#include <iostream>
using namespace std;
int map[8];
int arr[8];
bool visited[8];
// 넣는다 history 추가
// 다음 것 찾음
// 히스토리 추가
int main() {
int n, m; cin >> n >> m;
for (int i = 0; i < n; i++){
cin >> map[i];
}
for (int i = 0; i < m; i++){
for (int j = 0; j < n; j++){
if (visited[j])continue;
arr[i] = map[j];
visited[j] = false;
for (int i = 0; i < n; i++)
{
}
}
}
}
여기서 막혔다
경우 수 반복을 어떻게 for문으로 만들어야 하는 지 알지 못했다.
길이 안에서 경우의 수를 반복하려고 하니 for문이 수열의 크기따라 추가되어야 했다.
이 부분에서 막혔다.
이전에 맞혔던 코드를 다시 보았다
#include <iostream>
#include <algorithm>
using namespace std;
int n, m;
int arr[10];
int num[10];
int check[10];
void dfs(int len) {
if (len == m) {
for (int i = 0; i < m; i++) {
cout << arr[i] << ' ';
}
cout << '\n';
return;
}
for (int i = 0; i < n; i++) {
if (check[i] == 0) {
arr[len] = num[i];
check[i] = 1;
dfs(len + 1);
check[i] = 0;
}
}
return;
}
int main() {
cin >> n >> m;
for (int i = 0; i < n; i++) {
cin >> num[i];
}
sort(num, num + n);
dfs(0);
return 0;
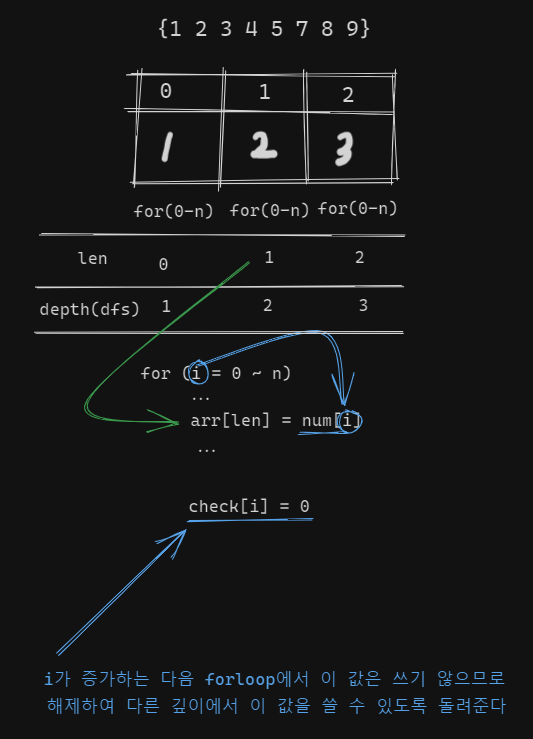
}아하 탄성이 나왔다. 수열의 길이는 len으로 관리하여 자리수를 넘지 못하게 하고 반복은 재귀로써 구현한 것이다. 만약 for문을 쓴다면 while 안에 for문을 써서 구현해줄 수 있나 생각도 해보았다.
if (len == m) {
for (int i = 0; i < m; i++) {
cout << arr[i] << ' ';
}
cout << '\n';
return;
}이 부분이 길이에 도달하면 그때 저장된 값을 출력하는 부분이다.
'길이에 도달했다' 를 표현해주는 것이 중요하다.
for (int i = 0; i < n; i++) {
if (check[i] == 0) {
arr[len] = num[i];
check[i] = 1;
dfs(len + 1);
check[i] = 0;
}
}이 부분을 해석해보자 if (check[i] == 0) 은 요소가 이미 사용되었는지를 검사한다.
arr[len] = num[i] 부분도 중요하다. arr[len]부분이 상당히 멋있다. 직관적이다. arr을 하나의 문자라고 생각한다면 len은 길이, 즉 index가 되어 자리수에 접근한다.
check[i] = 1 -> 사용된 요소는 사용체크를 한다.
여기서 중요한 부분이 등장한다. dfs(len + 1) !!!!!!
dfs가 다음 자리를 찾으러 간다.
dfs로 다음자리를 찾으러 가는 것 + 사용된 데이터를 기록하여 다시 사용되는 것을 막는 것
이 두가지가 이 알고리즘의 핵심이다.
멋있다.
그렇게 하나가 찾아지고 나면 dfs는 반환되고 사용된 요소는 다른 경우의 수를 위해 사용표시가 풀어진다.

DigitalArtDeveloper