1. 시작말
안녕하세요.
데이터 엔지니어링 & 운영 업무를 하는 중 알게 된 지식이나 의문점들을 시리즈 형식으로 계속해서 작성해나가며
새로 알게 된 점이나 잘 못 알고 있었던 점을 더욱 기억에 남기기 위해 글을 꾸준히 작성 할려고 합니다.
Hive 경우 하둡 완벽 가이드와 구글링, ChatGPT, Hive Document 를 참고하여 운영하고 있습니다.
반드시 글을 읽어 주실 때 잘 못 말하고 있는 부분은 정정 요청 드립니다.
저의 지식에 큰 도움이 됩니다. :)
2. Hive Component
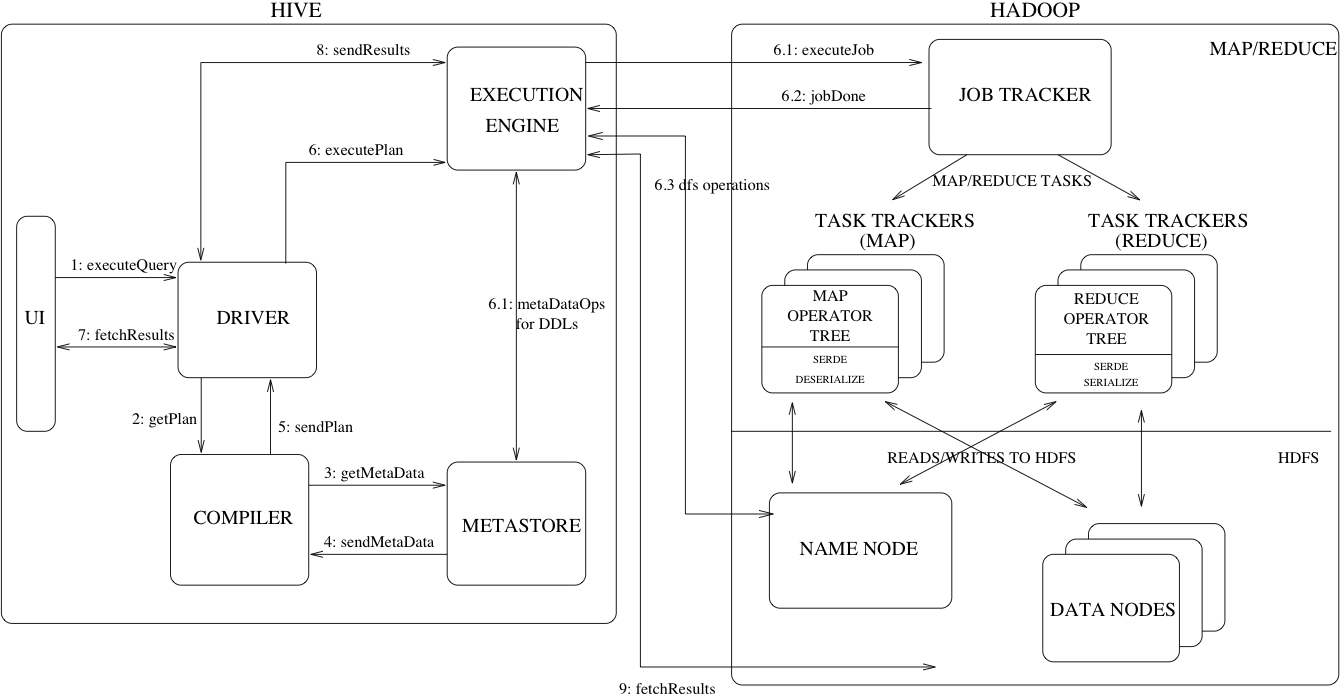
아래는 Hive 에서 구성되는 Component 들에 대한 설명들 입니다.
-
UI – 질의를 제출하고 기타 운영을 할 수 있는 UI 시스템입니다. (CLI)
-
Driver – 질의를 받는 컴포넌트 입니다.해당 컴포넌트는 세션 핸들 개념을 구현하고 JDBC/ODBC 인터페이스를 기반으로 한 실행 및 가져오기 API를 제공합니다.
-
Compiler – 쿼리 구문을 분석하는 컨포넌트로 다양한 쿼리 블록과 쿼리 표현식에 대한 의미를 분석하고 메타스토어에서 조회된 테이블 및 파티션 메타데이터를 사용하여 실행 계획을 생성합니다.
-
Metastore – 컬럼 및 컬럼 유형 정보, 데이터를 읽고 쓰는 데 필요한 직렬/역직렬 변환 컨포넌트 입니다. 데이터가 저장되는 해당 HDFS 파일을 포함하여 웨어하우스의 다양한 테이블 및 파티션의 모든 구조 정보를 저장하는 구성 요소입니다.
-
Execution Engine – 컴파일러에서 만든 실행 계획을 실행하는 컴포넌트 입니다. 계획은 DAG로 구성됩니다. Execution Engine 컴포넌트는 계획의 여러 단계 사이의 종속성을 관리하고 적절한 시스템 구성 요소에서 이러한 단계를 실행합니다.
3. Hive Data Model
Hive 는 3가지 데이터 모델을 가지고 있습니다.
- Table : 관계형 데이터베이스의 테이블과 유사합니다. 테이블을 filter, Project, join, union 할 수 있습니다. 또한 테이블의 모든 데이터는 HDFS의 디렉터리에 저장됩니다. Hive는 테이블 생성 DDL에 적절한 위치를 제공하여 HDFS의 기존 파일이나 디렉터리에 테이블을 생성할 수 있는 외부 테이블 개념도 지원합니다. 테이블의 행은 관계형 데이터베이스와 유사한 유형의 열로 구성됩니다.
project : 주어진 릴레이션에서 속성 리스트에 제시된 속성 값만을 추출하여 새로운 릴레이션을 만든다. 단, 연산 결과에 중복이 발생하면 중복이 제거된다.
- Partitions : 각 테이블은 어떻게 데이터를 저장할 지 하나 이상의 파티션키를 통해 결정합니다. 예를 들어 날짜 파티션 열이 있는 테이블 T에는 ds가
<테이블 위치>/ds=<date>HDFS 디렉터리에 저장된 특정 날짜에 대한 데이터가 있는 파일이 있습니다. 파티션을 사용하면 시스템이 쿼리 조건자를 기반으로 검사할 데이터를 정리할 수 있습니다. 예를 들어 조건자 T.ds = '2008-09-01' 쿼리는<table location>/ds=2008-09-01/파일만 보게 됩니다.
- Buckets : 각 파티션의 데이터는 테이블 열의 해시를 기반으로 버킷으로 분할될 수 있습니다. 각 버킷은 파티션 디렉터리에 파일로 저장됩니다. 버킷팅을 사용하면 시스템이 데이터 샘플에 의존하는 쿼리(테이블에서 SAMPLE 절을 사용하는 쿼리)를 효율적으로 평가할 수 있습니다.
4. Metastore 란
Metastore는 데이터 웨어하우스의 데이터 추상화와 데이터 검색을 제공합니다.
-
데이터 추상화 : Hive에서 제공되는 데이터 추상화가 없으면 사용자는 쿼리와 함께 데이터 형식, 추출기 및 로더에 대한 정보를 제공해야 합니다. Hive에서 이 정보는 테이블 생성 중에 제공되며 테이블이 참조될 때마다 재사용됩니다. 이는 기존의 Data Warehouse 시스템과 매우 비슷합니다.
-
데이터 검색 : 데이터 검색을 통해 사용자는 웨어하우스에서 관련성 있는 특정 데이터를 검색하고 탐색할 수 있습니다. 이 메타데이터를 사용하여 다른 Tool 을 만들거나 데이터 및 해당 가용성에 대한 정보를 노출하고 향상시킬 수 있습니다
Hive는 데이터와 메타데이터가 동기화되도록 Hive 쿼리 처리 시스템과 긴밀하게 통합된 메타데이터 저장소를 제공하여 이러한 기능을 모두 수행합니다.
Metastore 는 아래와 같은 Object 들로 구성되어 있습니다.
-
Database – Table 의 namespace 입니다. 향후 관리 단위로 사용할 수 있습니다. 사용자가 제공한 데이터베이스 이름이 없는 테이블에는 'default' 데이터베이스가 사용됩니다.
-
Table – 테이블의 메타데이터에는 열 목록, 소유자, 스토리지 및 SerDe 정보가 포함됩니다. 또한 사용자가 제공한 키 및 값 데이터가 포함될 수도 있습니다. 스토리지 정보에는 기본 데이터의 위치, 파일 입/출력 형식, 버킷팅 정보가 포함됩니다. SerDe 메타데이터에는 직렬/역직렬 변환기의 구현 클래스와 구현에 필요한 지원 정보가 포함됩니다. 이 모든 정보는 테이블 생성 중에 제공될 수 있습니다.
-
Partition – 각 파티션에는 자체 열과 SerDe 및 스토리지 정보가 있을 수 있습니다. 이는 이전 파티션에 영향을 주지 않고 스키마 변경을 용이하게 합니다.
5. Compiler 구성
-
Parser : 쿼리 문자열을 구문 분석 트리 표현으로 변환합니다.
-
Semantic Analyser : 구문 분석 트리를 연산자 트리가 아닌 여전히 블록 기반인 내부 쿼리 표현으로 변환합니다. 이 단계의 일부로 열 이름이 확인되고
*와 같은 확장이 수행됩니다. 이 단계에서는 유형 검사 및 암시적 유형 변환도 수행됩니다. 분석 중인 테이블이 파티셔닝 된 테이블인 경우(일반적인 시나리오) 해당 테이블에 대한 모든 표현식은 나중에 필요하지 않은 파티션을 prune 하는 데 사용할 수 있도록 수집됩니다. 쿼리에 샘플링이 지정된 경우 해당 샘플링도 나중에 사용하기 위해 수집됩니다. -
Logical Plan Generator : 내부 쿼리 표현을 연산자 트리로 구성된 논리적 계획으로 변환합니다. 일부 연산자는 'filter', 'join' 등과 같은 관계형 대수 연산자입니다. 그러나 일부 연산자는 Hive에만 해당되며 나중에 이 계획을 일련의 맵 축소 작업으로 변환하는 데 사용됩니다. 그러한 연산자 중 하나는 맵 축소 경계에서 발생하는 ReduceSink 연산자입니다. 이 단계에는 성능 향상을 위해 계획을 변환하는 최적화 프로그램도 포함됩니다. 이러한 변환 중 일부에는 일련의 조인을 단일 다중 방향 조인으로 변환, 그룹별로 맵 측 부분 집계 수행, 그룹화 수행 등이 포함됩니다. 그룹화 키에 대한 데이터가 왜곡되어 단일 감속기가 병목 현상을 일으킬 수 있는 시나리오를 피하기 위해 2단계로 진행됩니다. 각 연산자는 직렬화 가능한 객체인 설명자로 구성됩니다.
-
Query Plan Generator : 논리적 계획을 일련의 MapReduce 작업으로 변환합니다. 연산자 트리는 재귀적으로 탐색되어 나중에 Hadoop 분산 파일 시스템용 맵 축소 프레임워크에 제출할 수 있는 일련의 맵 축소 직렬화 가능 작업으로 분할됩니다. ReduceSink 연산자는 설명자에 축소 키가 포함된 맵 축소 경계입니다. ReduceSink 설명자의 축소 키는 맵 축소 경계의 축소 키로 사용됩니다. 계획은 쿼리에 지정된 경우 필수 샘플/파티션으로 구성됩니다. 계획은 직렬화되어 파일에 기록됩니다.
6. Optimzer
DB 에서 어떤 비용으로 최적화를 시킬지 고려하는 컴포넌트 이다.
optimizer 로 계획 변경이 수행된다.
- Rule Based Optimizer
- Cost Based Optimizer
7. 맺음말
Hive 내부를 더 뜯어보고 어떻게 동작하는지 궁금해져 계속해서 찾아봤습니다. 가능하다면 코드단이나 논문이 있다면 확인해보고 이해를 해보고 싶은 마음이 더 간절해집니다.
