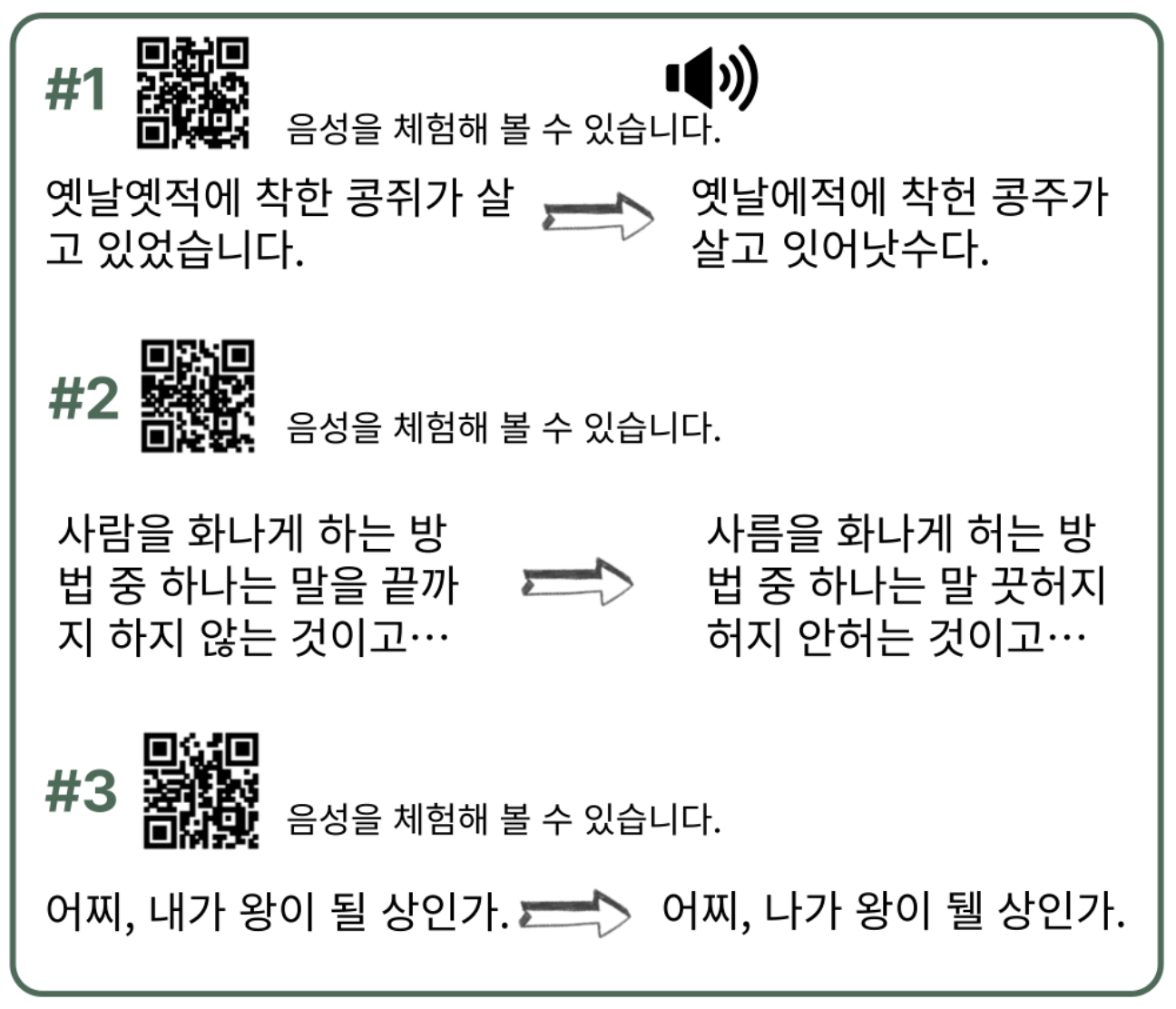
[Web] 오디오북 생성

[Web] 오디오북 조회

⏳ KPT 회고
🚀 Keep
-
해결되지 않는 문제를 포기하지 않고 끝까지 파고들었다.
- Problem 에서 언급하겠지만, 딥러닝과 관련한 문제를 아무리 찾아보아도 해결할 수 있는 레퍼런스를 찾아볼 수 없었다.
- 하지만 내가 담당한 부분이었기 때문에 교수님께도 여쭤보고, 비슷한 프로젝트를 했던 선배님께도 자문을 구하는 등 다양한 방법으로 힌트를 얻고자 노력했다.
- 대략 한 달 가량을 해당 문제를 해결하는 데에 쏟았다. 지금 생각하면 무식하게 정보를 찾아다닌 것 같기도하다.
- 그래도 이 때의 문제를 해결한 기억으로부터 어떤 오류를 만나도 내가 좀만 더 노력하면 해결할 수 있을 것 같은 자신감을 갖게되었다.
-
뭐든지 할 수 있다는 마음가짐 장착!
- 딥러닝을 프로젝트에 사용하기로 했을 때, 정말 눈 앞이 캄캄했다. 팀원 중 아무도 딥러닝을 사용해본 적이 없었기 때문이다.
- 프로젝트 초반은 거의 딥러닝 스터디처럼 진행되었다. 머신러닝의 기초와 음성에 대한 강의를 찾아들었고, 그 후에는 실습 위주의 학습을 통해서 점차 몸에 익숙해지기 시작했다.
- 대략 한 달 가량을 딥러닝에 시달리고 나니, 내가 사용해야하는 데이터를 가지고 응용해보고싶은 욕심이 생겼다! 이 과정에서 물론 수백만개의 오류를 만나고 해결해야했지만, 그 과정을 반복하고나니 난 딥러닝을 이용해서 서비스를 만들어낸 인간이 되어있었다.
- 아무리 어려운 기술라고 하더라도 배우고자하는 욕망이 있고, 시간을 들여서 빡세게 공부하면 못 할 것이 없다!
-
2주마다 보고서를 작성했다.
- 필수 제출물이어서 억지로 작성하곤 했다..
- 하지만 되돌아보니 자주 보고서를 작성하면서 팀원들과 프로젝트의 방향성에 대해서 계속해서 생각해볼 수 있었다.
- 또, 전체 프로젝트의 흐름 중 현재 위치한 지점을 파악하고 가장 필요한 작업들을 계획하고 실행하는 데에 큰 도움을 준 것 같다.
- 단기 목표를 세우고 쭉 달린 다음에, 팀원들과 함께 회고하는 시간을 갖는 것!
🚨 Problem
-
기계번역과 음성합성 모델을 딥러닝 서버에 어떻게 올리는거지?
- colab에서 학습시킨 모델을 어떻게 Flask에서 사용할 수 있는지 전혀 몰랐다. 감도 안 왔다.
-
거대한 딥러닝 서버를 배포할 수 있을까?
- 딥러닝 서버 내에 있는 파일들을 빠짐없이 EC2에 올릴 수 있는 방법을 찾아헤맸다.
💡 Try
-
기계번역과 음성합성 모델을 딥러닝 서버에 올리기
- 구글, 비슷한 플젝을 한 선배님 등 다양한 방법으로 정보를 찾은 결과, 아주 간단하게도 모델이 inference 하는 데에 필요한 환경만 만들어주면 된다는 사실을 알게 되었다.
- 도커로 모델이 추론하는 데에 필요한 모듈들을 받고, colab 환경에서 사용했던 infer 코드와 체크포인트를 서버에 올렸다.
- infer 코드를 메소드화 시켜서, flask의 server.py에서 해당 메소드를 호출하는 방식으로 구현했다.
- 서버를 돌려보니 실제로 번역과 음성합성이 되어서(당연하지만..) 너무 감격스러웠지만, 모든 모듈을 다 내려받는 형태로 구성되어서 딥러닝 서버가 아주아주 무거워지게 되었다.
-
거대한 딥러닝 서버를 배포하기
- 위에서 설명한 일련의 과정으로 딥러닝 서버는 굉장히 무거워지게 되었다.
- AWS EC2로 배포를 하고자했다.
- 그런데 문제는 EC2 내부에서 github에 있는 딥러닝 레포지토리를 clone해서 배포하려고 했는데, 서버 내에 있는 갖가지 파일들이 용량이 커서 github에 업로드되지 않았다.
- 이 문제를 LFS로 해결한 뒤에 EC2에서 flask를 띄워봤는데 또또또 오류가 났다.
- 다시 천천히 깃허브에 업로드된 파일 목록을 보니 LFS로 올라가지 않는 파일들이 있었다. ex) 체크포인트
- 이쯤에서 살짝 넋이 나간 상태였다. 어떻게 해야 모든 파일을 빠짐없이 업로드할 수 있을지 고민하던 찰나에 codedeploy를 이용한 배포 아키텍처를 보게되었다. 이 아키텍처에는 s3에 jar파일을 업로드하고 서버 내에서 다운받아 사용하는 방식을 사용했었다.
- 이 아키텍처에서 힌트를 얻어 프로젝트 자체를 zip파일로 업로드하는 방법을 시도해보았다.
- 좀 무식한 방법 같지만 바로 성공했고!!! 이 방식으로 배포를 하게되었다.
💬 느낀점
딥러닝 서버를 배포하고 API 서버에서 정상적으로 리스폰스를 받았을 때 플젝실에서 다같이 소리질렀던 기억이 잊히질 않는다.
낯선 기술과 도메인 속에서 좌절을 기본값으로 개발했었지만, 내 결과물의 작동이 성공했을 때의 짜릿함(?)으로 모든 노력이 다 보상받는 기분이었다.
이 맛에 삽질하는 것 같다.
또 신기했던 기억은 프로젝트 포스터를 만들면서 교수님과 면담했을 때의 일이다.
우리 팀은 모두 개발자로 이루어져있어서인지 포스터 내용이 90프로는 내부 구현에 관련된 내용이었다.
하지만 교수님께서 이런 포스터 세션이나 발표를 할 때에는 개발한 제품을 사용하고싶게 만드는 것이 우선이고, 그 다음이 기술에 대한 설명이라고 피드백해주셨다.
그저 제품을 만들어내는 과정에 몰두하다보니 정작 내가 만들어낸 제품의 목적성을 간과한 것이었다.
이 피드백을 계기로 서비스에 있어서 기획, 마케팅의 중요성을 깨닫게 되었고, 내가 개발하는 기능이 실제 제품에서 어떠한 목적을 가지고 작동하는지를 생각하면서 작업을 하게되었다.
이번 기수 졸업프로젝트는 팀이 거의 40개로 많아서 수상을 기대하지는 않았지만 우수상이라는 좋은 성과를 얻어서 더욱 뿌듯했다!
수고했다 나 자신!
