
Level 2의 첫 번째 대회인 KLUE 관계 추출 대회가 끝났다. 팀 단위로 랩업 리포트와 깃허브에 담지 못한, 팀 전체 의견으로는 담기 어려운 개인적인 내용을 위주로 회고를 작성해 보았다.
지난 대회와 비교해 성장한 부분 🔥
이번 대회에서 가장 발전한 점과 우리 팀의 강점을 뽑으면 협업이다.
지난 대회에서는 리더보드 점수에 굉장히 신경썼다면, 이번 대회에서는 리더보드 점수보다는 ‘근거를 기반으로 가설 설정하고 실험하기'와 ‘제대로 된 협업하기’에 초점을 두고 진행했다. 팀원 모두 Level1 대회에서 협업 측면에서 아쉽다고 느껴 대회 시작하기 전 따로 시간을 내어 그라운드 룰을 설정하고 협업 툴도 세팅했다.
1. 협업 툴
지금 team groud rule 페이지가 다른 내용으로 덮어쓰여져서 정확히 확인하기 어렵지만, 기억을 더듬어 적어보면 코드 관리는 github, 전반적인 진행 상황은 github project, 실험 결과 공유는 github issue + notion + wandb, 자세한 내용은 notion을 활용했다. 정리하면 github, notion, wandb 3가지를 사용했다.
코드 관리 - github
github 관련해서는 같은 팀원인 찬국님께서 초기 세팅을 해주셨고, 초반에 branch가 엉키거나 conflict가 발생했을 때 일대일 과외 선생님처럼 해결해주셨다!
기능별로 branch를 만들어 기능 단위로 코드를 관리할 수 있도록 했다. feat/data_aug, exp/kfold > develop > master (각자 개발중인 기능 > 완성한 기능 > 모델에 적용할 기능)으로 branch를 구성했다.
이전에는 branch를 많이 사용하지 않았고 사용한다 하더라도 개인별 branch를 생성해 사용했었다. 이번에 사용하면서 branch를 자유롭게 바꾸는 것도 익숙해졌고 다른 종류의 실험을 할 때 주석이 아닌 branch만 변경해 주면 되는 편리함을 경험했다.
전반적인 진행 상황 관리 - github project의 kanban board
전반적인 진행 상황 관리는 github project의 kanban board를 사용했다. (이것도 찬국님께서 적극적으로 도입하셨다!) 왼쪽부터 순서대로 할 일 > 개발중 > 개발 및 모든 팀원 이해 완료 > merge 완료 순서이다. 데일리 스크럼이나 피어세션 시간에 해야할 일들을 같이 작성하고, 코어 타임에는 각자 하고 싶은 일을 할당해 수행했다. 개발 완료된 기능은 일단 PR을 올리고 피어세션 시간에 코드 설명 후 모든 팀원이 이해하면 merge했다. 추가적으로 각자 맡은 역할은 label로 이름을 표시해 동일한 기능이나 실험이 중복되지 않도록 했다.
notion에도 kanban board 기능이 있는걸로 아는데 우리 팀에는 노션에 능수능란하게 다루는 분이 없고, github에서는 이슈로 연결할 수 있는 장점이 있어서 github를 사용했다.
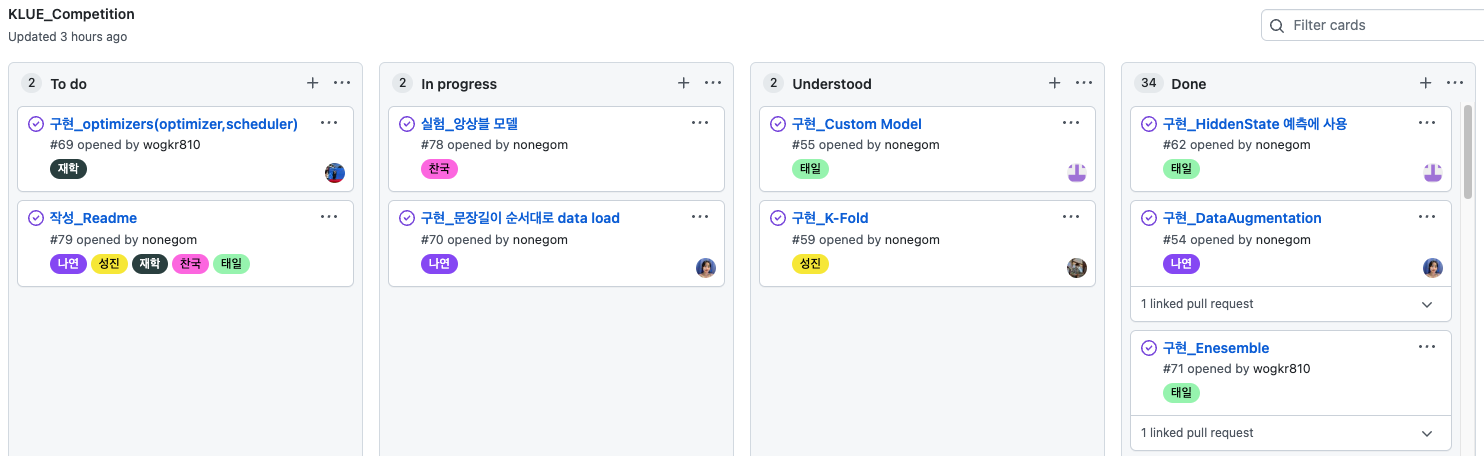
왼쪽부터 순서대로 할 일 > 개발중 > 개발 및 모든 팀원 이해 완료 > merge 완료 순서이다.
실험 결과 공유 - github issue + notion + wandb
처음에는 실험 이름만 통일해 짧게 실험 설명과 wandb 그래프만 슬랙에 공유했었다. 하지만 대회 1주차가 지날 무렵 옷걸이로 전락한 의자마냥 실험이 쌓여서 여러가지 툴을 사용해 나름 실험을 공유하기 편한 방법을 찾았다. (실험 결과가 여러 곳에 퍼져 있어서 다음 대회때 개선이 필요해 보인다.)
실험 그래프는 wandb에 연동해 시각화했고, 실험에 대한 자세한 내용(모델, 하이퍼파라미터 등등)은 issue에 작성한 후에 비교하기 쉽도록 notion table에 정리했다. kanban board의 각 항목에 issue를 남길 수 있어, 개발중인 각각의 기능의 issue부분에 실험 성능을 기록했다.
(중간에 wandb report도 사용해보았는데, 글자수 제한이 있어서 바로 다른 방식으로 갈아탔다.)
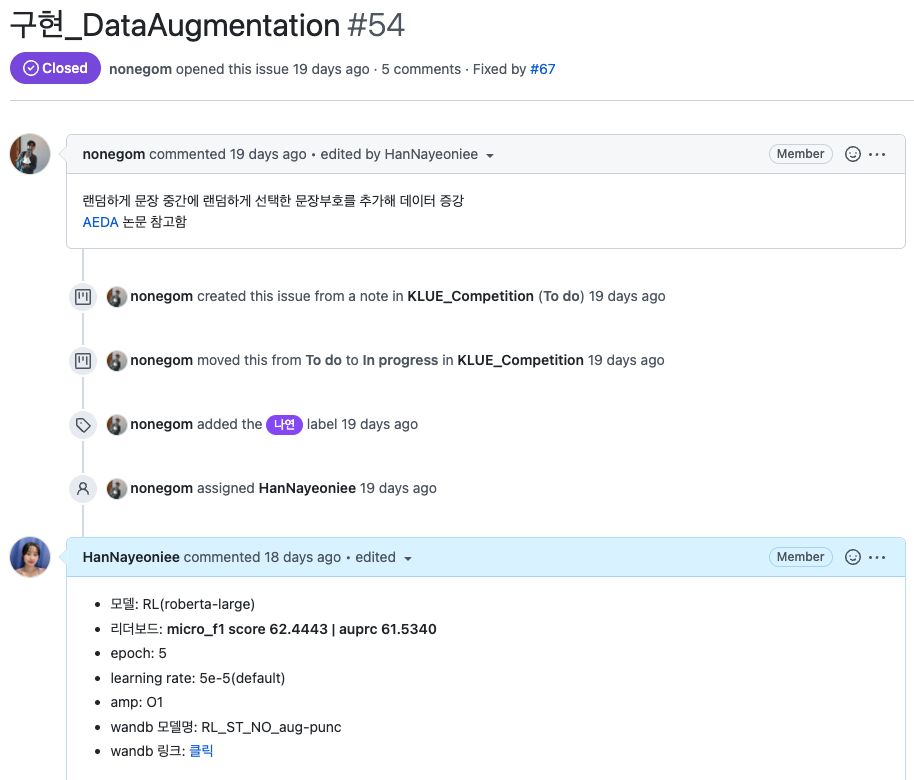
각 기능별 issue에 실험 결과를 정리
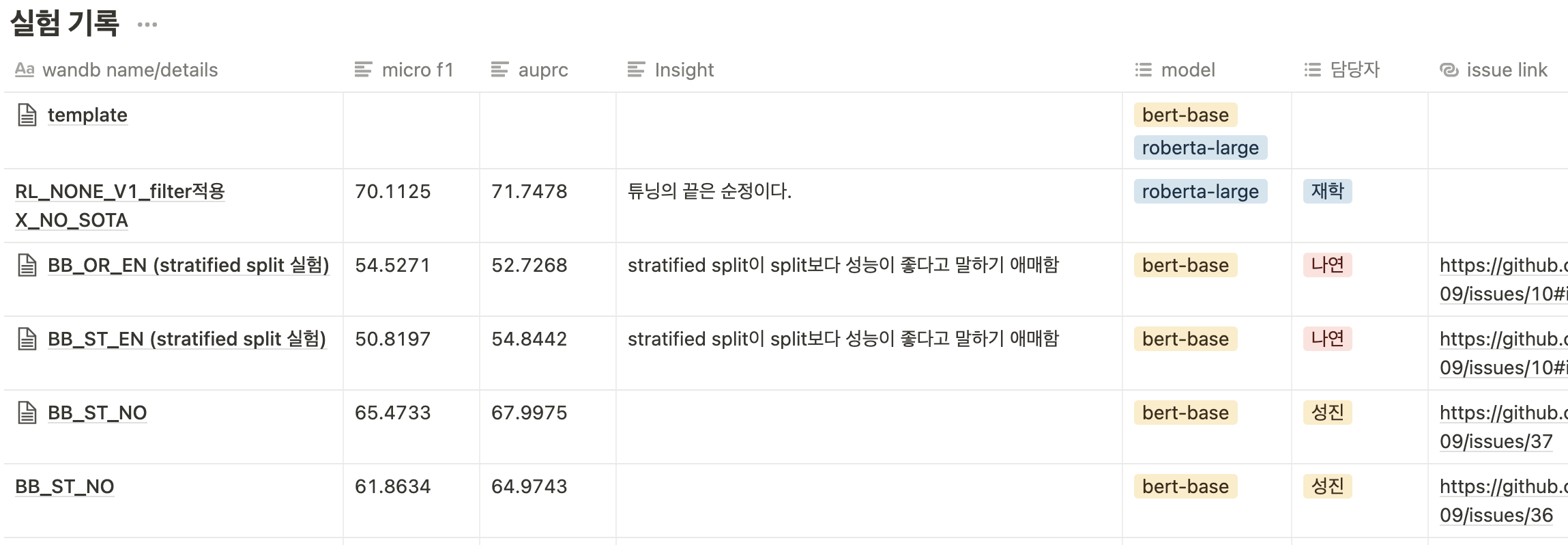
실험 결과를 한 눈에 볼 수 있도록 표로 정리(짧게 실험을 통해 얻은 인사이트도 넣었다)
미세먼지 꿀팁 - slack에 github, wandb 알람 연동
일일이 확인하기 귀찮은 부분들을 슬랙에 연동했다. wandb는 실험이 끝나면 끝났다고 알람이 울리고(실험 run이 끝난건지 중간에 오류나서 끝난건지도 알려준다), issue, pr, merge 관련 알람이 공유된다. 대회 후반부로 갈수록 코드를 수정하고 merge하는 경우가 많아졌는데, 팀원들이 올린 코드를 빠르게 확인 후 피드백하는데 도움이 되었다.
다음 대회에서는 매일 밤 리더보드 제출 여부를 투표하는 slackbot을 만들어 보려고 한다.
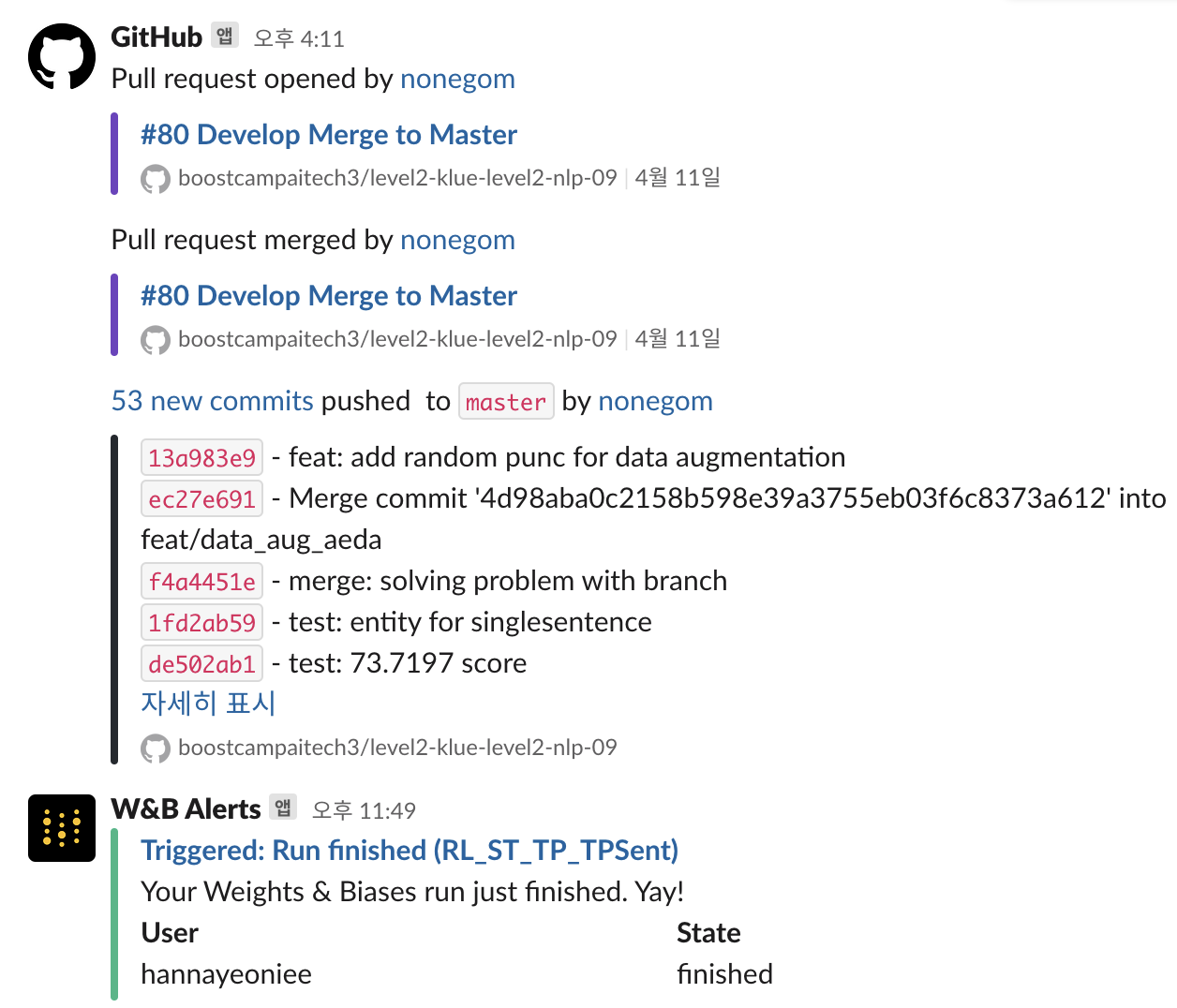
slack에 github, wandb 알람 연동
private에서 public으로 전환되서 기뻐하는 문어..?
2. 의견/아이디어 공유
이 부분은 팀 단위로도 성장했고 나 스스로도 성장한 부분이다.
지난 대회에서는 좋은 결과만 공유를 해야한다는 생각에 새로운 기법을 적용해도 성능 향상이 있으면 공유를 하고, 없으면 잘 공유를 하지 않았다. 내가 자주 공유하지 않아 아마 팀원들은 내가 프로젝트를 잘 쫓아오지 못하거나, 기여를 많이 안한다고 생각했을 것이다. 내가 우려하던 바는 동료 평가에서 실험 후기를 더 많이 공유했으면 좋겠다는 피드백을 받았다.
이번 대회에서는 ‘결과가 좋은 안좋든, 삽질하느라 아직 결과가 나오지 않아도 공유하자!’라는 마인드로 피어세션에 짧게 내 진행 상황을 공유했다. 결과에 상관없이 매일 공유하면서 팀원들은 내가 얼만큼 수행했는지 알 수 있고 나는 내가 이상한 곳에서 삽질하거나 방향을 잃었을 때 빠르게 되돌아 올 수 있어서 도움이 되었다.
시도했지만 성능향상에 실패한 부분 🥲
나는 팀에서 data augmentation 부분을 맡았는데, 사실 시도했던 모든 방법이 성능 향상에 도움이 되지 않았다. 이 원인으로는 2.5개를 꼽을 수 있다.
1. 꼼꼼함의 부재
크게 EDA, AEDA, entity swap, downsampling을 적용했다. EDA, AEDA는 깃허브 코드를 가져와 사용했고 entity swap, downsampling은 내가 구현했는데 짧고 간단해 코드를 이해하고 적용하는게 오래 걸리지 않았다.
우리 모델에 적용한 후에 실험을 진행했는데 파라미터 세팅을 동일하게 하지 않거나, 증강된 데이터를 확인하는 과정을 건너뛰어 정확한 성능 비교까지 오래 걸렸다. 중간 과정을 생략하고 실험을 진행해 결국에는 데이터 증강, 분포 확인 등등 하나씩 확인하면서 실험을 진행했다. 코드 가독성을 떨어뜨려 이번에는 argparser를 사용하지 않았는데, argparser를 사용한다면 파라미터 세팅을 깜빡하는 실수를 줄일 수 있지 않을까 생각한다.
2. task에 대한 이해 없이 무작정 시도한 augmentation
오피스 아워에서 공유해주신 NLP data augmentation 기법들과 개인적으로 찾아본 기법들을 위주로 시도했다. 객관적 기준을 토대로 가설 설정을 하고 실험을 진행하기 위해 논문을 많이 참고했는데 내가 간과한 부분은 논문과 내가 해결하려는 문제가 다를 수 있다는 점이다. 영어에 적용한 기법을 한국어에 적용하거나, NLI에 적용한 기법을 RE task에 적용하면서 내가 놓친 부분이 있지 않을까 생각한다.
논문 저자들을 비판하는건 아니지만, 생각해보면 나도 논문을 쓸 때 내 실험 결과를 더 돋보이게 하기 위해서 다양한 노력을 했다 ^)^ 내가 직접 실험해본 기법이 아니면 정말 ‘참고 자료'로만 사용해야 한다는 교훈을 얻었다.
3. 동료가 있었다면..?
이 부분은 구차한 변명이 될 것 같지만 내 마음의 평화 & 자기 합리화를 위해 작성해본다 ㅎㅅㅎ
대회가 끝나고 다른 팀들은 어떤 시도를 했는지 공유하는 시간이 있었는데 data augmentation 관련해서 굉장히 다양한 방법을 시도했고, 그만큼 많은 시간을 쏟았다. (kogpt로 데이터 생성하기, 영어/중국어 등 다양한 언어와 번역기로 back translation 적용하기)
data augmentation 관련 어려움을 내가 팀원들에게 더 공유하고, 강력하게 도움을 요청했다면 더 많은 시도를 할 수 있지 않았을까? 하는 아쉬움이 있다. (팀원들 모두 다른 부분을 맡아 진행했기 때문에 팀원 탓을 하는건 절대 아니다!)
시간이 더 주어진다면..? 🕰
Curriculum Learning
대회 마지막 주에 EXOBRAIN에서 RE task에 curriculum learning을 적용한 논문을 읽고 모델 변경, 데이터 증강, 하이퍼파라미터 튜닝과는 완전 다른 방식의 변경이라고 생각해 적용해보았다. (사실 대회 첫째주에 찾은 논문인데 무슨 말인지도 모르겠고 구현된 코드도 없어서 쿨하게 패스했다)
Curriculum Learning은 전체 데이터터셋을 1/n로 나누어 랜덤한 순서로 학습하지 않고 쉬운 데이터셋부터 어려운 데이터셋 순서로 학습시키는 아이디어이다. 논문의 저자들은 쉬운 데이터부터 학습시키면 모델 수렴 속도가 빨라진다고 주장한다. (사람이 영어 공부할 때 알파벳부터 시작해 실생활 영어를 공부하는 과정과 비슷하다고 생각하면 된다)
데이터셋을 1/n개로 나누어 난이도가 쉬운 문장부터 학습시키는 아이디어가 핵심인데,
- 데이터셋을 1/n개로 어떻게 나누지? 문장 단위로 나누라는 의미인가?
- 문장의 난이도는 어떻게 측정할 것인가?
이 두 가지가 내 의문이었다.
curriculum learning을 NLU에 적용한 논문 Curriculum Learning for Natural Language Understanding 에 자세한 내용이 나와있어 참고했다.
- 논문에 n=2로 설정해도 성능 향상이 있다고 나와있기도 하고, 문장 단위로 데이터를 나누는걸 구현하는데 어려움이 있어 전체 데이터셋을 이등분해 첫 번째 의문을 해결했다.
- 논문에서는 SQuAD 데이터셋으로 실험을 수행했으며, 다양한 난이도 측정 방법이 있지만 문단의 길이 & 질문의 길이 & 정답의 길이를 기준으로 난이도를 측정했다. SQuAD는 주어진 문단을 읽고 질문에 대한 정답을 구하는 task라서 3가지 길이를 고려해야 하지만, RE task는 입력 문장이 한 문장이니까 입력 문장의 길이를 난이도로 사용할 수 있다는 아이디어를 얻었다.
- train data_loader 부분에서 데이터셋을 문장 길이가 짧은 순서로 정렬하고, 정렬한 순서대로 데이터를 불러올 수 있도록 구현했다. 실험 결과 wandb 그래프 상에서 아주 약간 성능이 하락했다.
문장 길이가 짧은 문장이 더 학습하기 쉽다는 가정을 했는데, dynamic padding이 아닌 고정 길이로 padding을 했기 때문에 오히려 짧은 문장에는 의미 없는 [PAD] 토큰이 많이 들어가 학습을 더 어렵게 만든건 아닐까 추측한다. 추후에 dynamic padding을 적용하면 이러한 요인을 배제한 실험이 가능할 것이라 생각한다.
다른 팀에서 curriculum learning을 적용해 2-3점 높인 경험을 공유해주셨다. 일단 짧은 시간에 해당 코드를 구현했다는 점에 박수 세 번 짝👏 짝👏 짝👏 각 문장별로 난이도를 측정해 쉬운 문장부터 학습할 수 있도록 적용했다고 한다. 나처럼 지름길로 가지 않고 역시 정석적인 방법이 통한게 아닐까 싶다. 이 방법은 task에 상관없이 적용할 수 있는 방법이라서 다음 대회에서 적용해 보고 싶다.
다른 data augmentation 기법들
한국어 데이터를 증강하기 위해 한국어 → 외국어 → 한국어로 번역해 동일한 의미이지만 다른 표현을 가지는 문장을 만드는 back translation 기법이 있다. 이 방법은 뇌피셜로 번역기의 성능이 안 좋을 것 같기도 하고 막막해서시도하지 않았다.
하지만 대회 이후에 다른 팀 분들의 후기에서 이 기법을 많이 사용했을 알 수 있었다. 결과론적으로는 back translation이 성능 향상을 보인 팀은 아직 만나지 못해서 효율적으로(?) 대회를 진행했다고 볼 수 있지만, 시작하기도 전에 실패할까 두려워 너무 각재고 시도하지 않았던건 아닌가 반성하게 된다.
내가 생성한/변경한 문장은 동일한 의미인가?
EDA에서 제안한 4가지 방법 SR(synonym replacement), RI(random insertion), RS(random swap), RD(random deletion)을 적용했을 때 문장의 의미가 그대로인지 확인하는데 어려움이 있었다. 최종 발표 시간에 김성현 마스터님께서 원문 문장의 의미를 헤치지 않으면서 생성했는지 확인할 수 있는 paraprasing module을 알려주셨다. STS(Semantic Textual Similarity) dataset을 활용하면 문장 간의 유사도를 확인할 수 있다고 한다.
(이번 대회가 관계 추출이라서 논문에서 RE task 부분만 정독했는데 KLUE 논문에도 STS task가 있었다..!)
마무리
자세한 내용이 궁금하다먼 MnM조 github를 참고해 주세용~!

3개의 댓글

나연님의 회고록 잘 읽었습니다! 좋았고 성장했던 점들과 아쉬웠던 점들을 잘 나열해서 작성해주신 것 같아요! 조금 아쉬웠던 점은 문단 분리가 좀만 더 되었다면 읽는데 여유가 생기지 않았을까 싶습니다ㅎㅎ,,
나연님이 말씀해주셨던 것처럼 저 역시 데이터에 대한 본질적인 이해가 부족한 채로 무작정 코딩을 했던 것이 기억이 나네요ㅋㅋㅋㅋ
회고를 통해 아쉬운 점들을 많이 볼 수 있었는데 회고에서만 그치지 않고 나연님의 성장의 밑거름이 되기 위해 이번 대회에서는 먼저 목표 설정을 하고 충분한 이해 이후에 task를 진행해보면 더 의미있는 시간이 될 것이라 생각합니다! 너무 수고 많으셨어요!!
김남현입니다. 대회 종료 후 바로 회고록을 잘 적으셨네요. 저는 랩업 리포트와 TIL만 적었지 이번 대회에 대한 개인적인 회고록을 쓰지 않았어요..쓰려고 해도 이미 벌써 기억이 가물가물합니다. 아...큰일났네요. 대회에서 느끼셨던 중점적인 부분에 대해 꼼꼼하게 쓴 거 같습니다. 모든 부분에 나연님의 감정과 판단 및 근거가 들어 있어서 괜찮은 회고록이 탄생한 것 같아요. 나중에 다시 보기에도 좋은 글이 된 거 같습니다.
저희 팀도 깃허브 프로젝트를 써보면서 칸반 기능도 써봤는데요, 처음 몇 번 사용법 배우면서 써먹곤 대회 내내 거의 안 썼습니다. 귀찮더라구요. MRC 대회 때는 꼭 제대로 써보자고 팀원들끼리 다짐했어요. 사실 저는 vscode로 서버에 원격접속하구 깃허브랑 연동해서 branch 관리하는 것도 어색하고 어렵더라구요. 언젠가는 익숙해지겠죠..?
그리고 저희도 슬랙에 wandb 알림 연동 했었지만 한 일주일 정도 하다가 그만두었습니다. 알림이 지나치게 많이 생성되는 바람에 정작 중요한 대화 내용을 찾기 어려울 정도라서 알림 해제하기로 합의했었어요.
저희 팀은 빠르게 1위 찍고 나서 거의 2주 가량을 data augmentation에 매진했는데 성과가 기대했던만큼 안 나와서 아쉬웠어요. 심지어 마지막날에 1위 자리를 뺏겨서 더 아쉽더라구요. 이럴 줄 알았으면 모델에 조금 더 집중해서 앙상블을 더 풍부하게 해볼 걸 그랬어요. 특히 모델 관련해서는 제 기여도가 낮아서 많이 자책했습니다.😥
"private에서 public으로 전환되서 기뻐하는 문어..?" 이 말 귀엽네요.