1. 시작말
안녕하세요.
데이터 엔지니어링 & 운영 업무를 하는 중 알게 된 지식이나 의문점들을 시리즈 형식으로 계속해서 작성해나가며
새로 알게 된 점이나 잘 못 알고 있었던 점을 더욱 기억에 남기기 위해 글을 꾸준히 작성 할려고 합니다.
Iceberg 의 경우 공식 문서와 구글링을 통한 정보를 참고하여 학습하고 있습니다.
반드시 글을 읽어 주실 때 잘 못 말하고 있는 부분은 정정 요청 드립니다.
저의 지식에 큰 도움이 됩니다. :)
2. Overview

아이스버그는 고성능 빅데이터 분석을 위한 테이플 포맷입니다. 빅데이터 테이블을 Trino, Spark, Flink, Presto, Hive, Impala 등을 사용하여 간단한 SQL 로 안전하게 다룰 수 있게 합니다.
아이스버그는 Netflix 에서 근무하던 라이언 블루와 다니엘 웍스에 의해 만들어졌습니다.
비슷한 오픈소스로 델타 레이크, 후디 가 있으며, 세 가지 모두 Parquet 를 기반으로 비슷한 목표와 설계를 갖추고 있습니다.
데이터 브릭스에서는 사일로화 된 포맷들을 한가지로 합치는 델타 레이크 유니폼(UniForm) 을 발표했습니다. 그래서 검색량은 아무래도 데이터 브릭스의 델타 레이크가 더 많습니다.
참고 : https://www.cidrdb.org/cidr2021/papers/cidr2021_paper17.pdf
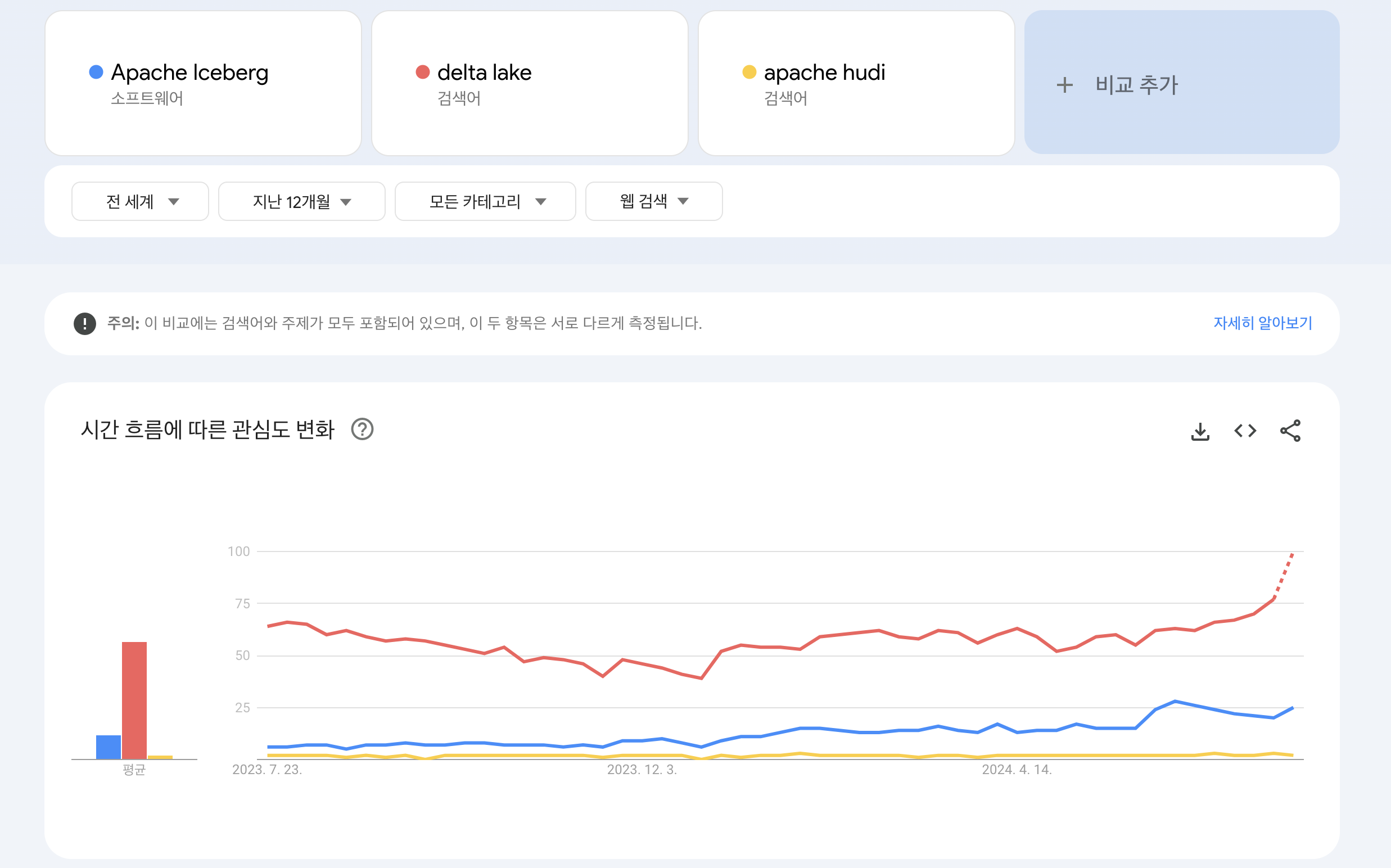
구글 트랜드 (2024.07.25)
하지만 데이터브릭스가 ICEBERG 를 만든이들이 세운 타뷸러를 인수하는 모습을 보여주는 것은 반대로 ICEBERG 의 인기를 반증하는 부분이기도 합니다.
참고 : http://m.newstap.co.kr/news/articleView.html?idxno=218773
참고 : https://www.e4ds.com/sub_view.asp?ch=1&t=0&idx=19128
3. Feature
ICEBERG는 아래와 같은 특징을 내세우고 있습니다.
- Expressive SQL
- Full Schema Evolution
- Hidden Partitioning
- Time Travel and Rollback
- Data Compaction
4. Architecture
아이스버그는 아래와 같은 방식으로 데이터를 읽어오게 됩니다.
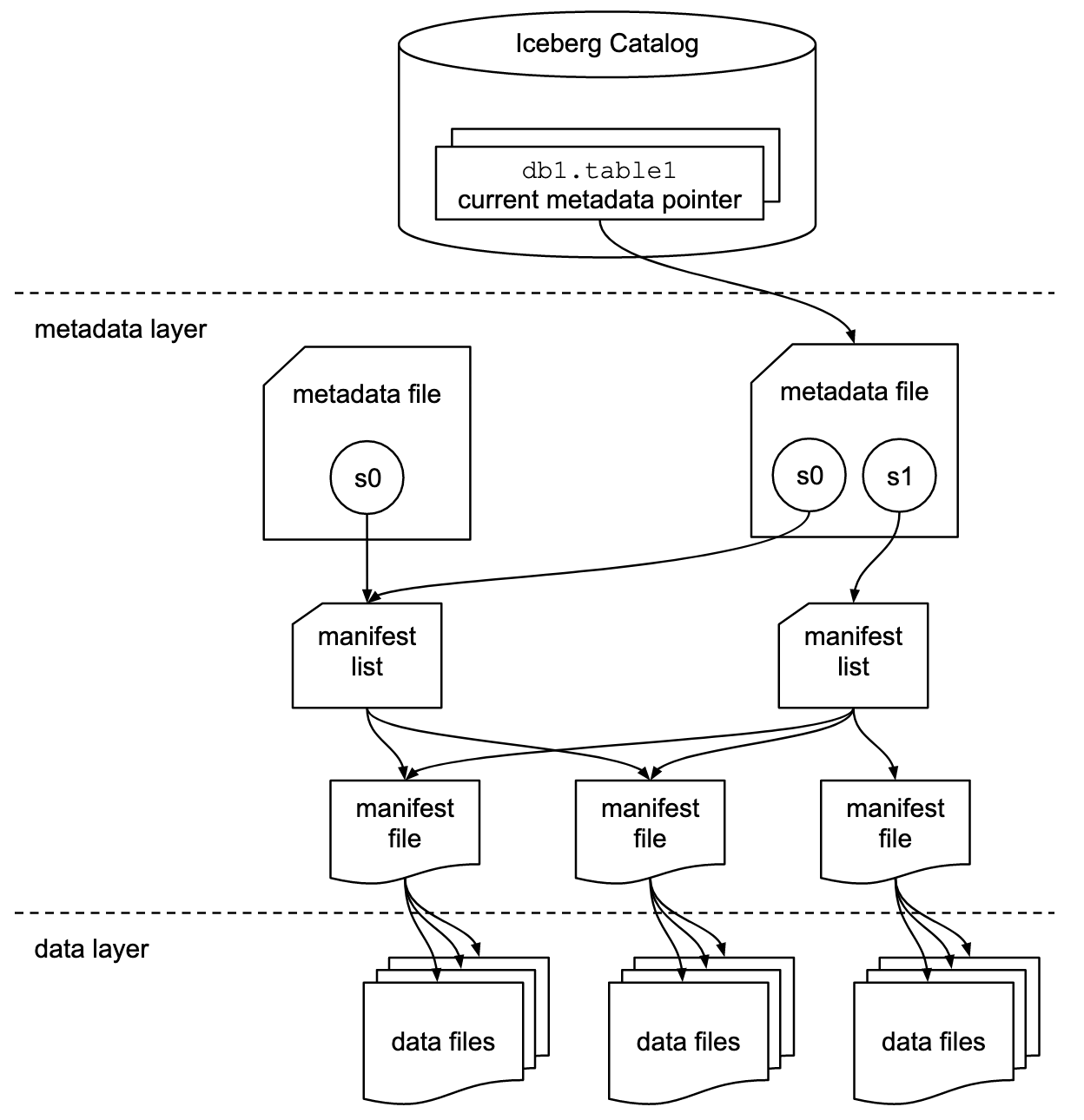
meatadata file(*.metadata.json) 을 읽어서 manifest list 정보를 확인한 후 실제 데이터 파일을 읽어옵니다.
이 때 metadata file은 스냅샷 정보들, 기본 통계, 버전별 스키마 정보 등 다양한 정보들이 들어있으며, 세부적인 내용들은 manifest file(.avro, .stats) 파일에 저장됩니다.
Iceberg는 단독으로 Iceberg 만을 사용해서 데이터에 접근할 수 없으며, Spark, Trino 등 다양한 SQL 엔진에 runtime 을 넣어서 붙을 수 있도록 구성되어 있습니다.
5. 용어
아이스버그에서 사용하는 용어에 대한 정리 입니다.
- Schema : 테이블 속 필드의 타입이나 이름들을 말합니다.
- Partition spec : 데이터 필드에서 파티션 값이 파생되는 방식에 대한 정의입니다.
- Snapshot : 특정 시간 별 테이블의 상태입니다.
- Manifest list : 한 스냅샷 당 manifest files 의 목록을 말합니다.
- Manifest : 데이터나 지운 파일들읠 목록 파일입니다.(스냅샷 하위 집합)
- Data file : 테이블의 Row들을 포함한 파일 입니다.
- Delete file : 테이블에서 지워진 Row 와 값이 쓰인 파일입니다.
6. Iceberg의 장점
-
Iceberg 는 적용이 쉽습니다. 기존의 구성되어 있는 HMS(Hive Metastore) 와 Trino, Spark 등을 활용하여 runtime jar 만 넣으면 구성이 가능합니다. (권한은 별도의 문제 입니다.)
-
데이터 형상 관리가 수월해집니다. 데이터 조작 실수로 인해 발생하는 데이터 유실을 커밋당 발생하는 스냅샷을 롤백하여 해결할 수 있습니다.
-
Update, Delete, Merge into 를 제공합니다. 기존의 Hive(ORC) 나 Kudu 또한 제공을 하고 있지만, Iceberg 는 구성이 쉬운 반면 많은 기능을 제공하고 있다는 점에서 장점 입니다.
7. 맺음말
아이스버그를 계속 공부하면서 문득 드는 생각은 역시나 엄청난 오픈 테이블 포맷이다 입니다. 기존의 운영 장애 복구를 더욱 편하게 만들어주며, 라이선스에 대한 종속성도 이슈를 많이 가지지 않을 것으로 보입니다.
