데몬셋
stop을 하거나 시스템을 끄기전까지 계속해서 실행하는 앱 -> 이걸 제어하는게 서비스데몬
노드마다 하나씩 파드 배치 -> 데몬셋은 모든(일부) 노드 파드의 사본을 실행 -> 템플릿 실행
데몬셋은 DS -> 복제본이라는 개념은 없음 반드시 하나의 노드에 하나씩
무조건적으로 하나씩 있음 -> 분산을 보장
노드에서 작업을 해야하는 앱들에서 사용
EX) 스토리지 어플리케이션
워커노드에 스토리지(디스크) 파드에게 제공하기 위해서 그냥 제공 가능? --> 그건 아님
kubernetes가 연결할 수 있는 컨테이너 스토리지 인터페이스라는게 있음 CRI CNI CSI
인터페이스를 통해 접근해야함 -> Rook ceph 사용
이런애들을 관리하기 위해선 데몬이 필요함(스토리지를 관리할)
RS와의 차이
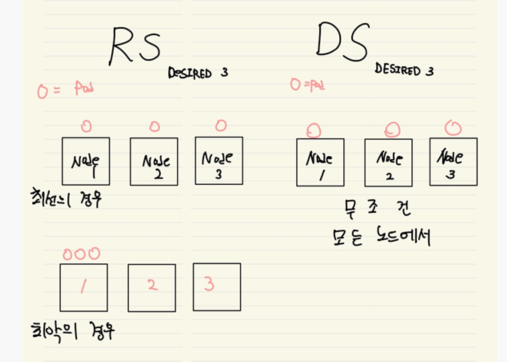
어느 노드에 파드가 배치될지 알 수없는 RS와 달리 DS는 모든 노드에 파드를 하나씩 배포함
노드3이 문제가 생기면 RS 입장에선 복제본 하나를 잃은 것이므로 1, 2에 하나가 추가로 생성 됨
하지만, 데몬셋은 노드3에 문제가 생기더라도 복제본이 아니기 때문에 노드3의 파드를 다른 노드에서 생성하지 않음
노드가 제거 되면 자동으로 가비지 컬렉터로 수집
ds.spec
vagrant@k8s-node1:~$ kubectl explain ds.spec
KIND: DaemonSet
VERSION: apps/v1
RESOURCE: spec <Object>
FIELDS:
minReadySeconds <integer>
revisionHistoryLimit <integer>
selector <Object> -required-
# 데몬셋이 관리하는 파드에 대한 셀렉터
template <Object> -required-
# 생성될 파드의 spec을 정의
updateStrategy <Object>
An update strategy to replace existing DaemonSet pods with new pods.ds.spec.selector
vagrant@k8s-node1:~$ kubectl explain ds.spec.selector
KIND: DaemonSet
VERSION: apps/v1
RESOURCE: selector <Object>
FIELDS:
matchExpressions <[]Object>
matchExpressions is a list of label selector requirements. The requirements
are ANDed. ==> 셀렉터와 레이블이 모두 다 일치해야함
matchLabels <map[string]string>
... The requirements are ANDed. ==> 셀렉터와 레이블이 모두 다 일치해야함myweb-ds.yaml
파드를 관리하는 데몬셋을 생성하는 yaml파일
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: myweb-ds
spec:
selector:
matchExpressions:
- key: app
operator: In
values:
- myweb
- key: env
operator: Exists
template:
metadata:
labels:
app: myweb
env: dev
spec:
containers:
- name: myweb
image: ghcr.io/c1t1d0s7/go-myweb
ports:
- containerPort: 8080
protocol: TCPkubectl get ds
vagrant@k8s-node1:~/controller/ds$ kubectl get ds
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
myweb-ds 3 3 3 3 3 <none> 12s이미지 자체를 업데이트 하는 경우에 다음 필드 참조
UP-TO-DATE : 최신 버전의 이미지를 사용하는 파드의 수
AVAILABLE : 현재 사용가능한 컨테이너의 수
노드 추가/제거 시 데몬셋의 변경
cd ~/kubespray노드 제거
ansible-playbook -i inventory/mycluster/inventory.ini remove-node.yml -b --extra-vars="node=node3" --extra-vars reset_nodes=true노드 제거 시
vagrant@k8s-node1:~/controller/ds$ kubectl get ds
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
myweb-ds 2 2 2 2 2 <none> 9m데몬셋 변경
노드 추가
ansible-playbook -i inventory/mycluster/inventory.ini scale.yml -bJobs
데몬형태로 앱을 실행하는 것
시작이 있고 끝이 잇는 앱, 종료되는
잡은 성공적으로 종료될때까지 계속해서 파드를 실행
RC RS DS Deployment Statefulet 시작이 있으면 끝이 없는
Job CronJob 끝이 있는 종료를 안전하게 보장한다
시작-->완료
apiVersion: batch/v1 -> batch 작업 => 대량의 작업 1년에 순서가 있는 작업
kind: Job
metadata:
name: mypi
spec:
template:
spec:
containers:
- image: perl
name: mypi
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: OnFailurejobs.spec
vagrant@k8s-node1:~/controller/ds$ kubectl explain jobs.spec
KIND: Job
VERSION: batch/v1
RESOURCE: spec <Object>
FIELDS:
activeDeadlineSeconds <integer> -> 애플리케이션이 실행될 수 있는 시간 지정
일정시간이 걸리면 이 작업을 그만해라
backoffLimit <integer> job이나 cronjob에만 지정해져있음
오류날 경우에 계속적으로 반복 점점 주기가 늘어남
Job은 6번의 재시도만 허가, 6번 실패시 에러로 판단
completionMode <string> -> 완료 횟수
N번이 작업이 완료되었을 때 완전히 종료
completions <integer>
manualSelector <boolean>
parallelism <integer> -> 병렬 개수
앱 하나가 처리를 병렬적으로 작업
selector <Object>
suspend <boolean> 일시중지
kubect edit job mypi에서 suspend부분 true로 하면 일시중지가능
template <Object> -required-
ttlSecondsAfterFinished <integer> -> 컨트롤러 및 파드 삭제
특정 시간이 지나면 종료 아래 항목 대신 자동적으로 삭제 지정가능
파드가 끝나도 자동으로 파드를 삭제하지 않음
자동으로 지우면 문제가 발생함 -> 파드를 지우면 파드의 로그가 사라짐
지워버리면 표준출력 로그 확인할 수가 없음 -> 로그를 다른곳에 저장jobs.spec.template.spec
restartPolicy <string>
Restart policy for all containers within the pod. One of Always, OnFailure,
Never. Default to Always. -> Job은 끝이 있기 때문에 재시작 정책이 always라면 컨테이너가 실행되고 끝나고를 무한 반복하기 때문에 OnFailure, Never로 재시작 정책을 정해야만 실행가능잡 컨트롤러의 레이블
파드 템플릿의 레이블 / 잡 컨트롤러의 레이블 셀렉터는 지정하지 않는다.
-> 잘못된 매핑으로 기존의 파드를 종료하지 않게 하기 위함
파드의 종료 및 삭제
apiVersion: batch/v1
kind: Job
metadata:
name: mypi
spec:
template:
spec:
containers:
- image: perl
name: mypi
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: OnFailure
ttlSecondsAfterFinished: 10작업의 병렬 처리
apiVersion: batch/v1
kind: Job
metadata:
name: mypi-para
spec:
completions: 3
parallelism: 3
template:
spec:
containers:
- image: perl
name: mypi
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(1500)"]
restartPolicy: OnFailureCronJob
잡이긴 한데 주기적으로 동작하는, 컨테이너 잡을 주기적으로 실행시키기 위함
비교적 최근에 스테이블 되었음
다른 버전의 필드 확인 --api-version옵션
kubectl explain cj --api-version=batch/v1beta1cj.sepc
vagrant@k8s-node1:~/controller/ds$ kubectl explain cj.spec
KIND: CronJob
VERSION: batch/v1
RESOURCE: spec <Object>
FIELDS:
concurrencyPolicy <string>
- Allow (default): 동시 작업 가능
- Forbid: 동시 작업 금지(이전 작업이 계속 실행 됨)
- Replace: 교체(이전 작업은 종료되고 새로운 작업 실행)
-> 실패 카운팅 100번이 넘으면 더 이상 작업이 진행되지 않음
failedJobsHistoryLimit <integer>
작업이 실행되고 실패 된것 1개만 기억. Defaults to 1.
successfulJobsHistoryLimit <integer>
성공한 작업의 히스토리의 제한 3개가 디폴트. 정상적으로 끝난 작업은 3개까지 가지고 있을 수 있음 -> 크론잡은 최대 4개 작업까지 가지고 있을수 있음
startingDeadlineSeconds <integer>
스케줄링 되는 시점에서 과거로부터 실패한 작업이 있는지 없는지 체크
concurrencyPolicy와 연관이 있음
suspend <boolean>
잡과 같음apiVersion: batch/v1
kind: CronJob
metadata:
name: sleep-cj
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: sleep
image: ubuntu
command: ["sleep", "80"]
restartPolicy: OnFailure
#concurrencyPolicy: ( Allow | Forbid | Replace )https://crontab.guru/
크론 문법 검증
Service & DNS
https://kubernetes.io/ko/docs/concepts/services-networking/
파드집합에서 (컨트롤러 사용) 실행중인 앱을 네트워크 서비스로 노출하는 방법(expose)
고유한 IP주소 DNS명을 부여하고, 기본적으로 로드밸런서의 기능을 하고 있음
파드를 보게 되면 RS만들면 파드 복제본 3개를 만들고 파드마다 고유한 IP만들어짐
클라이언트 입장에선 누구를 어떻게 찾아가야하나 모르니까 -> 서비스 리소스를 만듬 각 파드랑 연결이 됨 서비승에는 셀렉터가있고 파드는 레이블을 가지고 있다 서비스라는 녀석은 DNS 이름이 부여가 됨
이름이 부여가 되기 위해서는 쿠버 dns라는 애드온이 있어야함 -> 애드온 영역이지만 무조건 설치가 됨
COREDNS
svc.spec
vagrant@k8s-node1:~/controller/cj$ kubectl explain svc.spec
ports <[]Object>
서비스의 포트, 쉽게말하면 로드밸런서 VM이 있을때 로드밸런서에접속할포트가 있고 로드밸런서 백엔드에 vm에 포트가 잇는데 포트는 달라도 댐
이포트는 서비스의 포트 -> 클라이언트가 접속해야하는 포트 -> 컨테이너와 연결되는 포트는 전혀다른 개념
clusterIP <string>
서비스의 IP직접할당, 사용하지 않음 안함 kube-dns 잇기전에 이름이 없기때문에 IP고정했었음
selector <map[string]string>
이 서비스가 연결하기 위한 파드 레이블을 지정하는게 셀렉터다
type <string>
ExternalName, ClusterIP(클러스터 내부), NodePort(클러스터 외부), and LoadBalancer.(클러스터 외부)
svc.spec.ports
vagrant@k8s-node1:~/controller/ds$ kubectl explain svc.spec.ports
KIND: Service
VERSION: v1
RESOURCE: ports <[]Object>
DESCRIPTION:
The list of ports that are exposed by this service. More info:
https://kubernetes.io/docs/concepts/services-networking/service/#virtual-ips-and-service-proxies
ServicePort contains information on service's port.
FIELDS:
appProtocol <string>
name <string>
nodePort <integer>
port <integer> -required-
The port that will be exposed by this service.
protocol <string>
TCP, UDP, SCTP
targetPort <string>
서비스가 있고 컨테이너의포트 파드의포트가 타겟 포트vi kubespray/inventory/mycluster/group_vars/k8s_cluster/k8s-cluster.yml 72 # Kubernetes internal network for services, unused block of space. 73 kube_service_addresses: ~/18 서비스의 네트워크 대역 74 75 # internal network. When used, it will assign IP 76 # addresses from this range to individual pods. 77 # This network must be unused in your network infrastructure! 78 kube_pods_subnet: ~/18 파드의 네트워크 대역 88 # - kubelet_max_pods: 110 쿠베렛 하나당 110개의 파드로 제한이 걸림 한노드당 110개를 넘어갈수없음
Endpoints
서비스 만들면 서비스이름과 같은 엔드포인트가 만들어짐
서비스 이름과 같은 엔드포인트가 실제 파드들의 정보를 가지고 잇음
myweb-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: myweb-svc
spec:
selector: # 파드 셀렉터
app: web
ports:
- port: 80 # 서비스 포트
targetPort: 8080 # 타켓(파드 포트)Endpoints 확인
kubectl get svc myweb-svckubectl describe svc myweb-svckubectl get endpoint myweb-svckubectl create -f . # 현재 디렉토리에 있는 모든 yaml 실행
아래 이미지는 네트워크관한 명령어를 설치한 테스트하는 이미지
kubectl run nettool -it --image ghcr.io/c1t1d0s7/network-multitool
> curl x.x.x.x(서비스 리소스의 ClusterIP)
> host myweb-svc 질의하면 ip가 나옴
> curl myweb-svckubelet은 왜 pod가 아니라 서비스일까?
시스템이 쿠버네티스가 되려면 apiserver, cm, sch, etcd도 있어야 함 => 쿠버네티스에 의해 파드도 관리 서비스도 관리할 것인데 자기 자신(쿠버네티스)은 누가 띄울것인가? -> 나 (apiserver 등...)파드로 되어있고 파드를 띄어야 함 -> kubelet의 띄움
kubelet은 init시 실행되어 apiserver 등 파드를 실행하는데 kubelet 파드면 kubelet을 또 누가 실행하는가?-> kubelet은 서비스vagrant@k8s-node1:~$ kubectl get pods -A NAMESPACE NAME READY STATUS RESTARTS AGE kube-system calico-kube-controllers-5788f6558-fprlg 1/1 Running 1 (10h ago) 13h kube-system calico-node-f9mmz 1/1 Running 2 (13h ago) 3d6h kube-system calico-node-g6p7p 1/1 Running 3 (10h ago) 3d6h kube-system calico-node-vdlhp 1/1 Running 2 (13h ago) 3d6h kube-system coredns-8474476ff8-4mq4l 1/1 Running 4 (10h ago) 3d6h kube-system coredns-8474476ff8-sd4w7 1/1 Running 0 13h kube-system dns-autoscaler-5ffdc7f89d-2ppkn 1/1 Running 3 (10h ago) 3d6h kube-system kube-apiserver-node1 1/1 Running 4 (10h ago) 3d6h kube-system kube-controller-manager-node1 1/1 Running 5 (10h ago) 3d6h kube-system kube-proxy-dbrcd 1/1 Running 2 (13h ago) 3d6h kube-system kube-proxy-r4rkh 1/1 Running 2 (13h ago) 3d6h kube-system kube-proxy-rgcwn 1/1 Running 3 (10h ago) 3d6h kube-system kube-scheduler-node1 1/1 Running 5 (10h ago) 3d6h kube-system nginx-proxy-node2 1/1 Running 2 (13h ago) 3d6h kube-system nginx-proxy-node3 1/1 Running 2 (13h ago) 3d6h kube-system nodelocaldns-dzxv6 1/1 Running 3 (10h ago) 3d6h kube-system nodelocaldns-gx5x4 1/1 Running 2 (13h ago) 3d6h kube-system nodelocaldns-xwh2t 1/1 Running 2 (13h ago) 3d6h클러스터에 필요한 apiserver, controller-manager등의 파드를 관리할 서비스가 필요 -> kubelet
실제로 init 시 kubelet 은vagrant@k8s-node1:~$ ls /etc/kubernetes/manifests(구체적인 리소스 설정파일)/ kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml 파일 생성시 파드 생성, 삭제시 파드 삭제yaml파일을 읽어 정적파드들을 실행
정적파드 <-쿠버네티스가 관리하는 파드가 아니라 kubelet이 관리하는 파드
kubectl get po -A실행 시, 호스트이름 붙어있는거 다 스태틱 파드다 -> kubelet이 실행, 관리실제로 init은 클러스터 부트스트래핑이라 할 정도로 운영체제의 부팅과 비슷
https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm-init/#init-workflow
