본 글은 https://tacademy.skplanet.com/live/player/onlineLectureDetail.action?seq=123 를 참조하여 공부해서 정리한 글이다.
자연어 처리 소개
우리는 무엇을 위해 자연어 처리를 할까?
자연어로 만들어진 모든 데이터에 대해 이해하고 답하기 위함이다.
답하기에 해당하는 검색, 추론, 분류 등은 과거부터 발전해왔으나 이해에 포함되는 문서, 발화, 질문 이해 등은 최근 빠르게 발전하고 있는 추세이다.
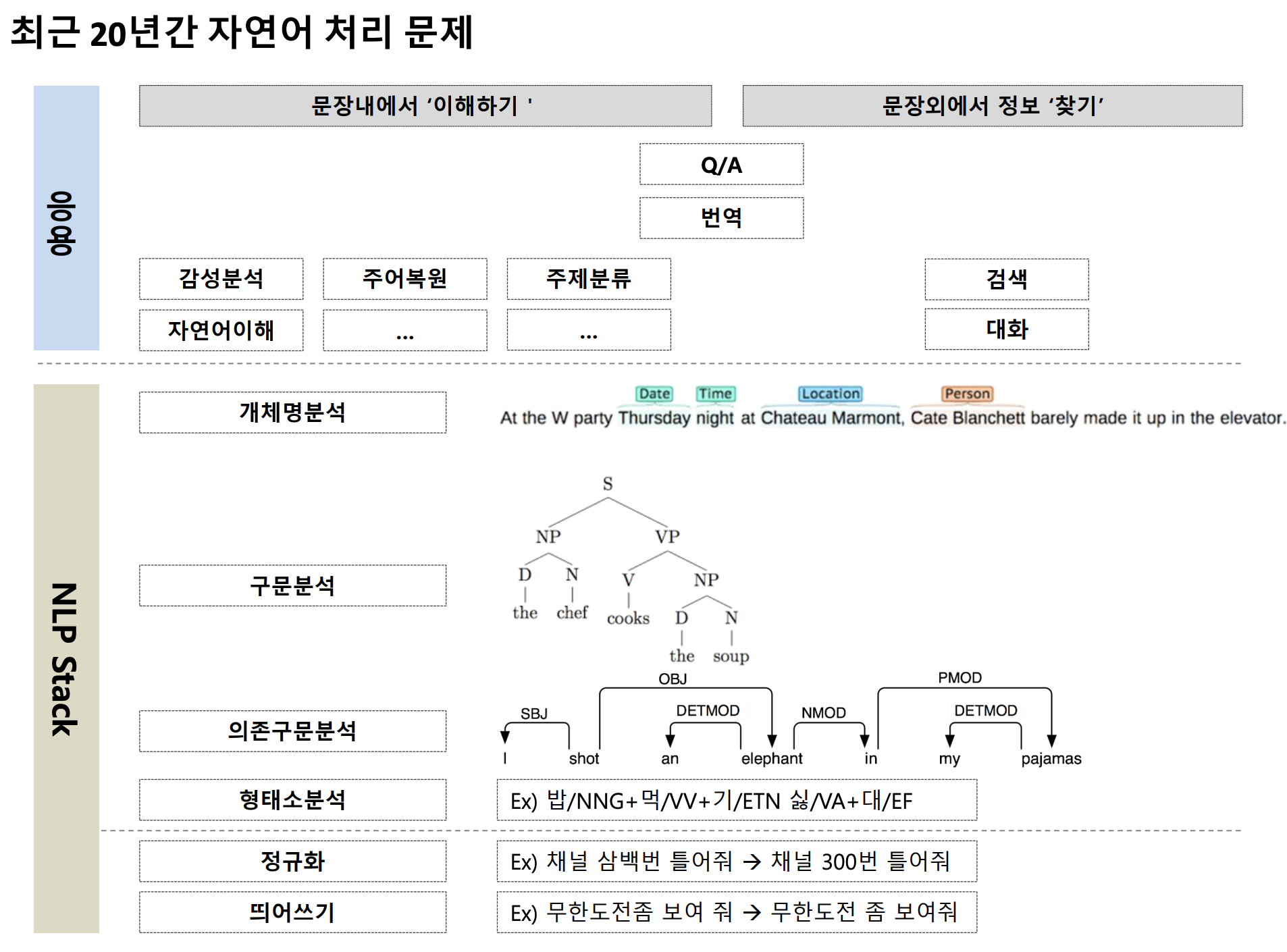
이 강의에서는 '이해하기'에 해당하는 감정분석과 '찾기'의 대화, 그리고 NLP Stack 최상단에 위치한 개체명분석을 다룬다.
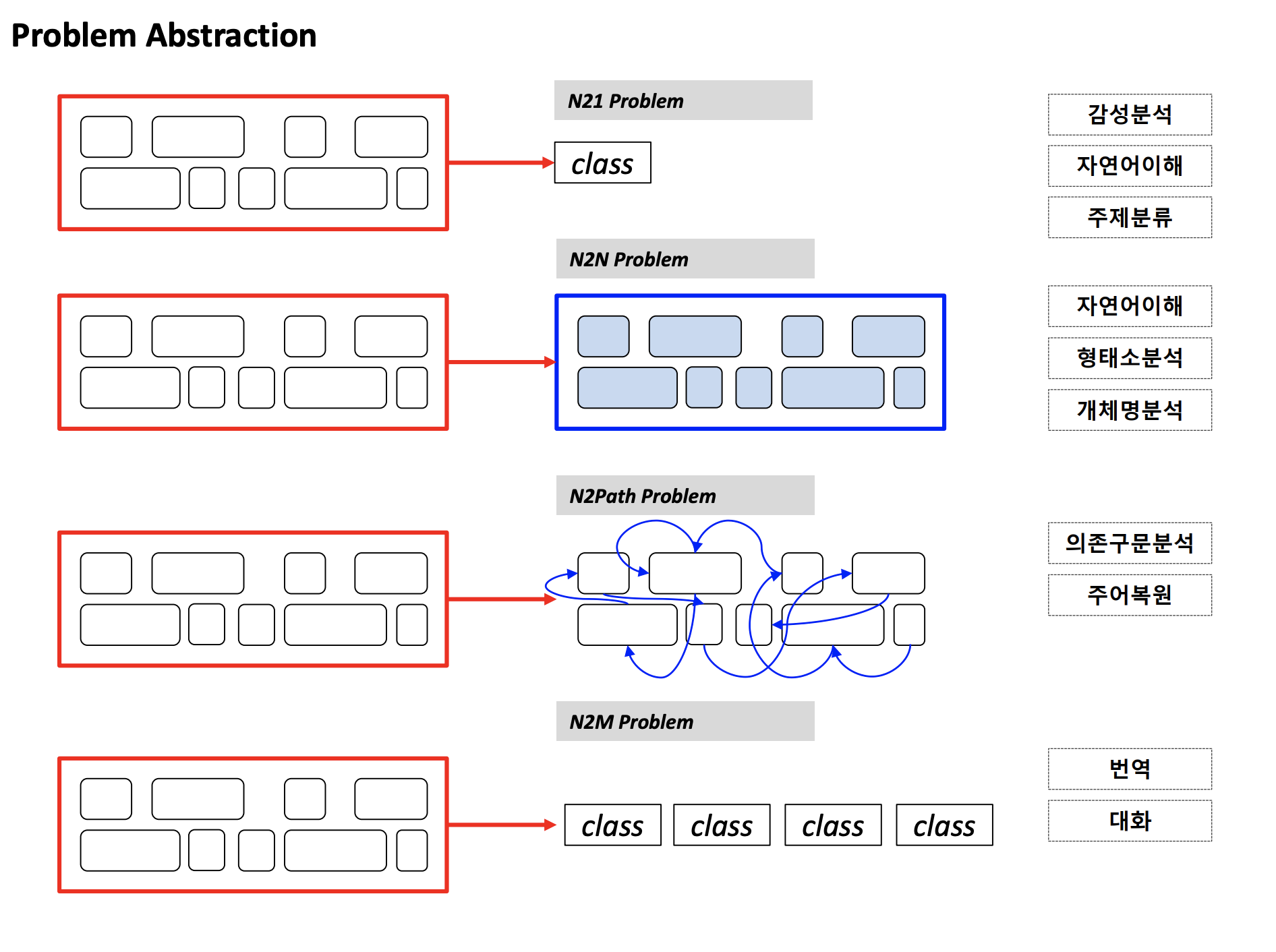
자연어 처리 문제는 보통 위의 4가지 중 하나로 분류된다.
1. N21 Problem
input으로 여러 개의 토큰이 들어올 때, 1개의 답이 나온다.
2. N2N Problem
여러 개의 토큰을 보면서 이에 대응하는 결과를 도출한다.
3. N2Path Problem
여러 개의 토큰을 보고 토큰 간의 관계를 도출한다.
4. N2M Problem
N개의 토큰이 input으로 들어올 때, M개의 답이 나온다.
Machine Learning Review
우리는 인공지능 문제를 어떻게 풀어나갈 것인가?
데이터 응용 문제를 다룰 것이기 때문에 Classification 문제로 바라볼 것이다.
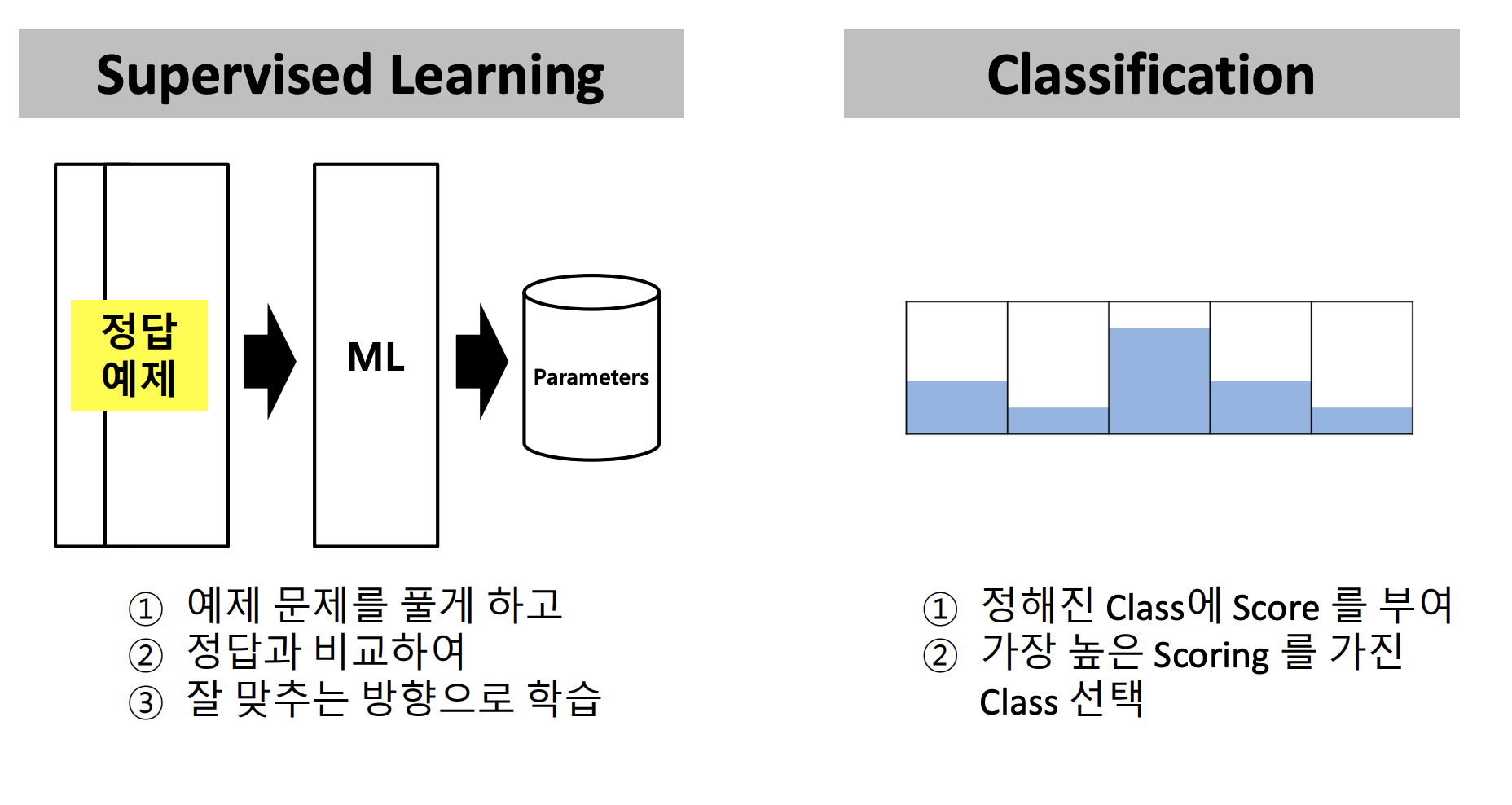
기계에 Supervised Learning을 시키면 오른쪽과 같은 5지선다를 만들어낼 수 있고, 이를 바탕으로 Score를 부여하여 정답을 도출해낸다.
예제로 다음과 같은 리뷰에 대해 감성 분석을 해보자.
▪ 다음에 또 가려 구요!
▪ 이게 좀 비좁은 느낌을 가져다 줄지도!
▪ 역시나 비싼 호텔인가 싶었어요.
▪ 무료 Wi-Fi
먼저 모든 이해관계자들이 모여 class를 설계해야한다.
아래는 각 리뷰 순서대로 나타낼 수 있는 Class이다.
▪ 다음에 또 가려 구요! ✓ Positive
▪ 이게 좀 비좁은 느낌을 가져다 줄지도! ✓ Negative
▪ 역시나 비싼 호텔인가 싶었어요. ✓ Neutral
▪ 무료 Wi-Fi ✓ Objective
그 뒤 Network를 구성하고, 입력을 받아 Class 별로 Scoring을 한다.
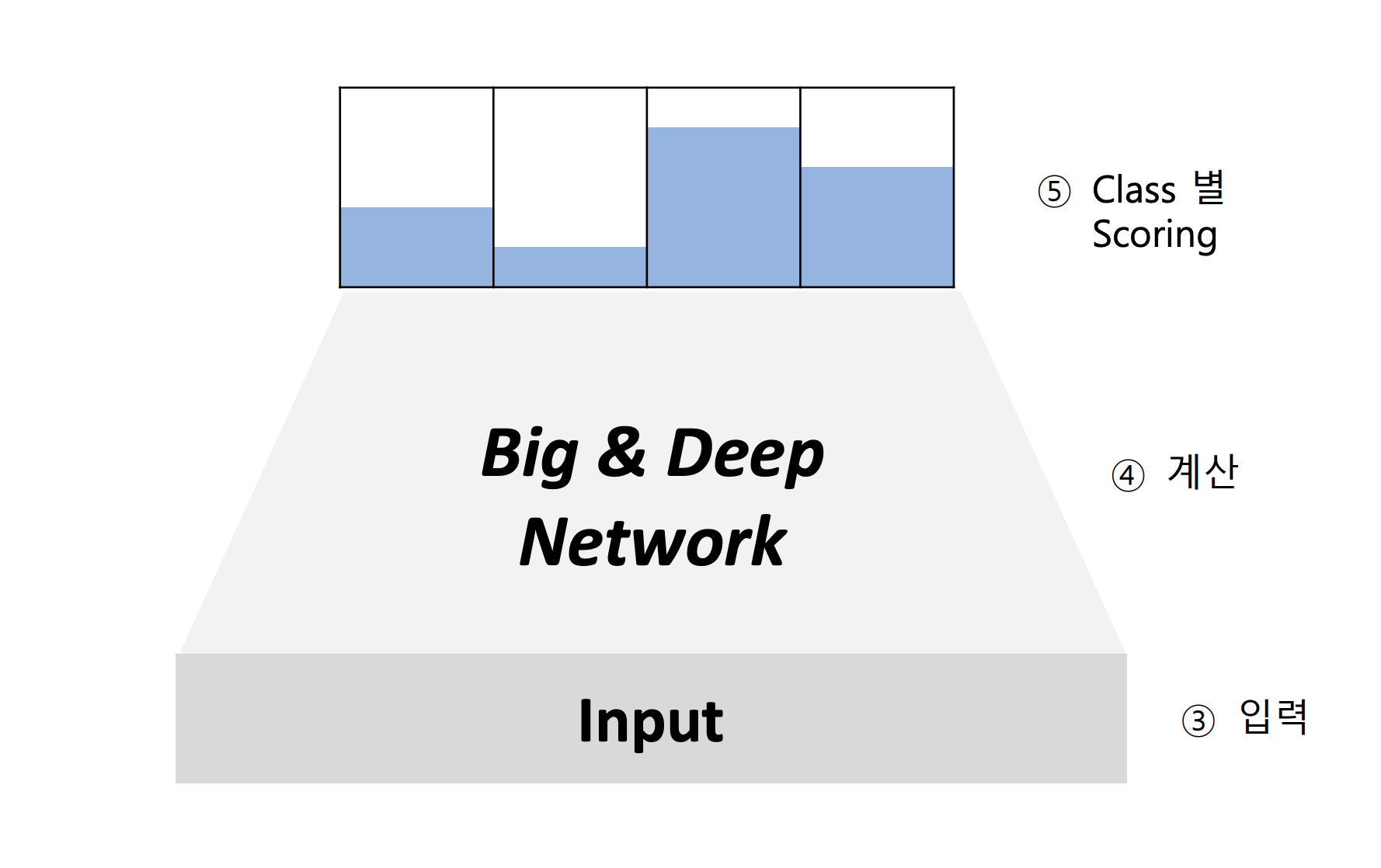
Scoring
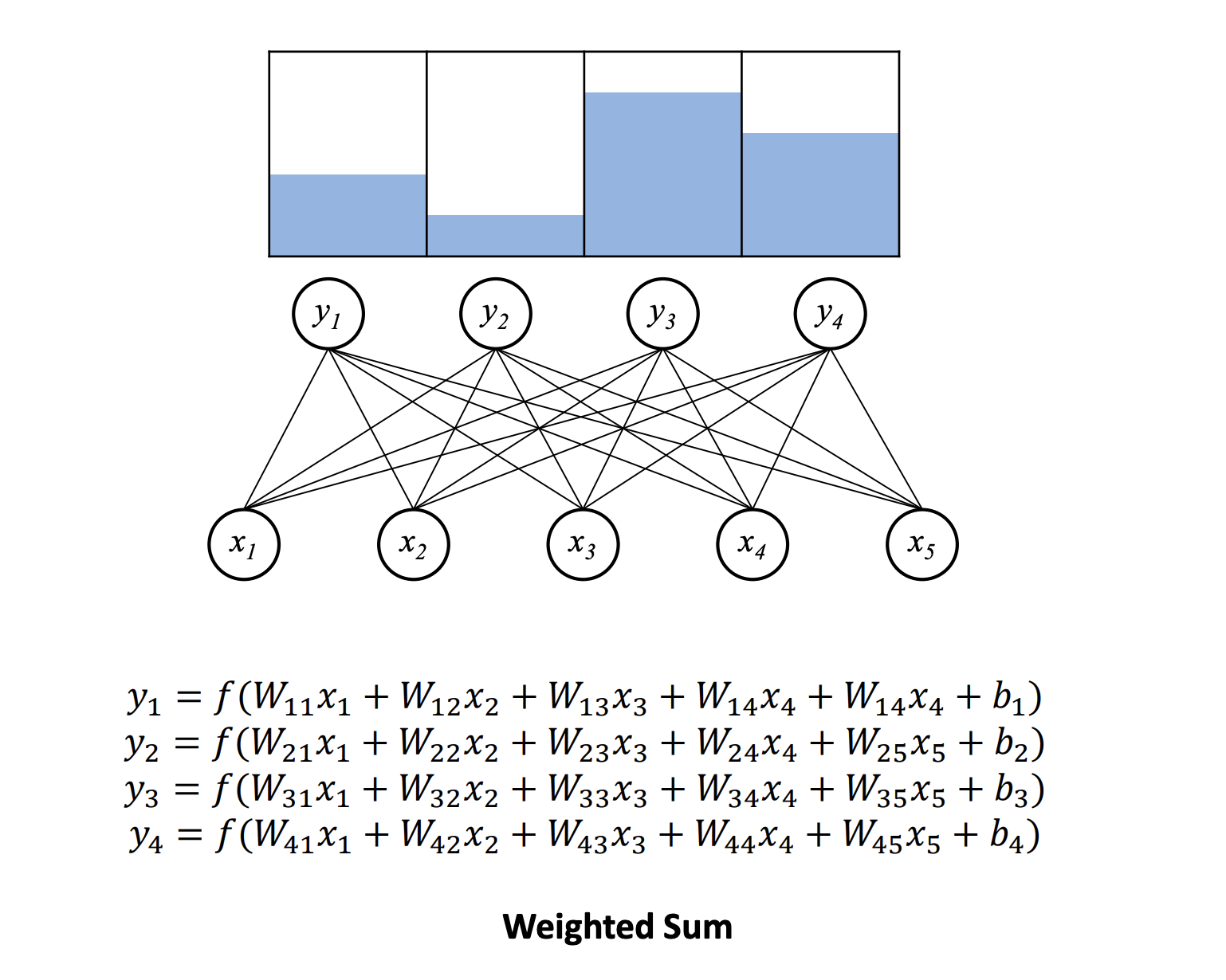
숫자 형태로 표현된 입력값들이 fully connected 형태로 계산된다.
그렇다면 어떻게 정답을 맞추는 방향으로 학습시킬 수 있을까?
이에 대한 답을 도출하기 위해서는 먼저 4가지를 정의해야한다.
- Reference Representation
- Scoring Normalization
- Cost Function Design
- Parameter Update
1. Reference Representation
정답을 표현하는 방법이다.
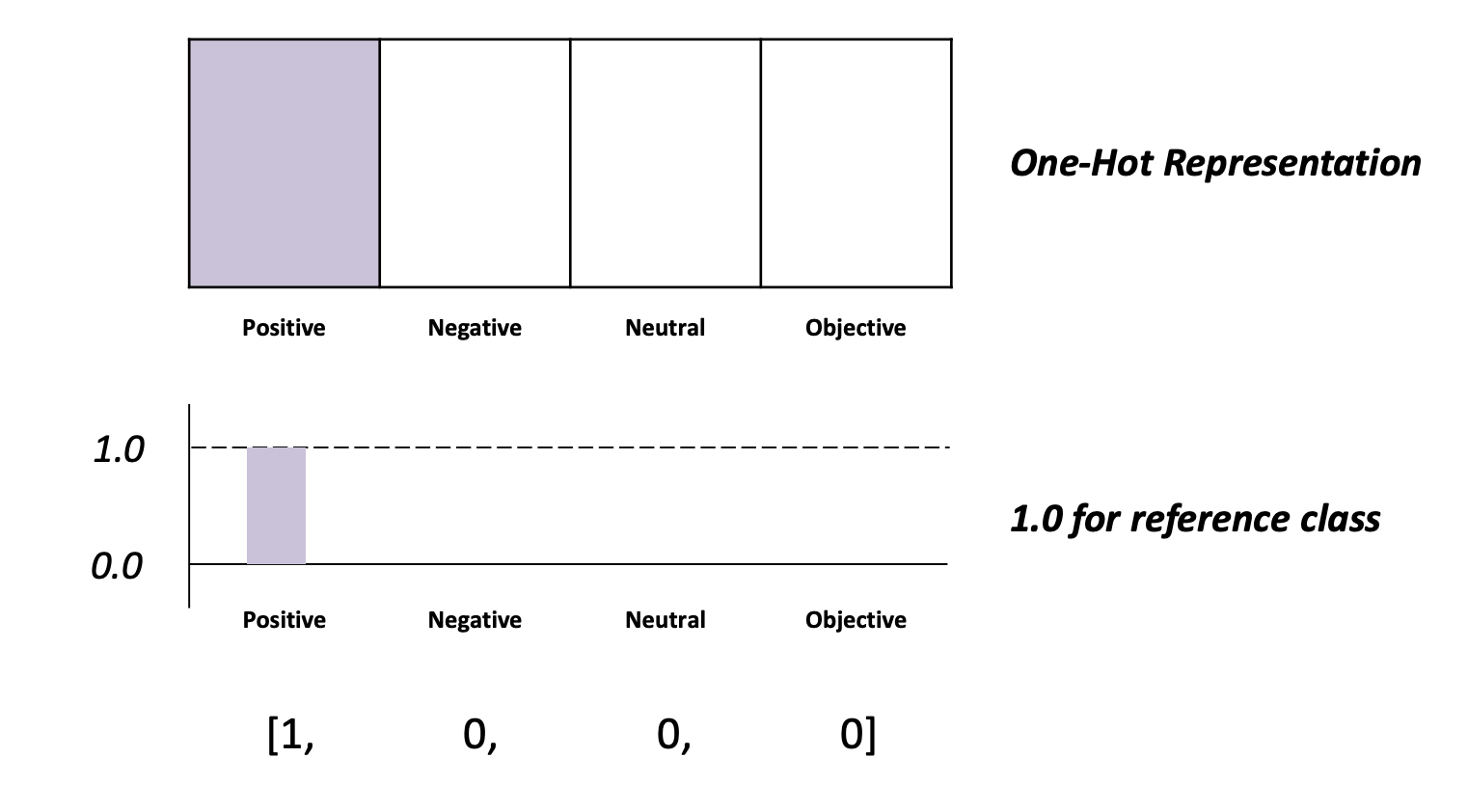
One-Hot Representation : 한 class에 몰빵한다.
1.0 for reference class : 수치는 1.0으로 한다.
2. Scoring Normalization
예측값과 정답값을 비교하기 위해서 scale 값을 맞출 필요가 있다. 이 때 필요한 것이 softmax함수이다.
softmax 함수
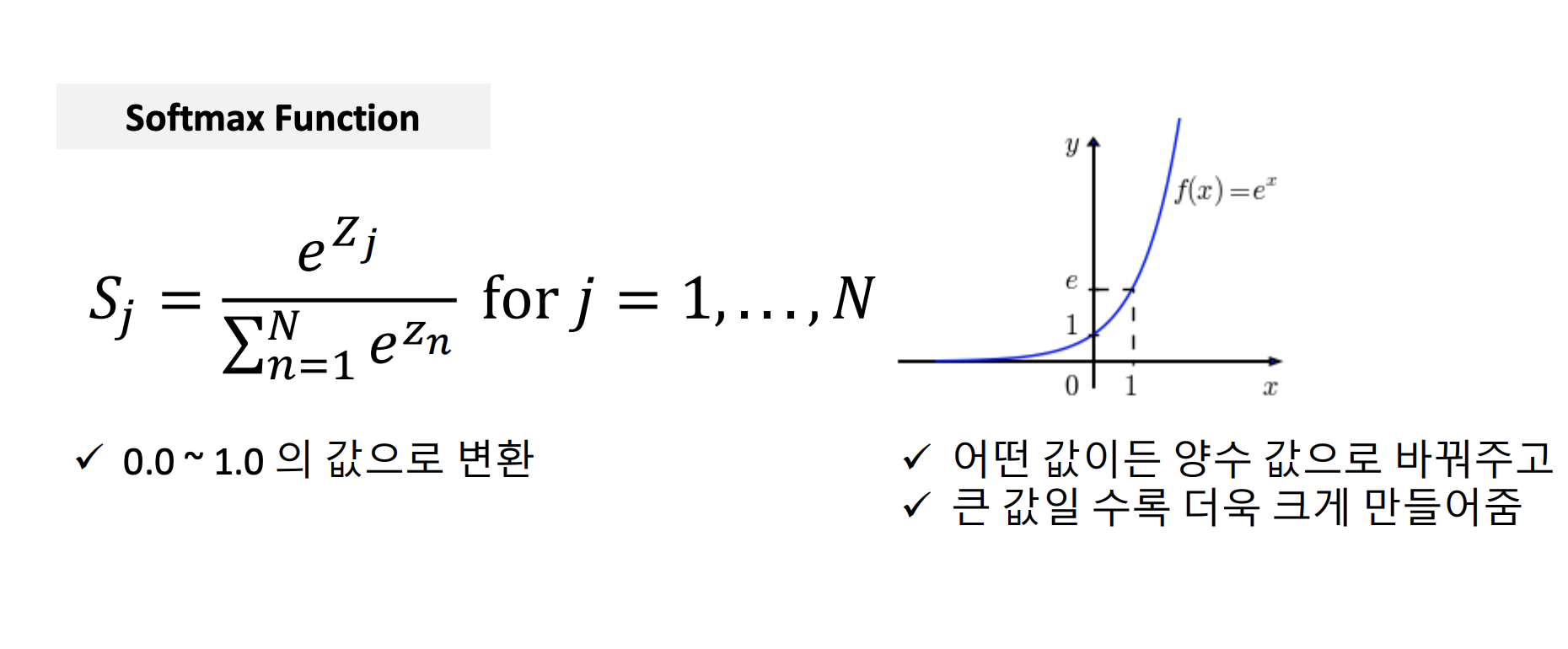
3. Cost Function Design
예측값과 정답값을 사이의 차이를 수치화하기 위해서 Cross Entropy를 사용한다.
Cross Entropy

잘 모르겠다...
4. Parameter Update
오류가 작아지는 방향으로 학습을 진행해야 한다.
그렇다면 오류가 작아지는 방향은 어느 쪽이며, 얼마나 고쳐야 오류를 작아지게 할 수 있을까?
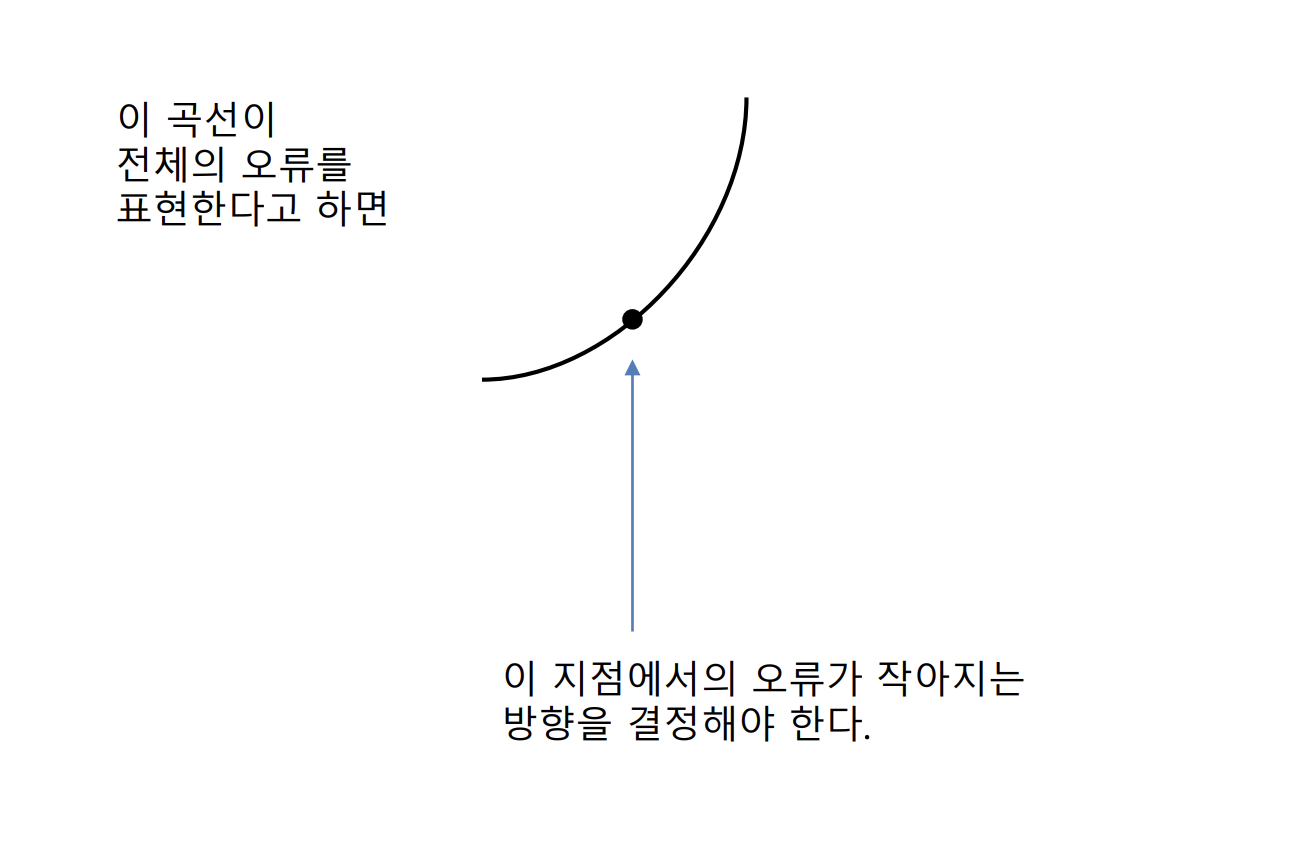
이 지점에서의 기울기 방향을 구해서, 기울기가 작아지는 방향으로 간다면, 오류를 작게 할 수 있을 것이다.
Gradient Descent
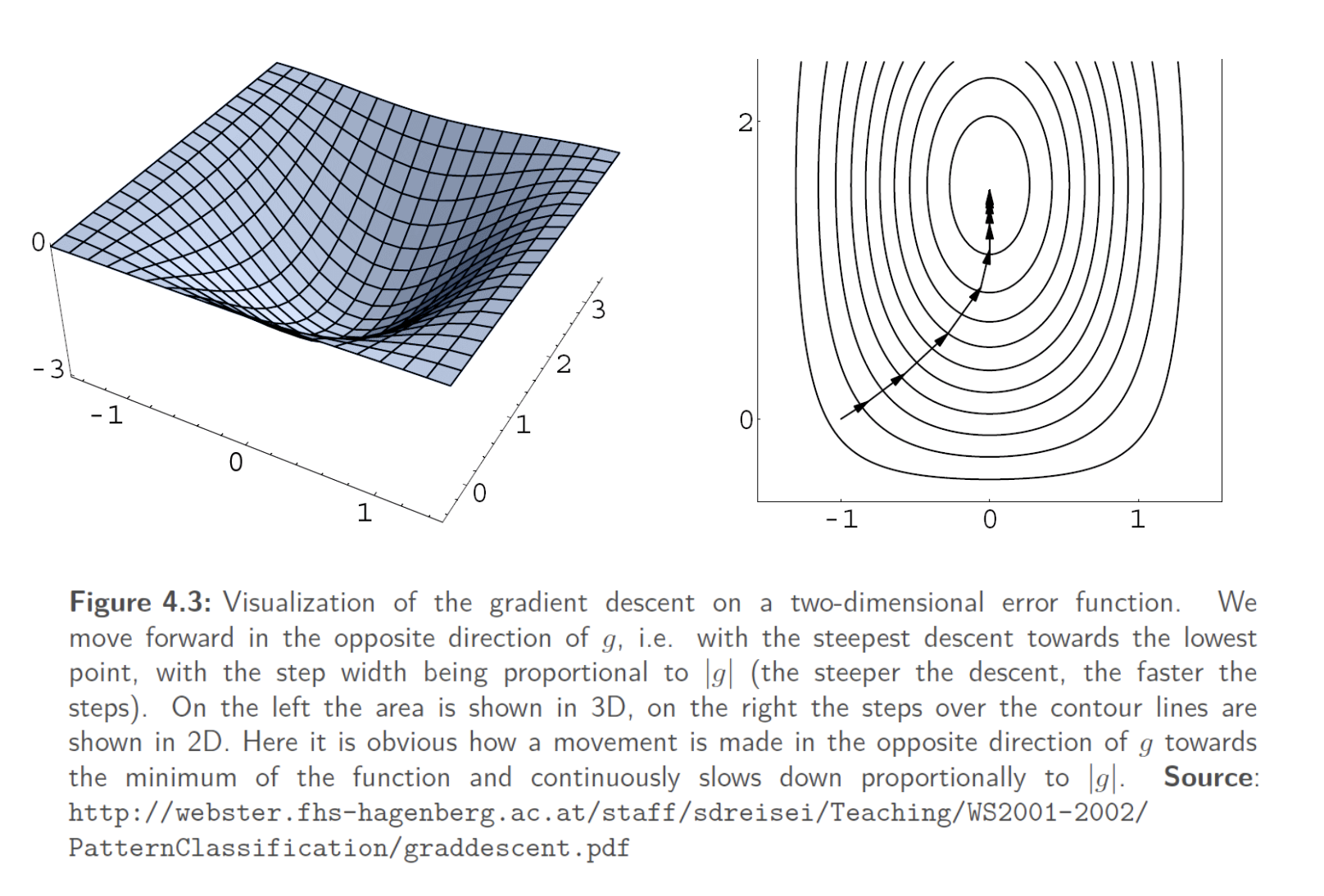
위치를 계속해서 바꿔가며 global minimum 혹은 local minimum까지 도달하도록 한다.
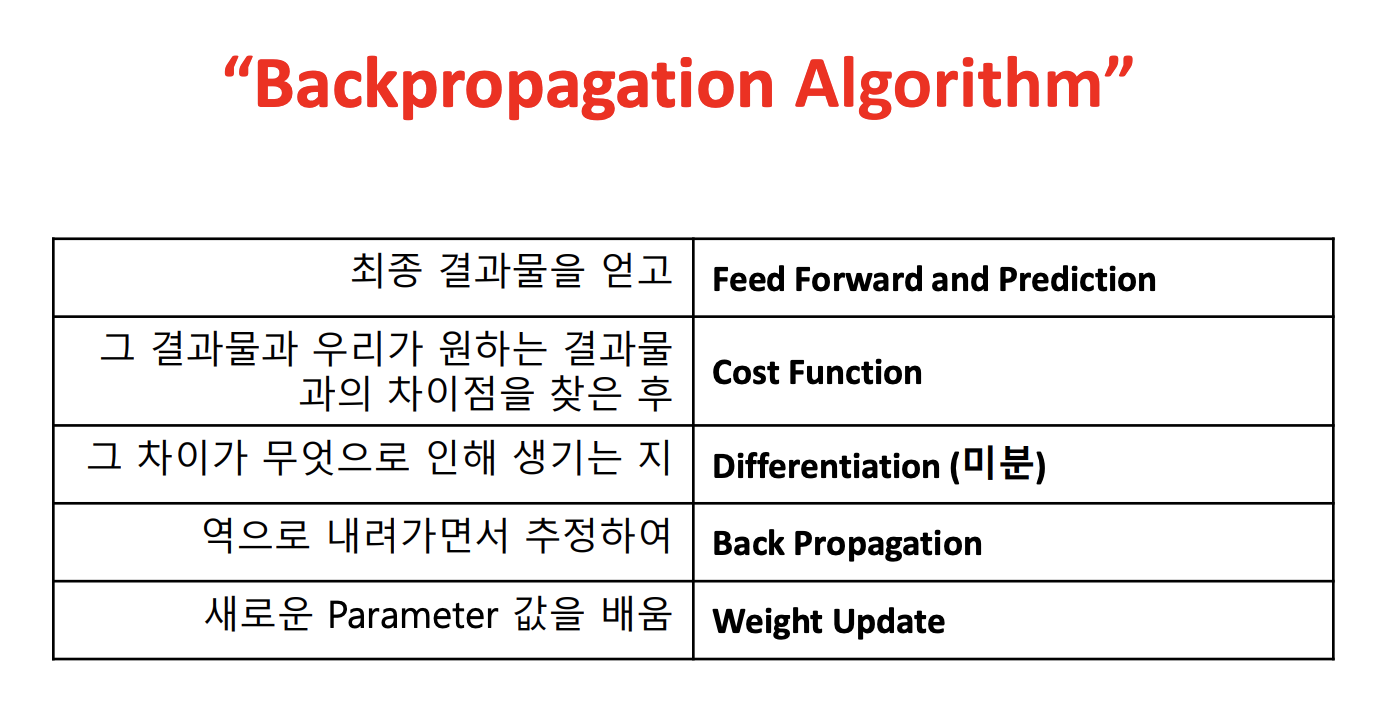
몇 개의 Example을 살펴보고, model을 update할 것인가?
Parameter Update를 한 번 한다는 것은 선을 다시 한 번 새로 긋는 것과 같다.
이 선이 모든 점에 잘 적용되도록 해야한다.
- 배치사이즈는 모든 점에 잘 적용되는 값이다.
보통 50 ~ 128 사이의 배치사이즈를 사용한다.
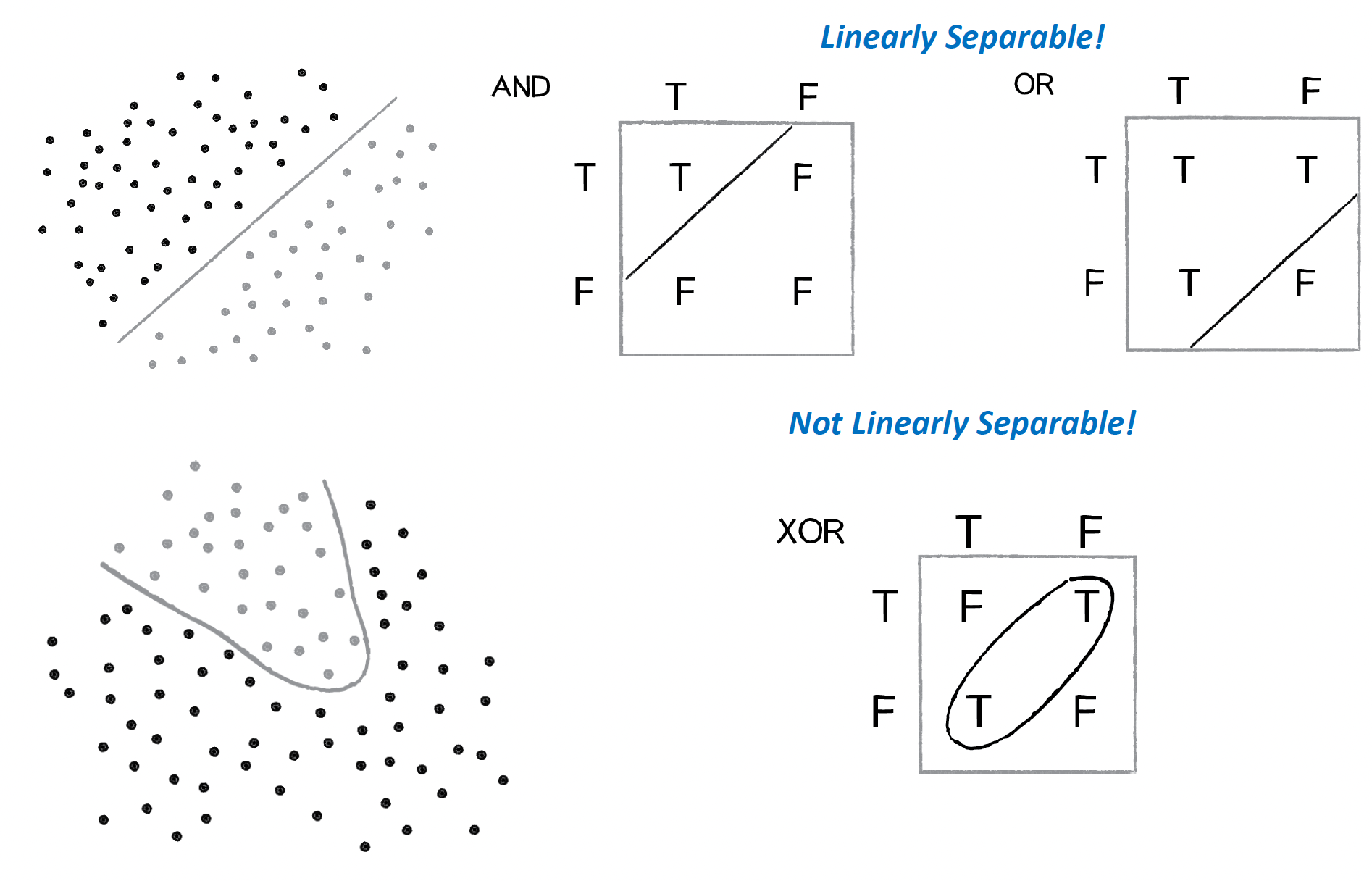
선을 긋는 Linear 문제는 AND나 OR문제는 잘 풀 수 있지만 XOR 문제를 해결할 수 없다.
따라서 다음과 같이 Multiple Layer를 만들어야한다.
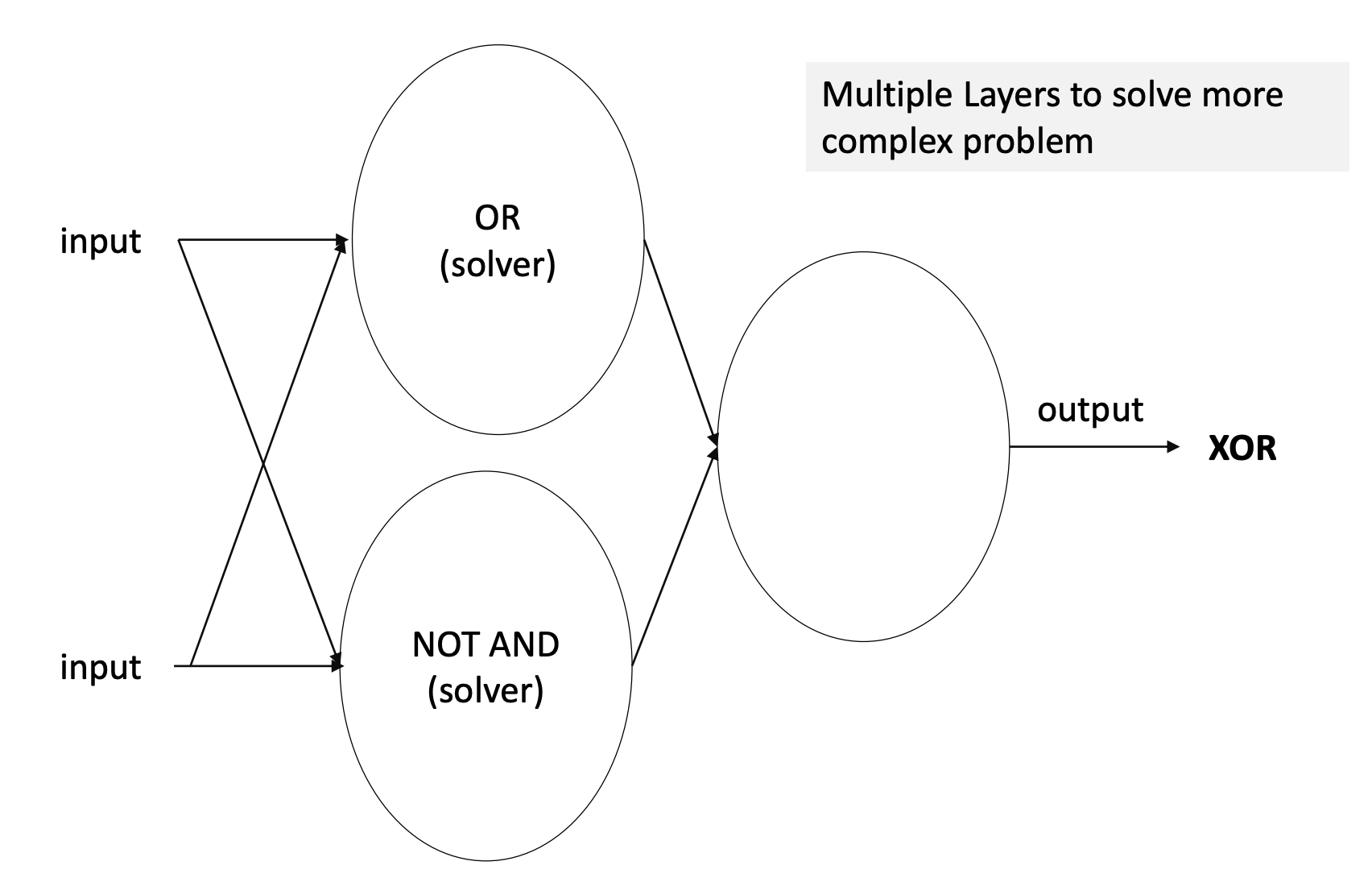
Multiple Layer를 만들 때 Single Linear Layer를 단순히 합치기보다는 Non-linear activation function을 추가해서 Combination을 만들어야한다.
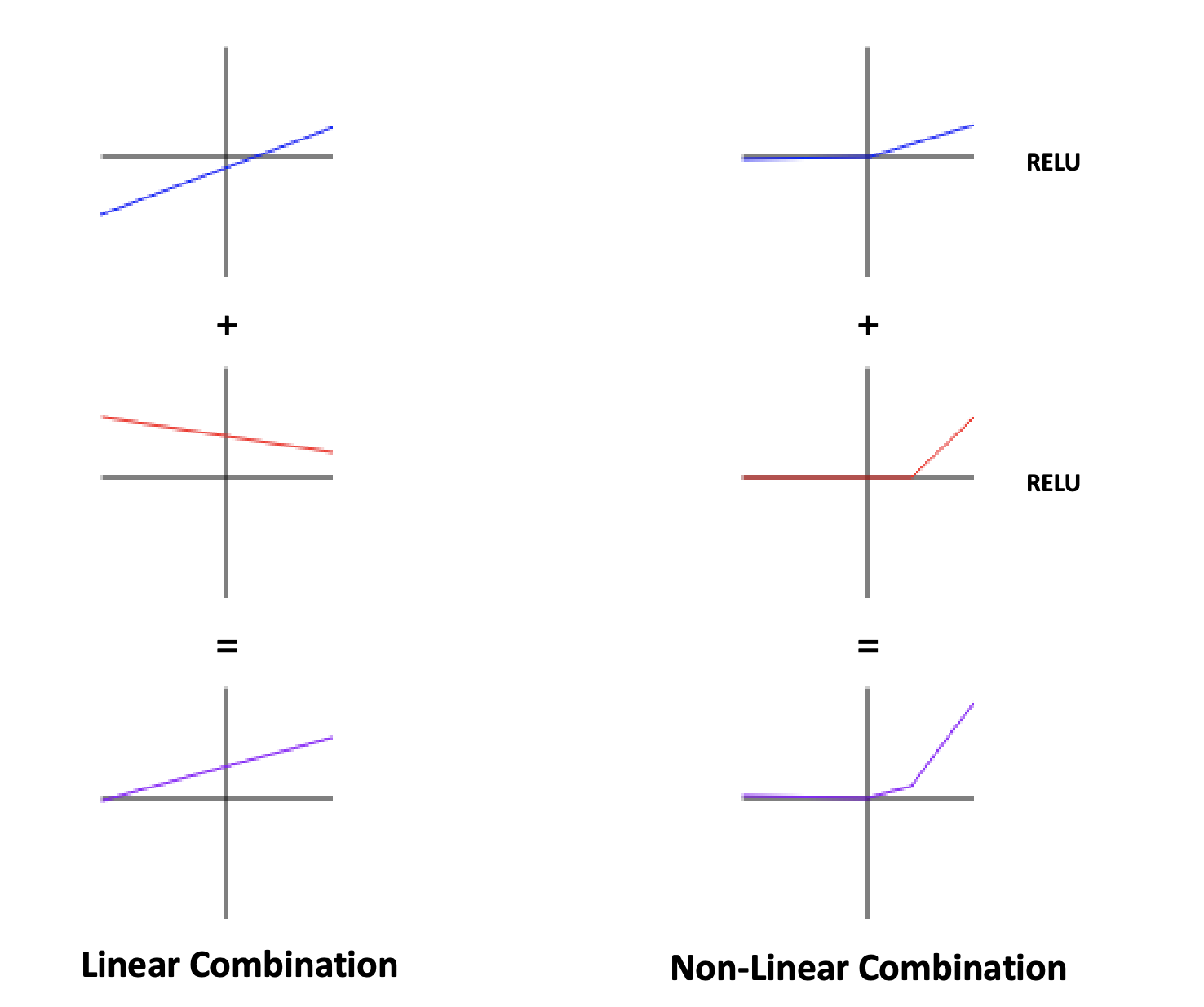
Non-linear activation function에는 sigmoid 함수, tanh 함수, RELU 함수 등이 있는데 이들은 모두 미분 가능하다.
딥러닝의 구조
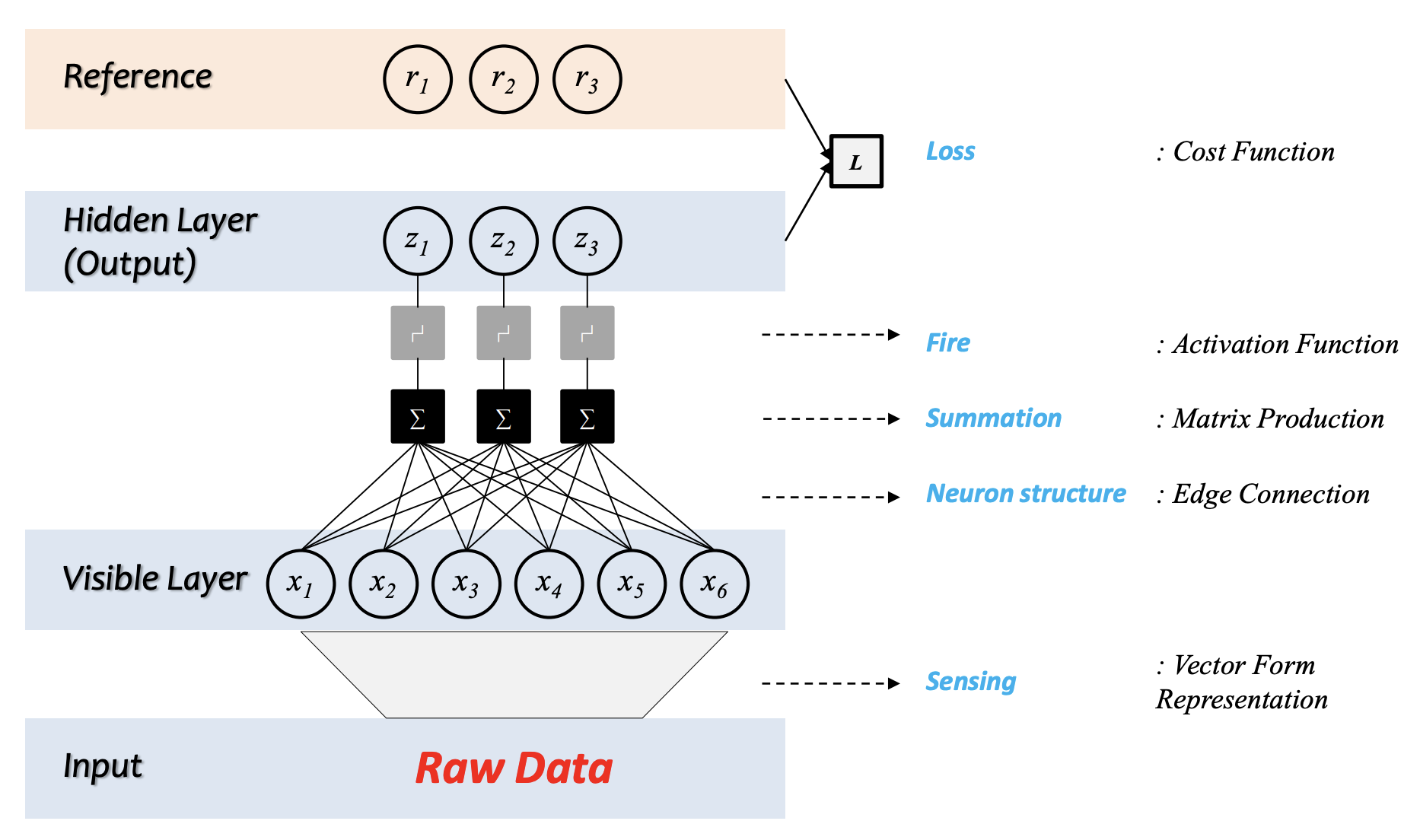
- raw data를 숫자 형태로 표현한다.
- 1번의 값이 특정한 레이어에 입력으로 들어가고, 이 값들이 fully connected 형태로 계산된다.
- 계산된 값이 activation function을 통해 다른 값으로 변형된다.
- 변형된 layer값과 정답값을 비교한다.
- 계산된 값을 미분하여 Backpropagation 시켜준다.
