쿠버네티스 패턴 중 3부(구조패턴), 4부(설정패턴), 5부(고급패턴)을 다룬다.
고급 패턴
쿠버네티스를 어떻게 확장하여 사용할 수 있을까?
컨트롤러 (Controller)
쿠버네티스의 작동 방식의 핵심 철학은 자원의 상태를 '선언(declare)'하는 것.
A deploy의 현재 Pod가 2개인 상태 (The current state)에서 Pod를 3개로 유지(The desired state)하고 싶은 경우, 사용자는 Pod를 하나 더 생성하라는 명령을 보내지 않고, Replicas의 값을 3으로 변경함.
그렇다면 누가 그 다음 일들을 대신해주나?
State Reconciliation
쿠버네티스의 내장 컨트롤러들이 현재 상태에서 요청된 상태가 되도록 'reconcile'함
- 관측 (observe): target 자원들이 변경될 때, 쿠버네티스가 배포하는 이벤트를 watch하여 실제 상태를 찾음.
- 분석 (analyze): 실제 상태와 요청된 상태의 차이를 알아냄
- 실행 (act): 실제 상태가 요청된 상태로 되도록 작업을 수행
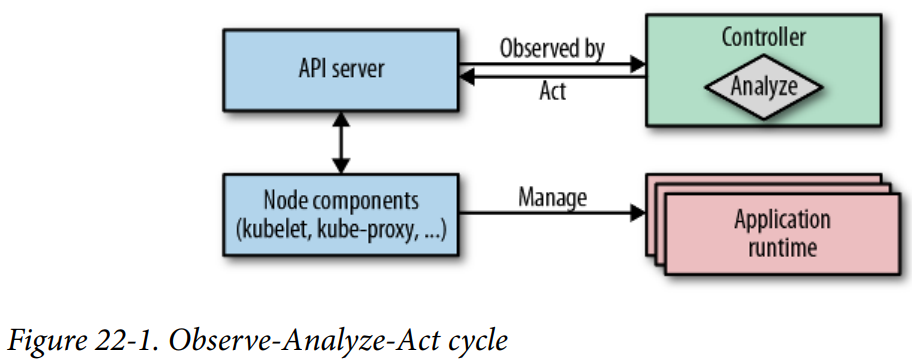
이미 쿠버네티스의 control plane은 위와 같이 컨트롤러를 통해 쿠버네티스 자원을 관리하도록 설계되어있음.
위처럼 reconciliation을 해주는 사용자 컨트롤러도 만들 수 있겠다.
참고) 컨트롤러는 보통 deploy로 배포되며, 동일한 자원에 여러 개의 컨트롤러가 동시에 작동하는 것을 피하기 위해 싱글톤 패턴으로 동작함. 즉 하나의 replica.
대상 자원의 선택
컨트롤러가 무엇을 보고 어떤 리소스를 관리할 지 정할 수 있을까?
레이블
- 모든 컨트롤러가 watch할 수 있음
- 백엔드 DB에 인덱싱되어 효율적으로 검색 가능
- Alphanumeric과 - _ . 만 허용
- 예)
app: web
애노테이션
- 레이블 대신에 사용, 쿼리에 사용하지 않는 비 식별정보
- 성능에 부정적인 영향 없음
- 예)
meta.helm.sh/release-name: myservice
컨피그맵
- 레이블, 애노테이션에 잘 맞지 않는 정보들로 상태를 정의하고자 할 때
- 비교적 적은 권한 필요
예제
- ConfigMap에 정의된 메세지를 반환하는 웹앱
apiVersion: v1
kind: ConfigMap
metadata:
name: webapp-config
annotations:
k8spatterns.io/podDeleteSelector: "app=webapp"
data:
message: "Welcome to Kubernetes Patterns !"
---
apiVersion: apps/v1
kind: Deployment
# ...
spec:
# ...
template:
spec:
containers:
- name: app
image: k8spatterns/mini-http-server
ports:
- containerPort: 8080
env:
- name: MESSAGE
valueFrom:
configMapKeyRef:
name: webapp-config
key: message- 컨트롤러의 Reconciliation script
namespace=${WATCH_NAMESPACE:-default}
base=http://localhost:8001
ns=namespaces/$namespace
curl -N -s $base/api/v1/${ns}/configmaps?watch=true | \
while read -r event
do
type=$(echo "$event" | jq -r '.type')
config_map=$(echo "$event" | jq -r '.object.metadata.name')
annotations=$(echo "$event" | jq -r '.object.metadata.annotations')
if [ "$annotations" != "null" ]; then
selector=$(echo $annotations | \
jq -r "\
to_entries |\
.[] |\
select(.key == \"k8spatterns.io/podDeleteSelector\") |\
.value |\
@uri \
")
fi
if [ $type = "MODIFIED" ] && [ -n "$selector" ]; then
pods=$(curl -s $base/api/v1/${ns}/pods?labelSelector=$selector |\
jq -r .items[].metadata.name)
for pod in $pods; do
curl -s -X DELETE $base/api/v1/${ns}/pods/$pod
done
fi
done- 컨트롤러 배포
apiVersion: apps/v1
kind: Deployment
# ....
spec:
template:
# ...
spec:
serviceAccountName: config-watcher-controller
containers:
- name: kubeapi-proxy
image: k8spatterns/kubeapi-proxy
- name: config-watcher
image: k8spatterns/curl-jq
# ...
command:
- "sh"
- "/watcher/config-watcher-controller.sh"
volumeMounts:
- mountPath: "/watcher"
name: config-watcher-controller
volumes:
- name: config-watcher-controller
configMap:
name: config-watcher-controller유의점
- 컨트롤러는 '이벤트'를 본다 → 비동기 → 이벤트의 흐름이 단순하지 않을 경우 디버깅이 어려울 수도
오퍼레이터 (Operator)
컨트롤러로 코드의 변경 없이 애플리케이션 관리할 수 있음.
- 쿠버네티스의 API 이용
- 쿠버네티스의 기본 리소스 (deploy, service, configmap 등) 이용
예를 들어, 프로메테우스라는 어플리케이션을 모니터링 솔루션으로 사용하고 싶다. 그렇다면 create deploy처럼 create prometheus가 있었으면 좋겠다.
오퍼레이터 = (쿠버네티스 + 쿠버네티스 이외의 것들)을 이해하는 컨트롤러
Custom Resource Definition (CRD)
사용자가 쿠버네티스 리소스를 정의하고 그 것들을 관리하기 위한 API도 추가할 수 있음
예제: Prometheus
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: prometheuses.monitoring.coreos.com
spec:
group: monitoring.coreos.com
names:
kind: Prometheus
plural: prometheuses
scope: Namespaced
version: v1
validation:
openAPIV3Schema: ....
subresources:
status: {}
scale:
specReplicasPath: .spec.replicas
statusReplicasPath: .status.replicas
labelSelectorPath: .status.labelSelector
---
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: prometheus
spec:
serviceMonitorSelector:
matchLabels:
team: frontend
resources:
requests:
memory: 400Mi유의점
- 클러스터 관리자 권한 필요
언제 적합할까?
- To use
- kubectl 툴에 긴밀한 통합을 원할 때
- API group / API 버전관리 / namespace 등 쿠버네티스 시스템의 기능을 누리고자 할 때
- watch, auth, rbac, metadata selector 등을 사용하는 높은 수준의 클라이언트를 지원하고자 할 때
- Not to use
- '선언적' 사용이 아닐 때,
- 쿠버네티스에 긴밀하게 통합할 필요가 없을 때
탄력적 스케일 (Elastic scale)
파드가 필요한 리소스, 레플리카 개수, 클러스터 노드의 갯수를 요구량에 맞게 동적으로 설정하기 위한 방법.
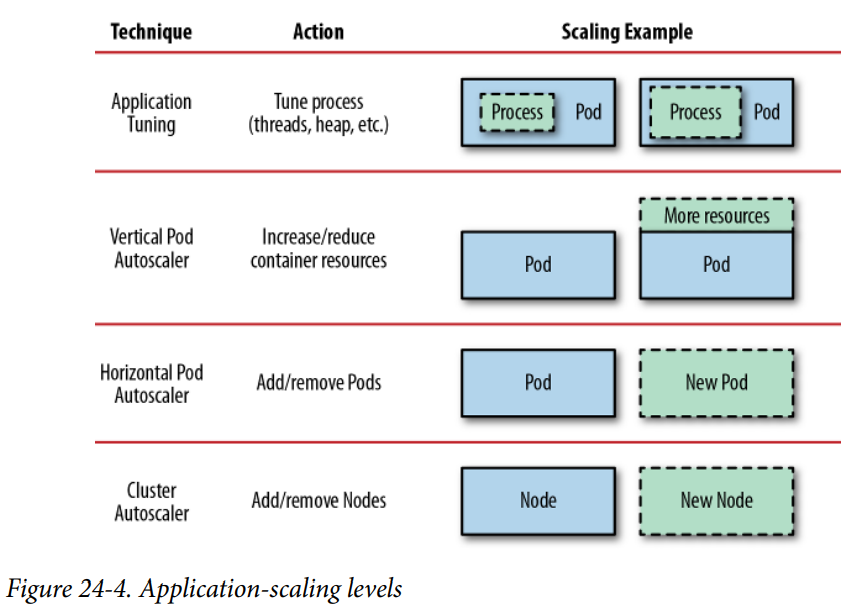
애플리케이션 튜닝
- 애플리케이션이 컨테이너에 할당된 자원을 최대한 잘 사용하도록 하는 것
- 오토스케일링 기능으로 제공되는 것은 아님
- trial-and-error
- 너무 적은 리소스가 할당되었을 때: Out-of-memory 에러. 수평 스케일 도움 x
- 가용한 리소스를 쓰지 않을 때: 수평/수직/노드 스케일링 도움 x
수직 파드 오토스케일링(Vertical Pod Autoscaler, VPA)
각 컨테이너에 적절한 Resource requests/limits를 설정하는 것.
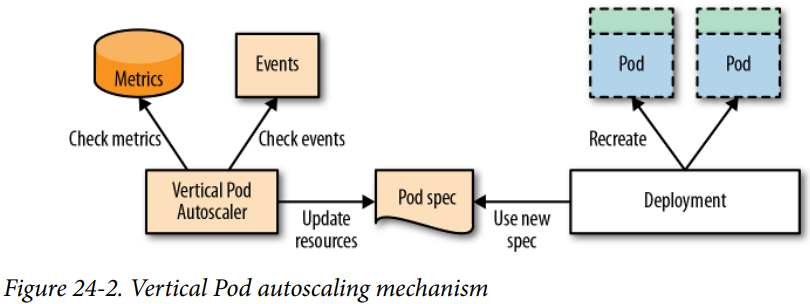
- 너무 적은 Resource 할당: 노드가 꽉 채워져 Out-of-memory, CPU 고갈, Pod 축출 발생
- 너무 많은 Resource 할당: 노드 자원 낭비
- EKS: https://docs.aws.amazon.com/ko_kr/eks/latest/userguide/vertical-pod-autoscaler.html
수평 파드 오토스케일링(Horizontal Pod Autoscaler, HPA)
각 파드의 적절한 Replica 개수를 설정하는 것
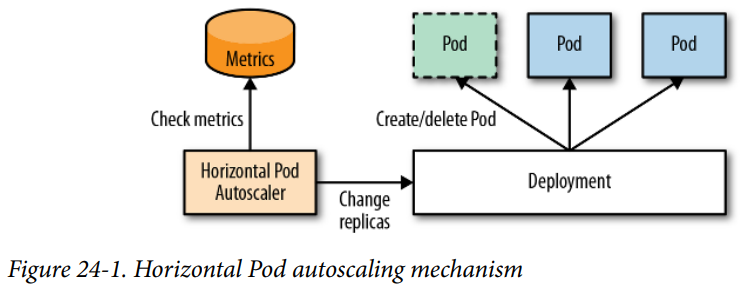
HPV에 정의된 스케일링될 파드들에 대한 메트릭을 가져온 뒤, 필요한 레플리카 수를 계산함
desiredReplicas = currentReplicas * currentMetricValue / desiredMetricValue
중단 가능성이 낮고 자동화가 쉬워서 가장 흔하게 사용됨
예제
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: random-generator
spec:
minReplicas: 1
maxReplicas: 5
scaleTargetRef:
apiVersion: extensions/v1beta1
kind: Deployment
name: random-generator
metrics:
- resource:
name: cpu
target:
averageUtilization: 50
type: Utilization
type: Resource유의사항
컨테이너에 대한 resources.requests가 설정되어 있어야 함.
- 클러스터 전체의 리소스 사용량에 대한 메트릭 서버가 활성화 되어있어야 함.
- 올바른 메트릭 선택?
- 메트릭 값과 Replica 수에 직접적인 상관관계가 있어야.
- ex) 초당 HTTP 요청: 파드 수 ↑ 더 많은 요청 ↑ 평균 쿼리 수 ↓
- ex) 메모리 소모량: 메모리 해제 매커니즘이 없는 서비스 & 메트릭에 메모리 반영 x HPA는 메모리 사용량 줄이기 위해 계속 Pod 생성
- 메트릭 값과 Replica 수에 직접적인 상관관계가 있어야.
클러스터 오토스케일링(Cluster autoscaler, CA)
클러스터 자체의 용량을 조절하는 방법. 동적으로 노드를 할당 받아 클러스터에 조인하는 것으로 클라우드(EKS, GKS 등)에서 실행될 때 사용 가능.
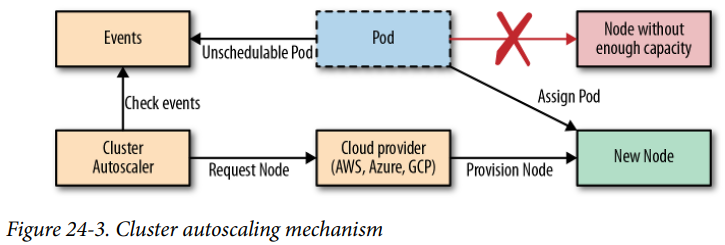
스케일 업
Pod가 수동/HPA/VPA를 통해 스케일 될 때 적당한 노드에 배치되어야 하지만 노드가 없다면 unschedulable 상태로 대기함
CA는 이런 Pod들을 모니터링해 미리 지정한 Node Group 중 어느 노드가 요구 사항을 만족하는지 판단한 뒤 노드를 새로 할당
스케일 다운
노드가 더 이상 필요하지 않다고 판단될 때 해당 노드를 제거함
- 노드의 모든 Resource requests가 노드 자원의 50% 미만
- 노드의 이동 가능한 모든 Pod가 다른 노드에 배치될 수 있는 경우
- 이동 불가능한 노드가 없는 경우
- 로컬 저장소 사용하는 파드 / Eviction 방지하는 애노테이션 있는 파드 / 컨트롤러 없이 생성된 파드 / PodDisruptionBudget이 있는 파드
이미지 빌더
클러스터에서 사용하는 이미지도 클러스터 안에서 빌드하자.
- CI: 빌드 잡을 위한 컴퓨팅 자원을 쿠버네티스가 적절하게 찾아줄 수 있다
- CD: 클러스터는 이미지 빌드와 애플리케이션을 알고 있기 때문에 이미지가 변경되면 자동으로 재배치하도록 할 수 있다.
오픈시프트 빌드
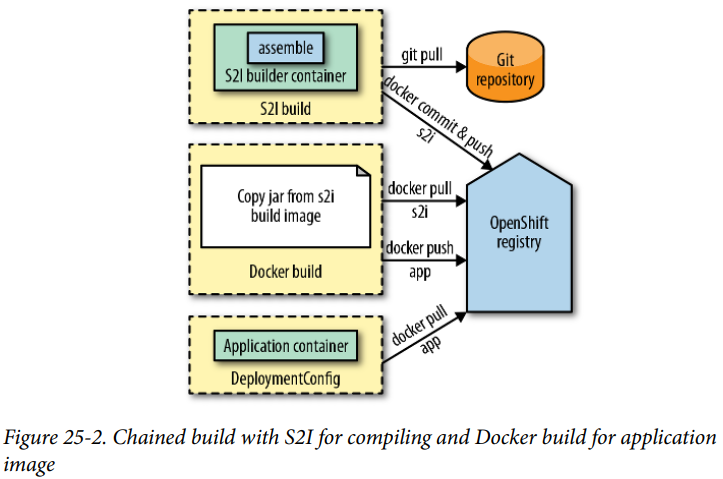
Tecton Pipelines