1. 시작말
안녕하세요.
데이터 엔지니어링 & 운영 업무를 하는 중 알게 된 지식이나 의문점들을 시리즈 형식으로 계속해서 작성해나가며
새로 알게 된 점이나 잘 못 알고 있었던 점을 더욱 기억에 남기기 위해 글을 꾸준히 작성 할려고 합니다.
Trino의 경우 도서를 찾기 힘들어 공식 문서를 많이 참고해 운영을 하고 있습니다.
반드시 글을 읽어 주실 때 잘 못 말하고 있는 부분은 정정 요청 드립니다.
저의 지식에 큰 도움이 됩니다. :)
2. Trino 란?
Trino는 하나 이상의 이기종 데이터 소스에 분산된 대규모 데이터 세트를 쿼리하도록 설계된 분산 SQL 쿼리 엔진입니다.
공식 문서에서 알 수 있듯이 사용 용도는 분석과 DW 입니다. 역시나 Oracle, MySQL, Postgres 등의 OLTP를 받아내는 기존의 데이터베이스를 대체하는 것은 아닙니다.
Trino는 분산 쿼리를 사용하여 방대한 양의 데이터를 효율적으로 쿼리하도록 설계된 도구입니다.
테라바이트 또는 페타바이트 규모의 데이터로 작업하는 경우 Hadoop 및 HDFS와 상호 작용하는 도구를 사용하고 있을 가능성이 높습니다. Trino는 Hive 또는 Pig와 같은 MapReduce 작업의 파이프라인을 사용하여 HDFS를 쿼리하는 도구에 대한 대안으로 설계되었지만 Trino는 HDFS 액세스에만 국한되지 않습니다. Trino는 기존 관계형 데이터베이스와 Cassandra와 같은 기타 데이터 소스를 포함하여 다양한 종류의 데이터 소스에서 작동하도록 확장되었습니다.
Trino는 데이터 분석, 대량의 데이터 집계, 보고서 생성 등 데이터 웨어하우징 및 분석을 처리하도록 설계되었습니다. 이러한 워크로드는 종종 OLAP(온라인 분석 처리)으로 분류됩니다.
3. Trino Cluster
Trino Cluster 는 Coordinator 와 Worker 로 구성 됩니다.
Trino 를 사용하는 과정은 간략히 아래와 같습니다.
-
사용자는 Coordinator 에 접근하여 Trino 에 Query 를 보냅니다.
-
Coordinator는 Workload 를 조정하여 Worker 들에게 병렬 분산시킵니다.
-
각 Worker 들은 하나의 JVM 인스턴스에서 실행되며 스레드를 활용하여 병렬 처리를 합니다.
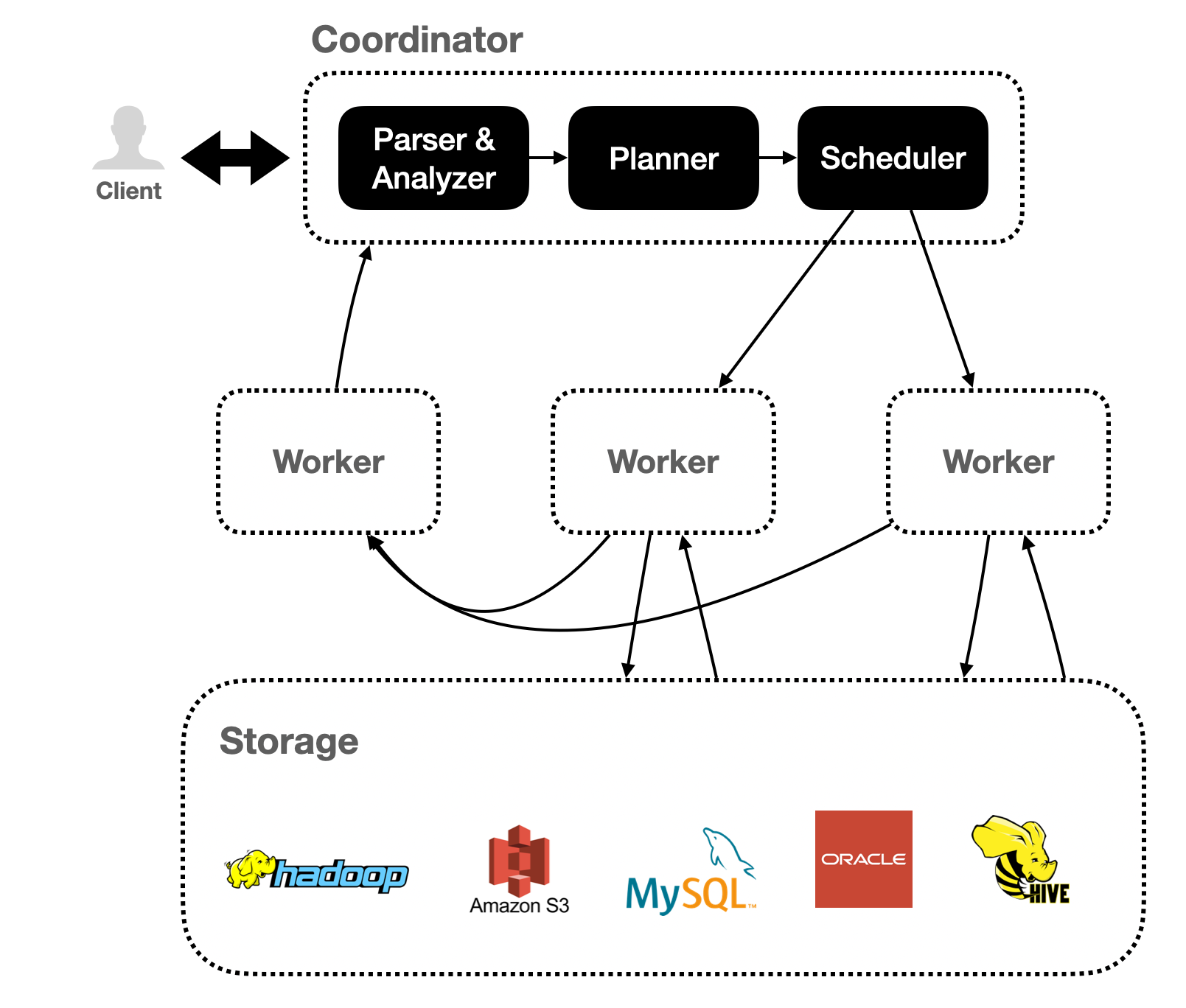
3.1. Coordinator
Trino Coordinator는 명령문 구문 분석, 쿼리 계획 및 Worker 노드 관리를 담당하는 서버입니다.
Trino Cluster 전체를 관리하는 노드이며, 클라이언트가 실행을 위해 명령문을 제출하기 위해 연결하는 노드이기도 합니다.
Trino 설치에는 반드시 하나 이상의 Worker 와 Coordinator 가 있어야 합니다. 개발 또는 테스트 목적으로 두 가지 역할을 모두 수행하도록 Trino의 단일 인스턴스를 구성할 수 있습니다.
3.2. Worker
Trino Worker 는 작업 실행 및 데이터 처리를 담당하는 Trino 설치 서버입니다. 작업자 노드는 커넥터에서 데이터를 가져오고 서로 중간 데이터를 교환합니다. Coordinator는 Worker로부터 결과를 가져오고 최종 결과를 클라이언트에 반환하는 일을 담당합니다.
Worker 프로세스가 시작되면 Coordinator의 검색 서버에 자신을 알리고 이를 통해 Coordinator 가 작업 실행을 사용할 수 있게 됩니다.
Worker는 REST API를 사용하여 다른 Worker 및 Trino Coordinator 와 통신합니다.
4. Trino 구성
Trino 는 아래와 같은 개념들을 활용하여 Data 를 구분하고 연결합니다.
- Connector
- Catalog
- Table
- Schema
4.1. Connector
Connector 는 Trino를 Hive 또는 관계형 데이터베이스와 같은 데이터 소스에 연결할 수 있습니다. 데이터베이스 드라이버를 생각하는 것과 같은 방식으로 커넥터를 생각할 수 있습니다. 이는 Trino가 표준 API(Application Programming Interface)를 사용하여 리소스와 상호 작용할 수 있도록 하는 Trino의 SPI(Service Provider Interface) 구현입니다.
API(Application Programming Interface) : 소프트웨어나 플랫폼에서 제공하는 서비스/기능에 액세스 하는 수단
SPI(Service Provider Interface) : 소프트웨어 또는 플랫폼의 동작을 주입, 확장 또는 변경하는 방
Trino에는 JMX(Java Management eXtention)용 커넥터, 내장 시스템 테이블에 대한 액세스를 제공하는 시스템 커넥터, Hive 커넥터, TPC-H 벤치마크 데이터를 제공하도록 설계된 TPCH 커넥터 등 여러 내장 커넥터가 포함되어 있습니다.
JMX(Java Management eXtention) : 어플리케이션의 상태를 모니터링하고 설정을 변경할 수 있는 프레임워크
TPC-H : 결정 지원 벤치마크로, 비즈니스 지향 애드혹 쿼리 및 동시 데이터 수정 모음으로 구성
모든 Catalog는 특정 Connector와 연결됩니다. Catalog 구성 파일을 조사하면 각 파일에는 지정된 Catalog에 대한 Connector를 생성하기 위해 Catalog 관리자가 사용하는 필수 속성인 Connector 이름이 포함되어 있음을 알 수 있습니다. 두 개 이상의 Catalog가 동일한 Connector를 사용하여 유사한 데이터베이스의 서로 다른 두 인스턴스에 액세스하도록 할 수 있습니다. 예를 들어 두 개의 Hive 클러스터가 있는 경우 둘 다 Hive 커넥터를 사용하는 단일 Trino 클러스터에 두 개의 Catalog를 구성하여 동일한 SQL 쿼리 내에서도 두 Hive 클러스터의 데이터를 쿼리할 수 있습니다.
아래는 Connector 지원 목록 입니다.
- Accumulo
- Atop
- BigQuery
- Black Hole
- Cassandra
- ClickHouse
- Delta Lake
- Druid
- Elasticsearch
- Google Sheets
- Hive
- Hudi
- Iceberg
- Ignite
- JMX
- Kafka
- Kinesis
- Kudu
- Local File
- MariaDB
- Memory
- MongoDB
- MySQL
- Oracle
- Phoenix
- Pinot
- PostgreSQL
- Prometheus
- Redis
- Redshift
- SingleStore
- SQL Server
- Thrift
- TPCDS
- TPCH
4.2. Catalog
Trino Catalog에는 Schema가 포함되어 있으며 Connector를 통해 데이터 소스를 참조합니다. 예를 들어, JMX 커넥터를 통해 JMX 정보에 대한 액세스를 제공하도록 JMX Catalog를 구성할 수 있습니다. Trino에서 SQL 문을 실행하면 하나 이상의 Catalog에 대해 SQL 문을 실행하게 됩니다. Catalog의 다른 예로는 Hive 데이터 소스에 연결하기 위한 Hive Catalog가 있습니다.
Trino에서 테이블 주소를 지정할 때 정규화된 테이블 이름은 항상 Catalog를 기반으로 합니다. 예를 들어 hive.test_data.test의 정규화된 테이블 이름은 Hive Catalog의 test_data Schema에 있는 테스트 테이블을 참조합니다.
Catalog는 Trino 구성 디렉터리에 저장된 속성 파일에 정의됩니다.
4.3. Schema
Schema 는 테이블을 구성하는 방법입니다. Catalog 와 Schema 는 함께 쿼리할 수 있는 테이블 집합을 정의합니다. Trino를 사용하여 Hive 또는 MySQL과 같은 관계형 데이터베이스에 액세스할 때 Schema 는 대상 데이터베이스에서 동일한 개념으로 변환됩니다. 다른 유형의 Connector 는 기본 데이터 원본에 적합한 방식으로 테이블을 Schema로 구성하도록 선택할 수 있습니다.
4.4. Table
테이블은 유형에 따라 명명된 열로 구성된 정렬되지 않은 행 집합입니다. 이는 모든 관계형 데이터베이스와 동일합니다. 소스 데이터에서 테이블로의 매핑은 커넥터에 의해 정의됩니다.
5. Trino Query 처리 방식
Trino는 SQL 문을 실행하고 이를 Coordinator와 Worker 분산 클러스터에서 실행되는 쿼리로 변환합니다.
5.1. Statement
Trino는 ANSI 호환 SQL 문을 실행합니다. 명령문이 실행되면 Trino는 일련의 Trino Worker에 배포되는 쿼리 계획과 함께 쿼리를 생성합니다.
5.2. Query
Trino는 Statement를 구문 분석할 때 이를 Query로 변환하고 분산 쿼리 계획을 생성하며, Worker 에서 실행되는 일련의 상호 연결된 단계로 실행됩니다. Trino에서 쿼리에 대한 정보를 검색하면 Statement에 대한 응답으로 결과 집합을 생성하는 데 관련된 모든 구성 요소의 스냅샷을 받게 됩니다.
Statement과 Query의 차이점은 간단합니다. Statement는 Trino에 전달되는 SQL 텍스트로 생각할 수 있는 반면, Query는 해당 Statement 를 실행하기 위해 인스턴스화된 구성 및 구성 요소를 참조합니다. Query 에는 결과를 생성하기 위해 함께 작동하는 단계, 작업, 분할, 커넥터 및 기타 구성 요소와 데이터 소스가 포함됩니다.
5.3. Stage
Trino는 쿼리를 실행할 때 실행을 계층 구조의 Stage로 나누어 수행합니다. 예를 들어, Trino가 Hive에 저장된 10억 행의 데이터를 집계해야 하는 경우 루트 Stage를 생성하여 다른 여러 Stage의 출력을 집계합니다. 이 Stage는 모두 분산 쿼리 계획의 다양한 섹션을 구현하도록 설계되었습니다.
쿼리를 구성하는 Stage의 계층 구조는 트리와 유사합니다. 모든 쿼리에는 다른 Stage의 출력을 집계하는 루트 단계가 있습니다. Stage는 코디네이터가 분산 쿼리 계획을 모델링하는 데 사용하는 것이지만 Stage 자체는 Worker에서 실행되지 않습니다.
5.4. Task
Stage는 분산 쿼리 계획의 특정 섹션을 모델링하지만 Stage 자체는 Worekr 에서 실행되지 않습니다. Stage가 실행되는 방식을 이해하려면 Stage가 Worker 네트워크를 통해 분산된 일련의 Task로 구현된다는 점을 이해해야 합니다.
분산 쿼리 계획이 일련의 Stage로 분해된 다음 Worker 로 변환되고 Split 에 따라 실행되거나 처리되므로 Task 는 Trino 아키텍처의 실질적인 작업 단위 입니다. Task 에는 입력과 출력이 있으며, Stage 가 일련의 Task 에 의해 병렬로 실행될 수 있는 것처럼 Task 는 일련의 드라이버와 병렬로 실행됩니다.
5.5. Split
Task 는 더 큰 데이터 세트의 섹션인 Split 에서 동작합니다. 분산 쿼리 계획의 가장 낮은 수준에 있는 Stage 는 커넥터에서 Split 을 통해 데이터를 검색하고, 분산 쿼리 계획의 더 높은 수준에 있는 중간 Stage 는 다른 Stage 에서 데이터를 검색합니다.
Trino가 쿼리를 예약할 때 Coordinator 는 테이블에 사용할 수 있는 모든 분할 목록에 대한 Connector 를 쿼리합니다. 코디네이터는 어떤 시스템이 어떤 Task 를 실행하고 있는지, 어떤 Split 이 어떤 Worker 에 의해 처리되고 있는지 추적합니다.
5.6. Driver
Task 에는 하나 이상의 병렬 드라이버가 포함되어 있습니다. Driver 는 데이터에 따라 작동하고 연산자를 결합하여 작업별로 집계된 다음 다른 Stage 의 다른 Task 로 전달되는 출력을 생성합니다. 드라이버는 일련의 연산자 인스턴스이거나 드라이버를 메모리에 있는 물리적 연산자 집합으로 생각할 수 있습니다. 이는 Trino 아키텍처에서 가장 낮은 수준의 병렬성입니다. 드라이버에는 하나의 입력과 하나의 출력이 있습니다.
5.7. Operator
운영자는 데이터를 소비하고, 변환하고, 생성합니다. 예를 들어, 테이블 스캔은 커넥터에서 데이터를 가져와 다른 연산자가 사용할 수 있는 데이터를 생성하고, 필터 연산자는 데이터를 사용하고 입력 데이터에 조건자를 적용하여 하위 집합을 생성합니다.
5.8. Exchange
Exchange 는 Query 의 다양한 Stage 를 위해 Trino 노드 간에 데이터를 전송합니다. Task 는 출력 버퍼에 데이터를 생성하고 Exchange 클라이언트를 사용하여 다른 Task 의 데이터를 소비합니다.
6. 맺음말
Trino 와 Impala 의 차이점을 사실 잘 몰랐었습니다. 그저 고속 분산 병렬 조회 도구라고만 생각했지만, 여러 커넥터를 지원하면서 카탈로그라는 개념으로 다양한 Storage 를 조회할 수 있는 점이 인상 깊었습니다. 조금 더 공부하여 Trino 를 더 잘 활용할 수 있는 방법이 있을 지 찾아봐야 할 듯 합니다.
