
Transformer는 기존에 sequential 데이터를 처리하는 RNN 구조를 사용하지 않고, attention mechanism만 사용해 단어를 임베딩해 병렬처리를 가능하게 했다.
Background
Seq2Seq Model
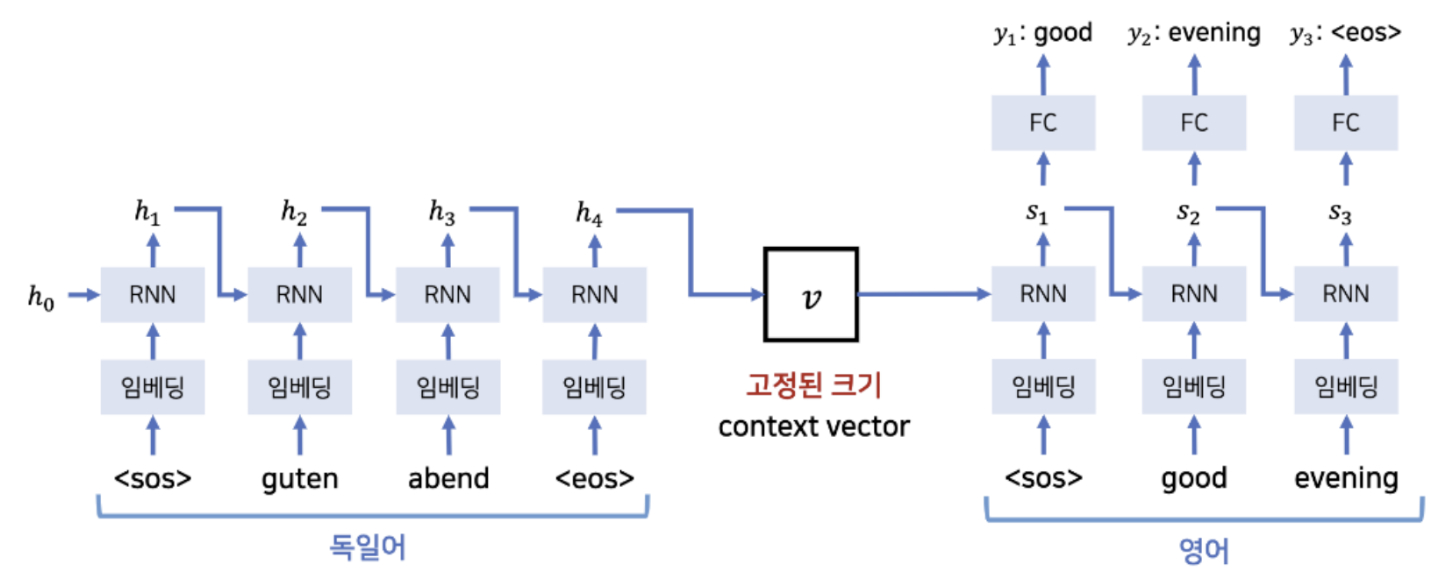
- Seq2Seq 모델은 encoder-decoder 구조로 이루어지며, 입력 문장을 읽는 RNN 모델을 Encoder, 출력 문장을 생성하는 RNN 모델을 Decoder라고 한다. 인코더끼리, 디코더끼리 동일한 파라미터를 공유하며 인코터와 디코더 간에는 파라미터를 공유하지 않는다. 위 그림에서는 RNN 모델로 LSTM을 사용했다.
- 인코더의 마지막 hidden state는 디코더의 첫 번째 hidden state 역할을 한다. 디코더는 시작을 의미하는 토큰이 등장하면 인코더의 마지막 hidden state를 사용해 다음 단어를 예측하고, 토큰이 나올 때 까지 수행한다. , 토큰은 vocab에 미리 정의해 사용한다.
Seq2Seq 모델의 한계
- Seq2Seq는 순차적으로 입력 sequence를 읽어 고정된 크기의 context vector(hidden state)에 입력 문장의 정보를 압축해 저장한다. RNN과 비교해 LSTM에서 long-term dependency를 개선했지만 여러 layer를 거치면 여전히 앞쪽에 등장한 정보는 손실될 수 있으며, 긴 문장 예측이 어려운 단점이 있다.
- 앞쪽에 나타난 정보를 잃지 않기 위해 입력 sequence를 거꾸로 모델에 feed하는 테크닉도 제안되었지만, 근본적인 문제를 해결하지는 못했다.
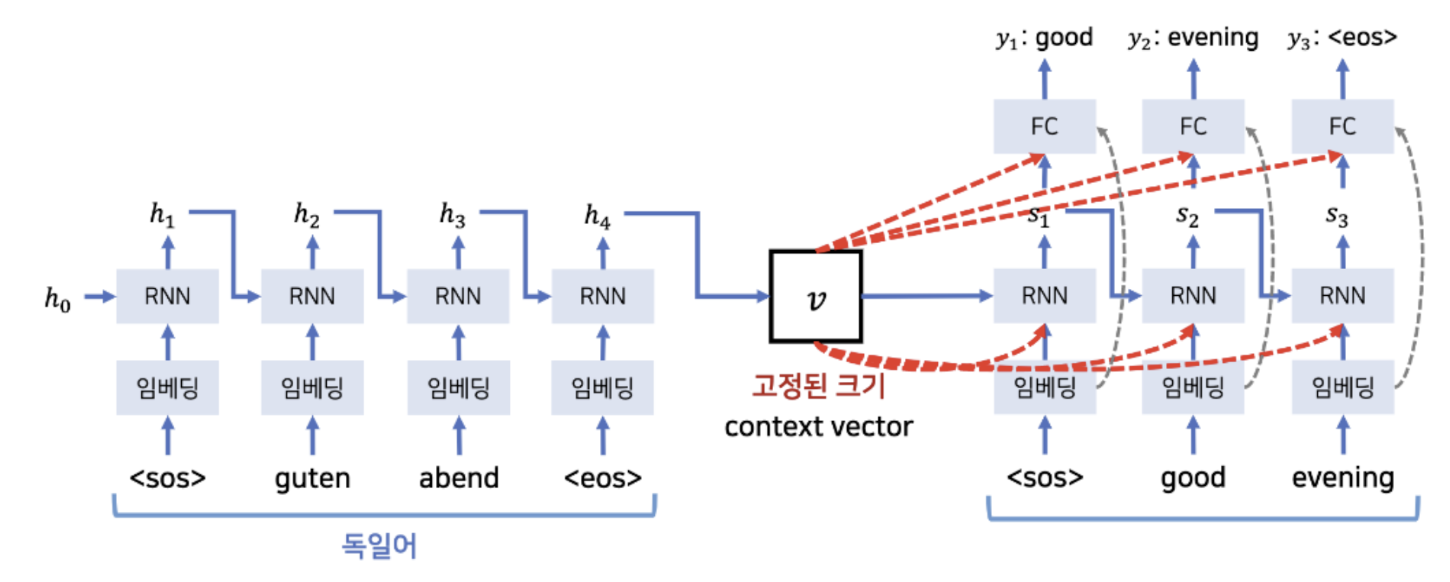
context vector 값이 손실되지 않기 위해, decoder가 매번 context vector를 참고하도록 하는 방법이 제안되었다. 하지만 여전히 하나의 input sequence를 고정된 크기의 context vector로 압축시켜야 하기 때문에, 성능이 저하된다.
“Decoder 부분에서 context vector 정보를 가지고 있지 않고, encoder의 모든 출력을 매번 입력으로 받으면 어떨까?” 라는 관점에서 Seq2Seq with Attention이 제안되었다.
Seq2Seq Model with Attention
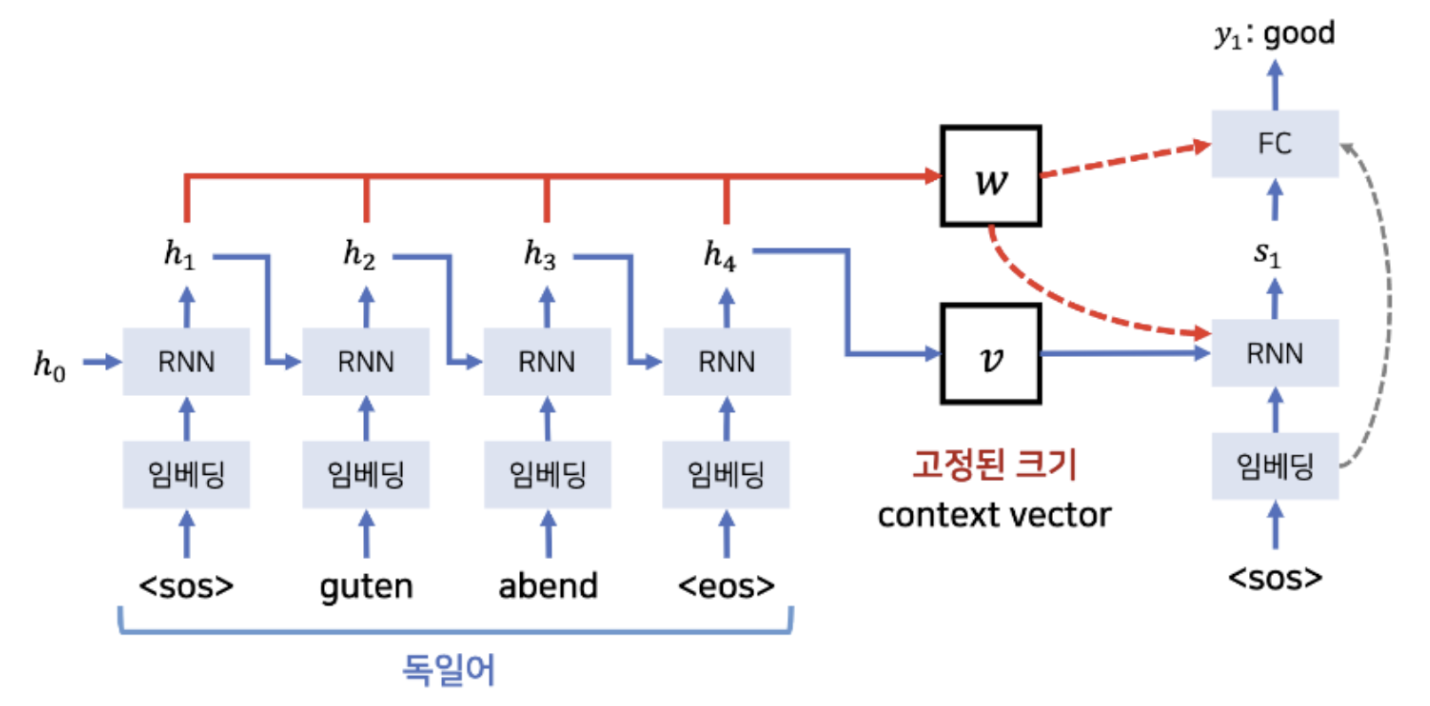
Decoder는 context vector 뿐만 아니라 encoder의 모든 를 전부 반영한 weighted sum vector 를 사용해 출력을 생성한다.
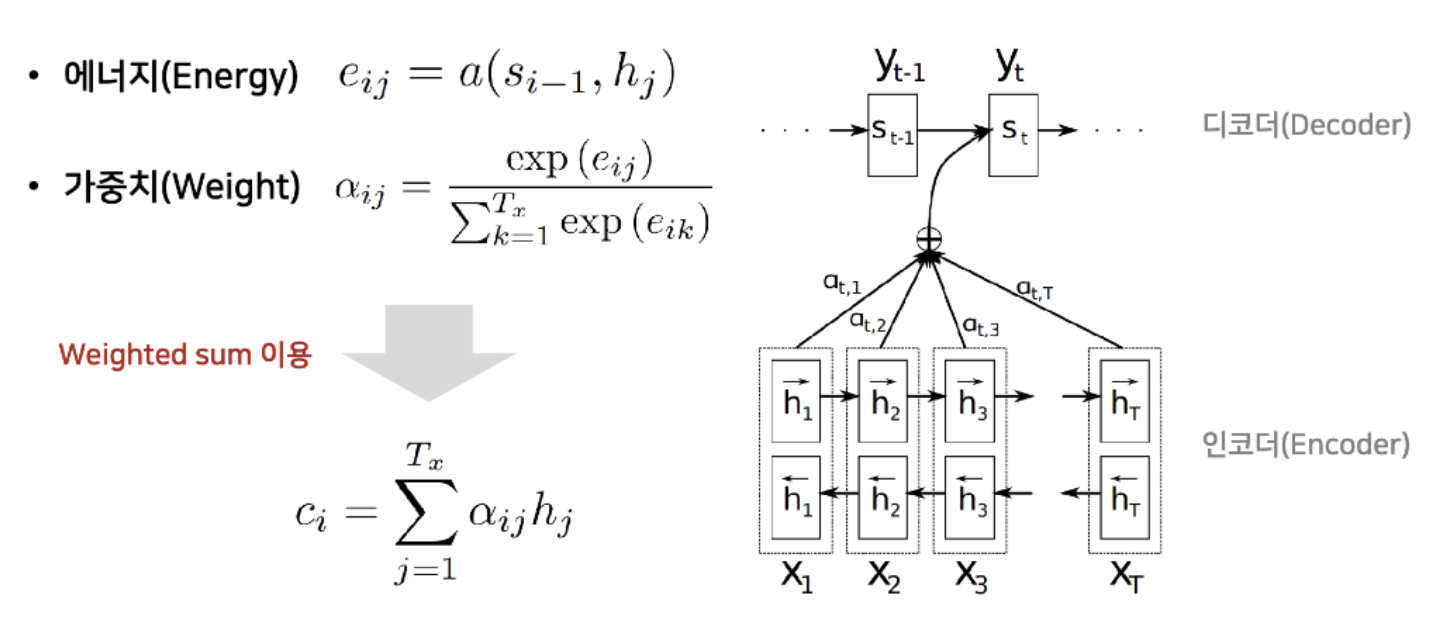 위 그림은 attention을 수행하는 과정으로 아래와 같은 과정으로 계산된다.
자세한 내용은 Attention이 제안된 논문인 Neural Machine Translation by Jointly Learning to Align and Translate에 나온다.
위 그림은 attention을 수행하는 과정으로 아래와 같은 과정으로 계산된다.
자세한 내용은 Attention이 제안된 논문인 Neural Machine Translation by Jointly Learning to Align and Translate에 나온다.
: 디코더가 처리중인 인덱스
: 인코더의 출력 인덱스
: time step=i 에서 디코더의 hidden state
1) 이전에 만든 디코더의 hidden state인 과 인코더의 모든 출력(hidden state)을 사용해 에너지 를 계산한다. 즉, 디코더는 출력 단어를 만들 때마다 모든 인코더의 hidden state를 고려한다.
2) 에너지 값을 구한 후에, softmax를 취해 확률값을 구한다. 이 확률값은 각 hidden state에 부여하는 가중치로 사용된다.
3) 앞서 구한 에너지와 가중치를 사용해 각 hidden state에 weight만큼의 가중치를 부여한다.
Model Architecture
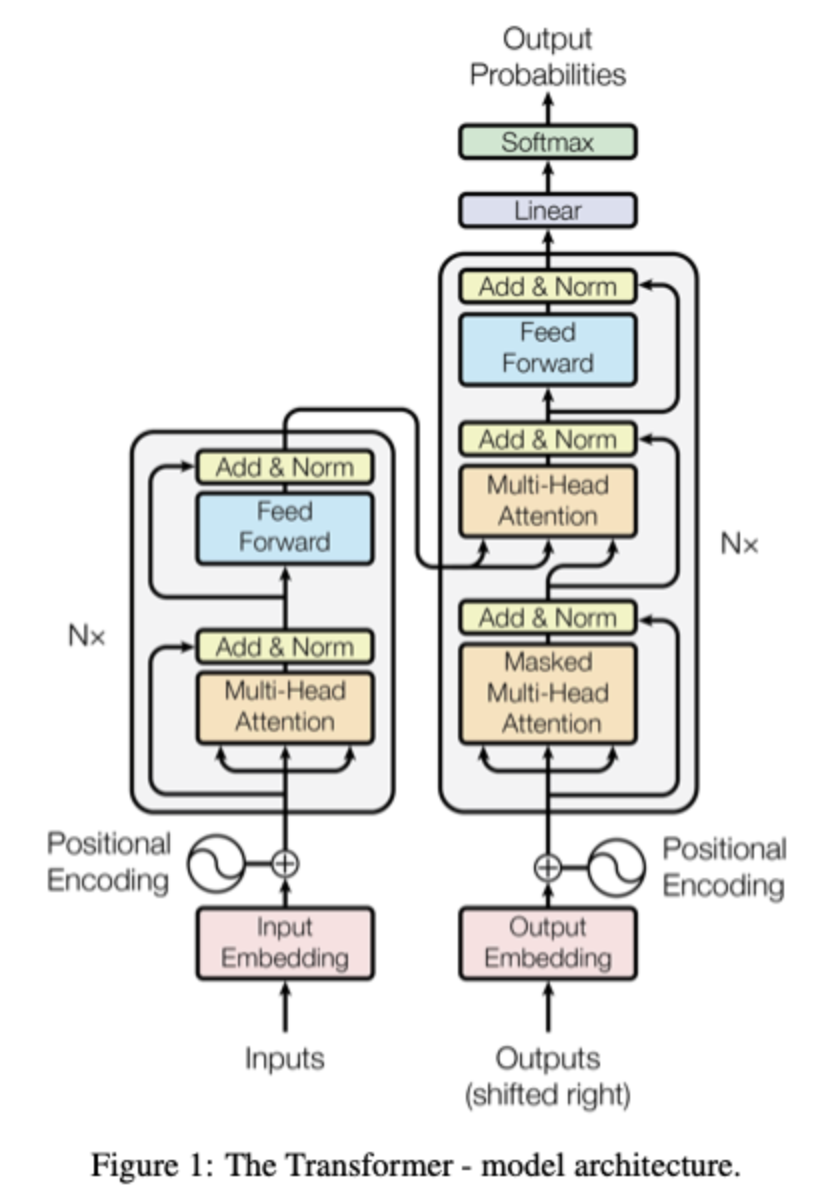 Transformer는 auto-regressive한 구조인 RNN을 완전히 배제하고 stacked self-attention, position-wise fully connected layer로 구성된 구조이다. Auto-regressive(자기회귀)란 과거의 자기 자신을 사용해 현재의 자신을 예측하는 모델로 일반적으로 시계열, 텍스트 등 ‘시간종속성'을 갖는 데이터에 많이 사용된다.
Transformer는 auto-regressive한 구조인 RNN을 완전히 배제하고 stacked self-attention, position-wise fully connected layer로 구성된 구조이다. Auto-regressive(자기회귀)란 과거의 자기 자신을 사용해 현재의 자신을 예측하는 모델로 일반적으로 시계열, 텍스트 등 ‘시간종속성'을 갖는 데이터에 많이 사용된다.
Seq2Seq처럼 encoder-decoder 구조로 구성되며 encoder는 입력 문장의 정보를 압축하는 역할, decoder는 압축된 정보를 사용해 매 timestep마다 출력 토큰을 하나씩 생성한다.
Encoder
- N=6개의 층으로 구성되며, 각 층은 2개의 sub-layer로 구성된다. 다시 각 sub-layer는 multi-head self-attention mechanism과 position-wise fully connected feed-forward network로 구성된다.
- 각 sub-layer에 입력을 더해줄 때 residual connection을 수행하며, 그 결과에 대해 layer normalization을 수행한다. Residual connection을 사용하기 위해 각 layer의 입출력 차원을 512로 동일하게 맞춘다. ()
- Residual Connection: ResNet에서 사용하는 기법. 특정 layer를 건너뛰어 입력값을 넣어 학습하는 방법으로, 이전 layer와의 차이점만 학습한다. 학습할 부분이 줄어들어 학습 난이도가 낮아짐에 따라 초기 수렵 속도가 높아지고, global optima를 찾을 확률이 높아진다. ⇒ 성능이 좋아지는 효과가 있다. (preview 2 참고)
Decoder
- encoder와 동일하게 N=6개의 층으로 구성되며, 각 층은 3개의 sub-layer로 구성된다. encoder와 거의 동일한 구조인데, 마지막 sub-layer만 추가되었다. 마지막 sub-layer는 encoder의 출력 결과와 decoder 간의 multi-head attention을 수행한다. 또한 attention을 수행할 때 미래 토큰은 사용할 수 없도록 masking처리를 한다.
Multi-Head Attention
- 모델의 핵심인 내용으로 preview 1에 있다.
Positional Encoding
- 또한 Transformer는 RNN구조를 사용하지 않기 때문에, 위치 정보를 포함하는 임베딩을 만들 수 있도록 positional encoding을 사용했다. 관련 내용은 preview 3에 있다.
Position-wise feed-forward network
- 비선형적인 요소를 더하기 위해 수행한 layer라고 볼 수 있다.
Why Self-Attention

: the sequence length
: the dimension of representation
: the kernel size of convolutions
: the size of the neighborhood in restricted self-attention
논문에서 Self-Attention의 장점으로 3가지를 제시했다.
- layer당 계산 복잡도 감소
- 병렬적으로 연산 가능
- maximum path length 감소: 많은 sequence transduction task에서 긴 dependency를 학습하는 것은 어려운 task이다. input과 output간의 dependency가 짧아질수록 dependency를 학습하기 수월해진다.
RNN
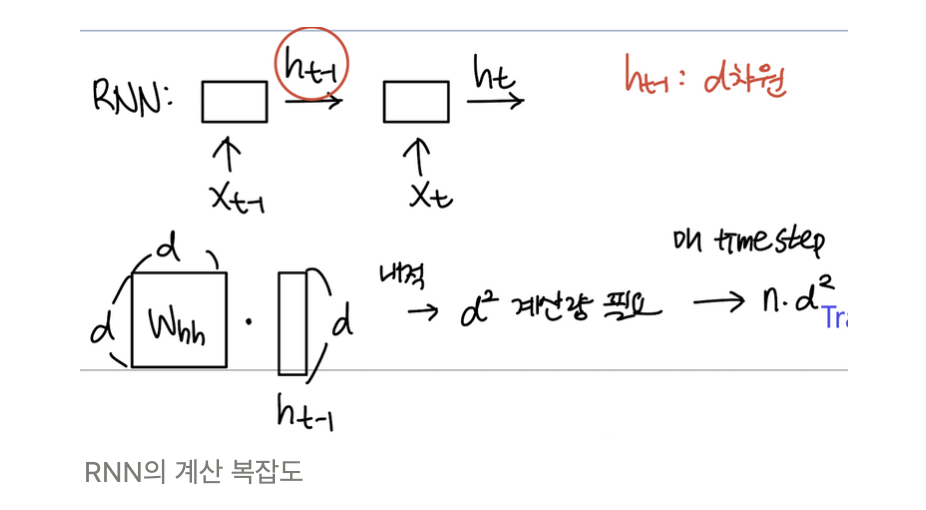
RNN의 계산 복잡도
- 차원 hidden state vector를 구할 때는 차원 와 차원 을 내적 연산하는데, 여기서 만큼의 연산량이 발생한다. 이 연산을 매 time step마다 반복하므로 의 연산량을 가진다.
- n은 time step의 개수, d는 hidden state vector의 차원에 해당(hyper parameter로 변경 가능)
Self-Attention
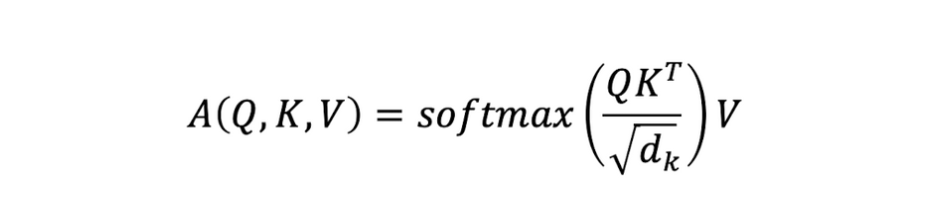
- Self-Attention에서 연산량이 가장 많은 항은 이다. 차원의 Query vector와 차원의 vector의 내적 연산은 차원의 계산을 모든 (query-key)조합에 대해 수행한다. → → GPU core 수가 충분하다면 행렬 연산의 병렬화를 사용하면 연산하는데 시간이 소요된다.
- n은 입력 데이터의 길이로 임의로 조절할 수 없다. 동일한 길이의 sequence를 사용했을 때 RNN보다 메모리 요구량이 더 크다.
- Self-Attention은 RNN보다 학습속도는 빠르지만 메모리 요구량은 더 크다. RNN은 hidden state를 순차적으로 계산하기 때문에 병렬화가 불가능하다.
- 표에서 마지막 컬럼의 Maximum Path Length는 long-term dependency와 관련되는데, RNN에서는 첫번째 단어가 마지막 단어를 참조하기 위해서는 n번의(모든) RNN layer를 통과해야 하기 때문에 O(n)이다. 반면에 self-attention은 time step과 상관없이 한번에 유사도 정보를 얻을 수 있다.
Training
- dataset: WMT 2014 English-German dataset
- encoding: byte-pair encoding(BPE)
- optimizer: Adam 사용, lr값을 고정하지 않고 warmup_steps까지는 lr을 선형적으로 증가시키고, warmup_steps 이후에는 step_num의 에 비례하도록 감소시킨다.

- Regularization
- Residual Dropout: 각 sub-layer와 positional encoding에 dropout을 적용했고, base 모델 기준 dropout ratio=0.1을 사용했다.
- Label Smoothing
- 말 그대로 label값을 스무딩해주는 방법으로, 기존 정답이 [1, 0, 0] 이었다면 [0.95, 0.025, 0.025]로 label을 변경한다. label smoothing을 적용하면 정답이 뽑힐 확률이 낮아져 정답이라는 확신을 줄여준다.
- 적용 결과 perplexity 성능은 안 좋아졌지만, BLEU score는 증가했다. BLEU score는 정답이 있는지 없는지만 판단하기 때문에 score가 올라갔다고 볼 수 있다.
- 또한 perplexity는 번역 task의 성능 지표로는 적합하지 않다는 의견(?)이 있어서 “label smoothing이 성능 향상의 효과가 있다” 정도만 짚고 넘어가고자 한다. 왜 label smoothing이 잘 되는지는 이 논문에 나와있다.
Results
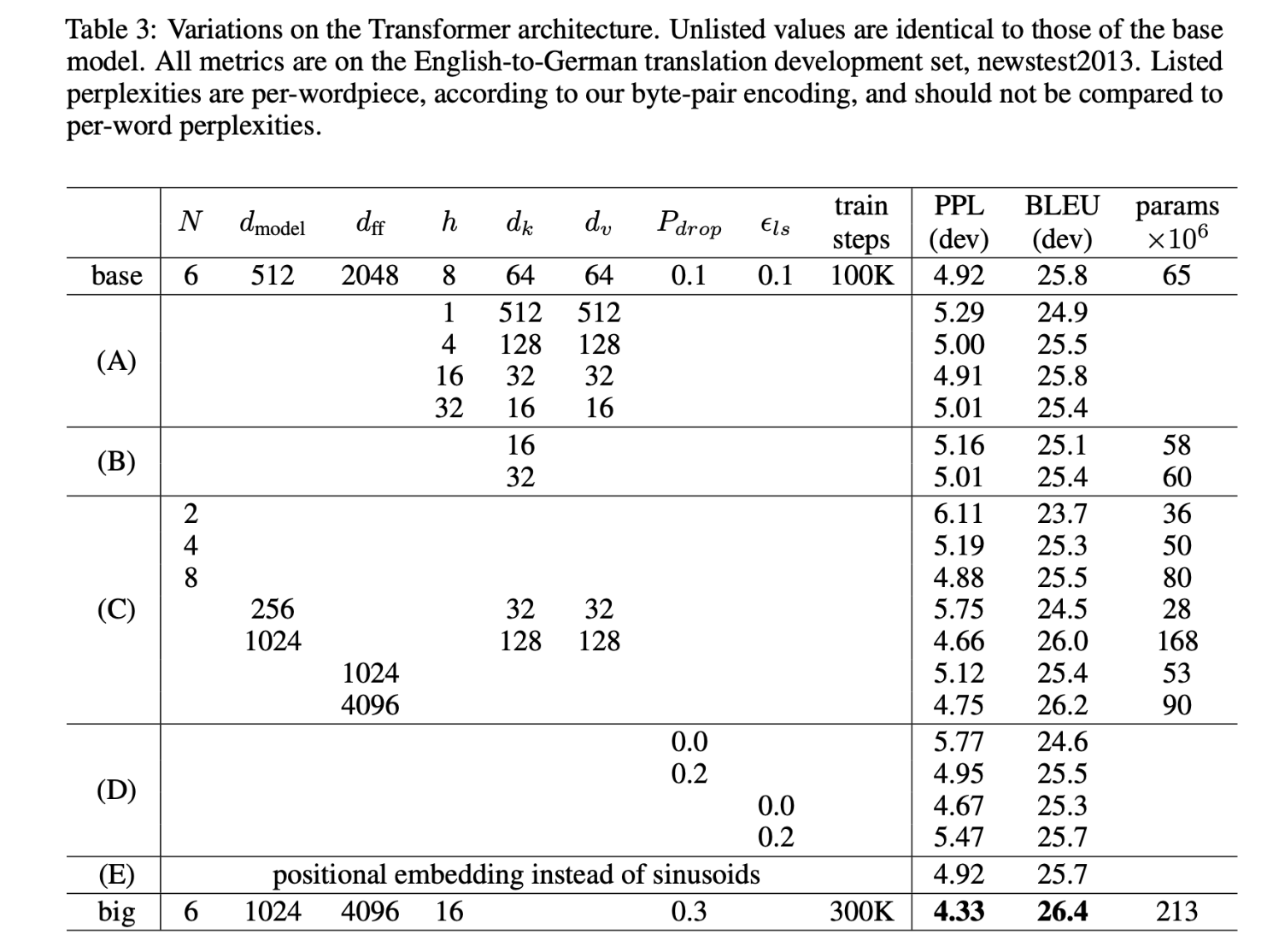
위의 표를 통해 설정한 파라미터 값에 따라 모델의 성능이 달라진 것을 확인할 수 있다. 가장 성능이 좋았던 파라미터를 살펴보면 다음과 같다.
(A): 전체 computation constant는 고정시키고 head 수만 증가시키면 성능이 떨어진다.
(B): attention key size인 를 줄이는 것은 모델 성능을 하락시킨다.
(C): 큰 모델일수록 성능이 좋다.
(D): dropout은 성능 향상에 효과적이다.
(E): sinusoidal positional encoding과 learned positional embeddings은 비슷한 성능을 보였다. sinusoidal positional encoding은 학습 시간이 짧은 장점이 있다.
후기
Transformer는 NLP 뿐만 아니라 다양한 SOTA 모델의 뼈대가 되는 모델인데, 이런 논문을 읽었다는 점에서 아주 뜻깊었다. 아마 다시 읽을 논문 1순위가 아닐까 싶다.
이전에 네이버 부스트캠프에서 강의를 들을 때는 Self-Attention에만 집중했다면, 이번에는 전반적인 논문의 흐름과 학습에 사용한 방법에 좀 더 집중했다. 논문에 소개된 방법 중에 시간이 지나면서 더 효율적이 방법이 등장해서 사용되지 않는 방법도 있어서 다음 리뷰에서는 Transformer 코드를 보면서 이런 부분을 더 공부해 봐야겠다.
Reference
