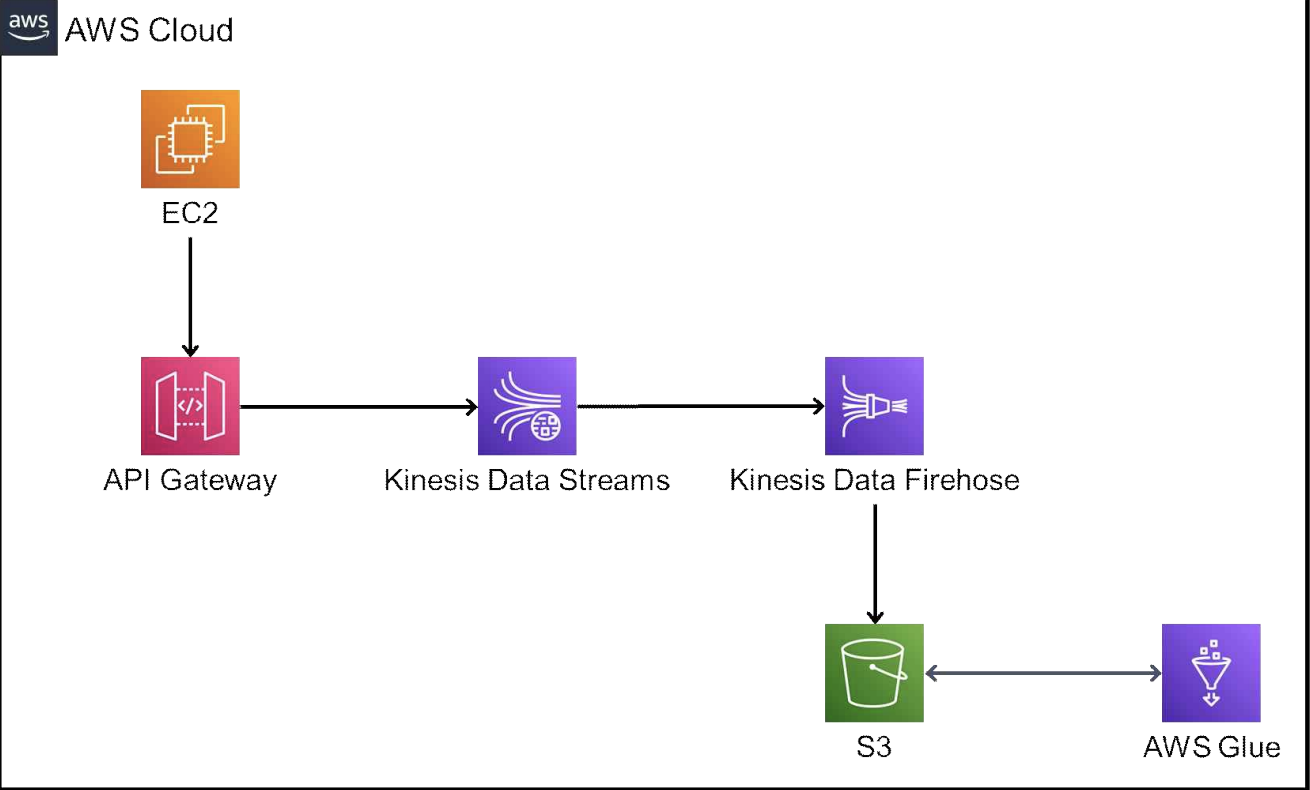
2과제 아키텍처인데 대충 예상해보면..
1. EC2에서 API Gateway로 curl 이나 데이터 등을 날림
2. 그러면 api gateway를 통해서 data streams로 이동
3. data firehose 에서 s3로 그 데이터들이 저장.
4. Glue 와 s3 왔다갔다하면서 DB 테이블만들고 저장 및 불러오기?
같은 느낌인 것 같음. 그래서 그 동안의 실습글들을 바탕으로 이 흐름으로 실습을 진행해보겠음.
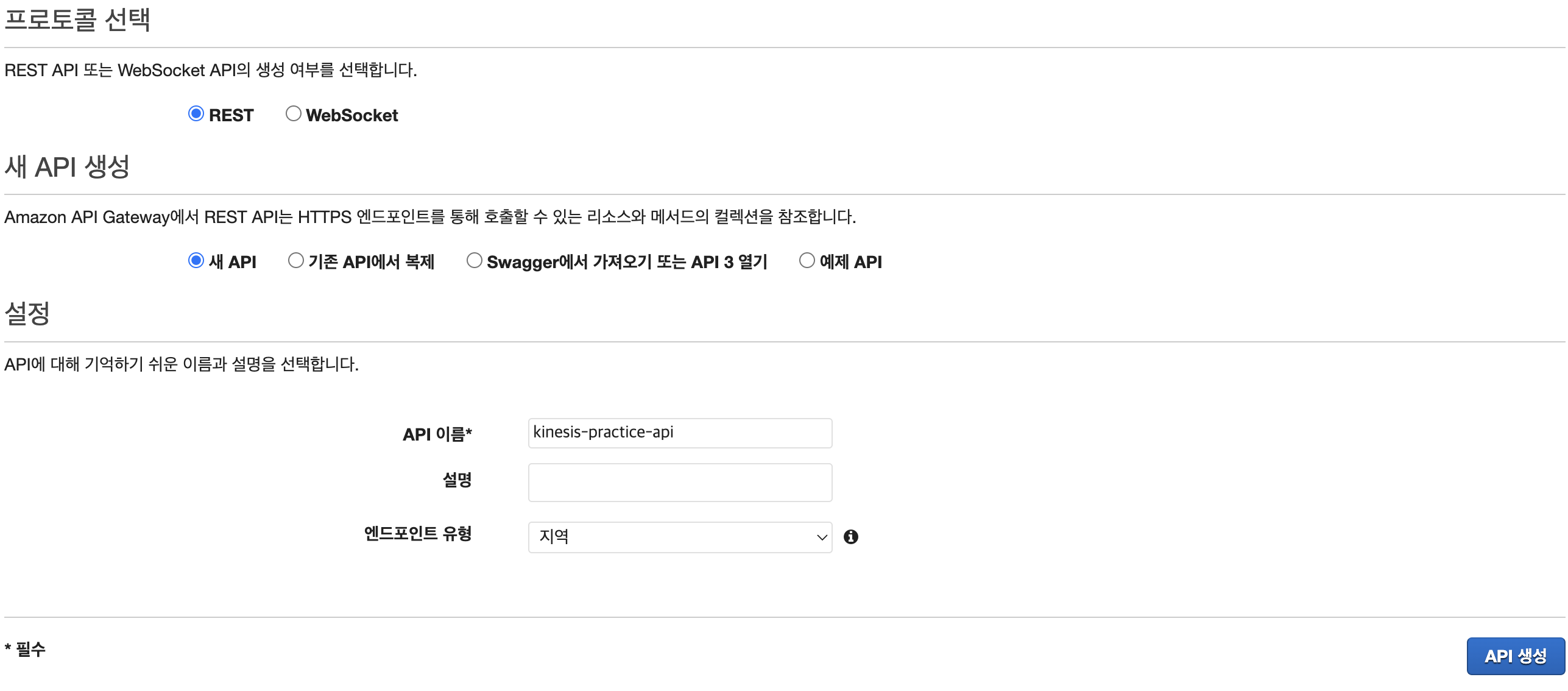
API Gateway
우선 API Gateway부터 생성해주도록하자.
종류는 REST 프로토콜, 이름은 알잘딱 지어주고 API 생성을 눌러주자.
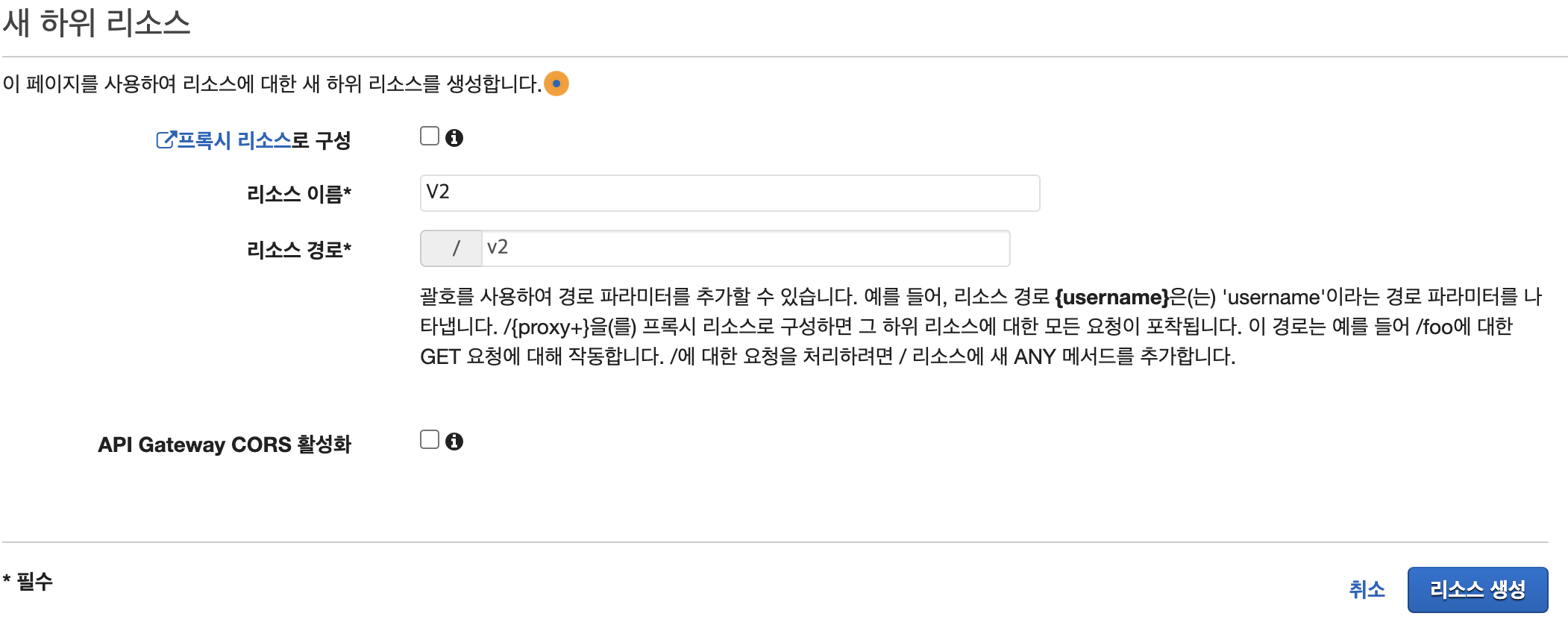
리소스 생성을 눌러주자. 리소스의 이름은 알잘딱 지어주는데 필자는 v2 라고 이름 지었다.
메소드 생성을 하기 이전 아래와 같은 IAM룰을 생성해주자. Kinesis Full Access가 가능한 API Gateway Role이다. ARN을 복사해두자.
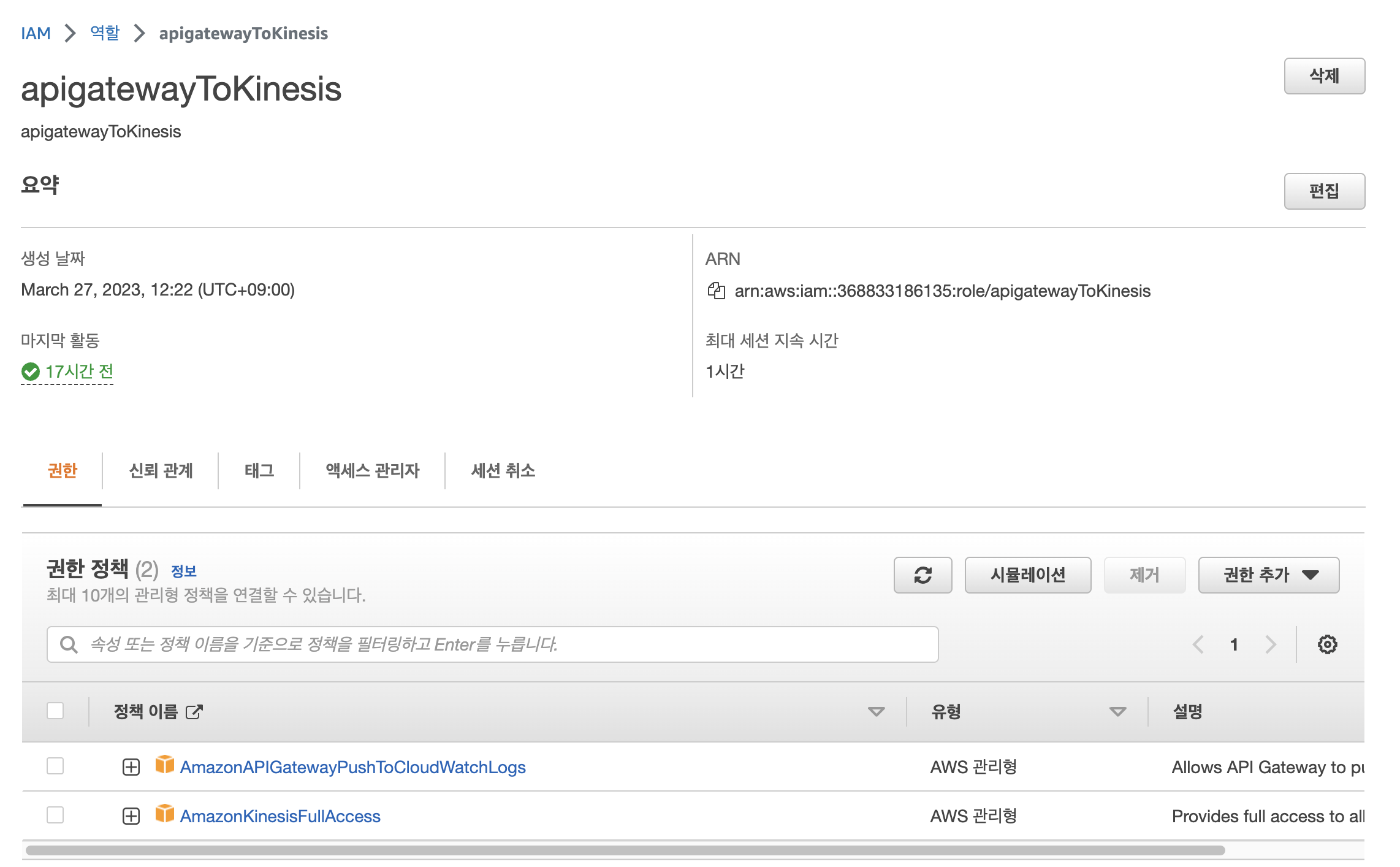
다시 API Gateway로 돌아가서 메소드 생성 -> POST 이후 아래 사진과 같이 설정을 해준다. 이떄 IAM에서 복사했단 ARN을 붙여넣어준다.
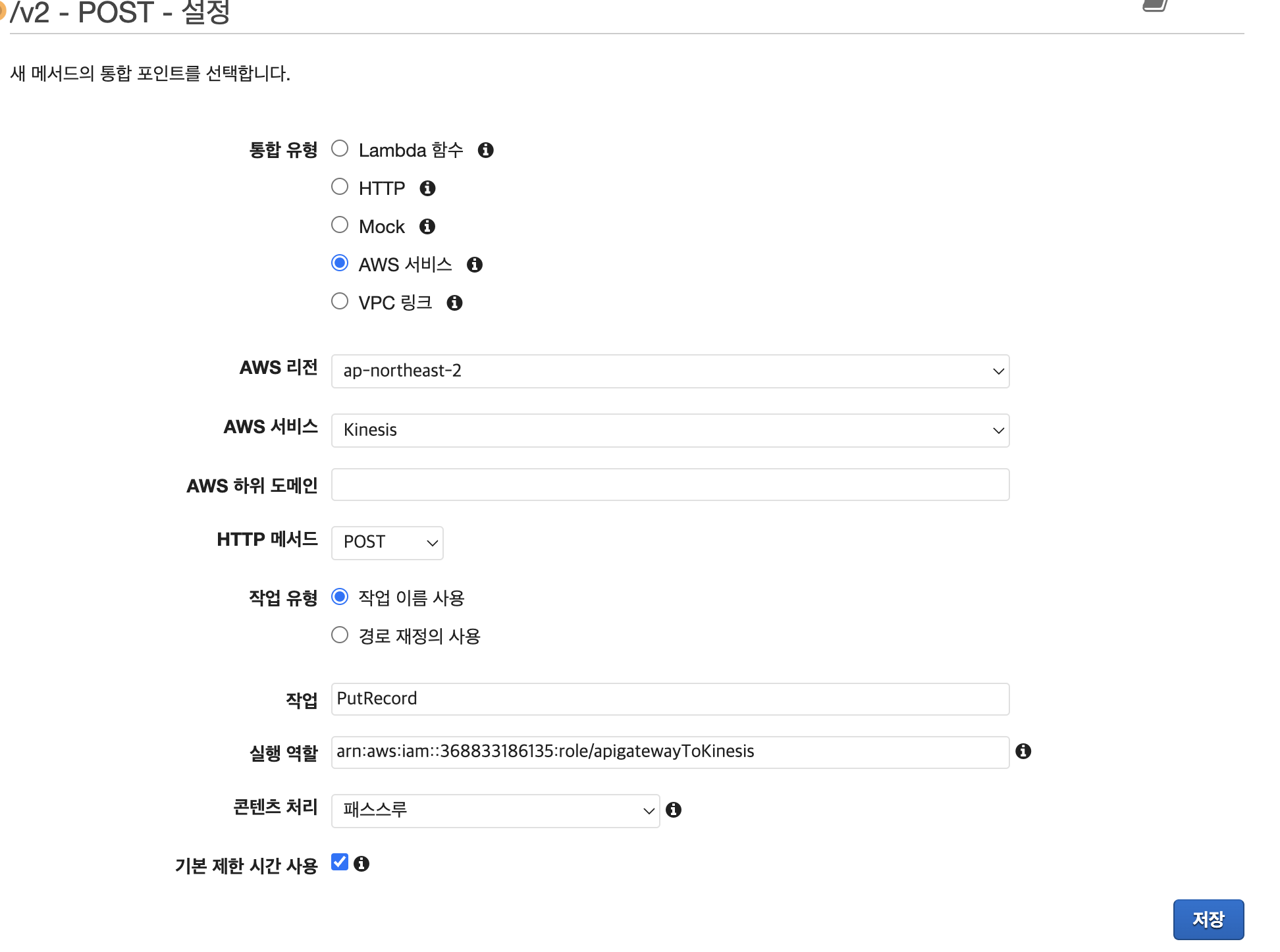
이후 저장을 누르고 통합 요청으로 가서 쭉쭉 내린다음 HTTP 헤더를 설정해준다.

이후 바로 아래에 있는 매핑 템플릿을 설정해줘야하는데 content-type 을 apllication/json 으로 설정한 뒤, 코드를 작성해준다.
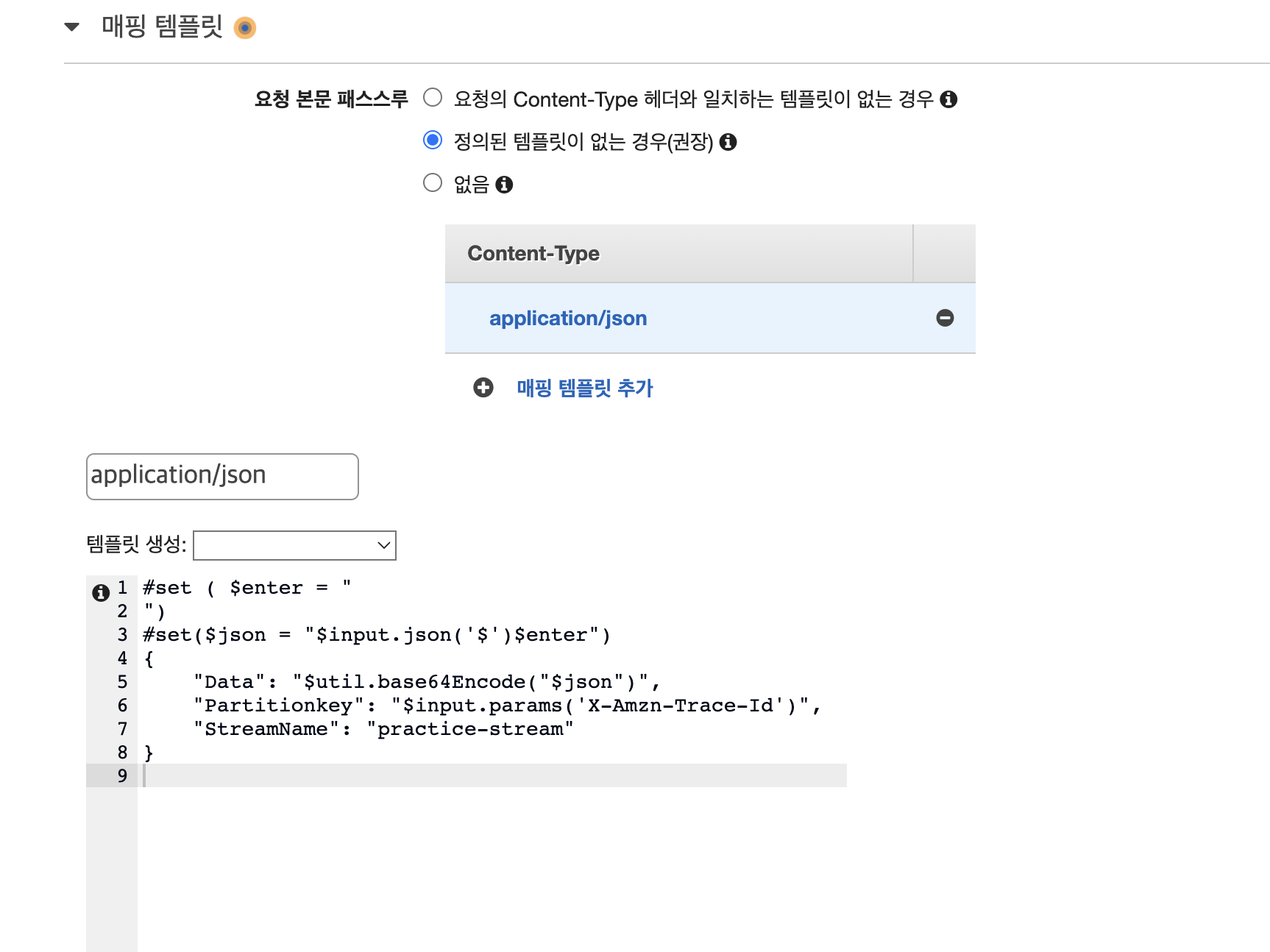
이후 API배포를 눌러 배포 스테이지 이름을 정한 뒤 배포해준다.
이런식으로 URL이 보인다면 성공적으로 배포가 된 것이다.
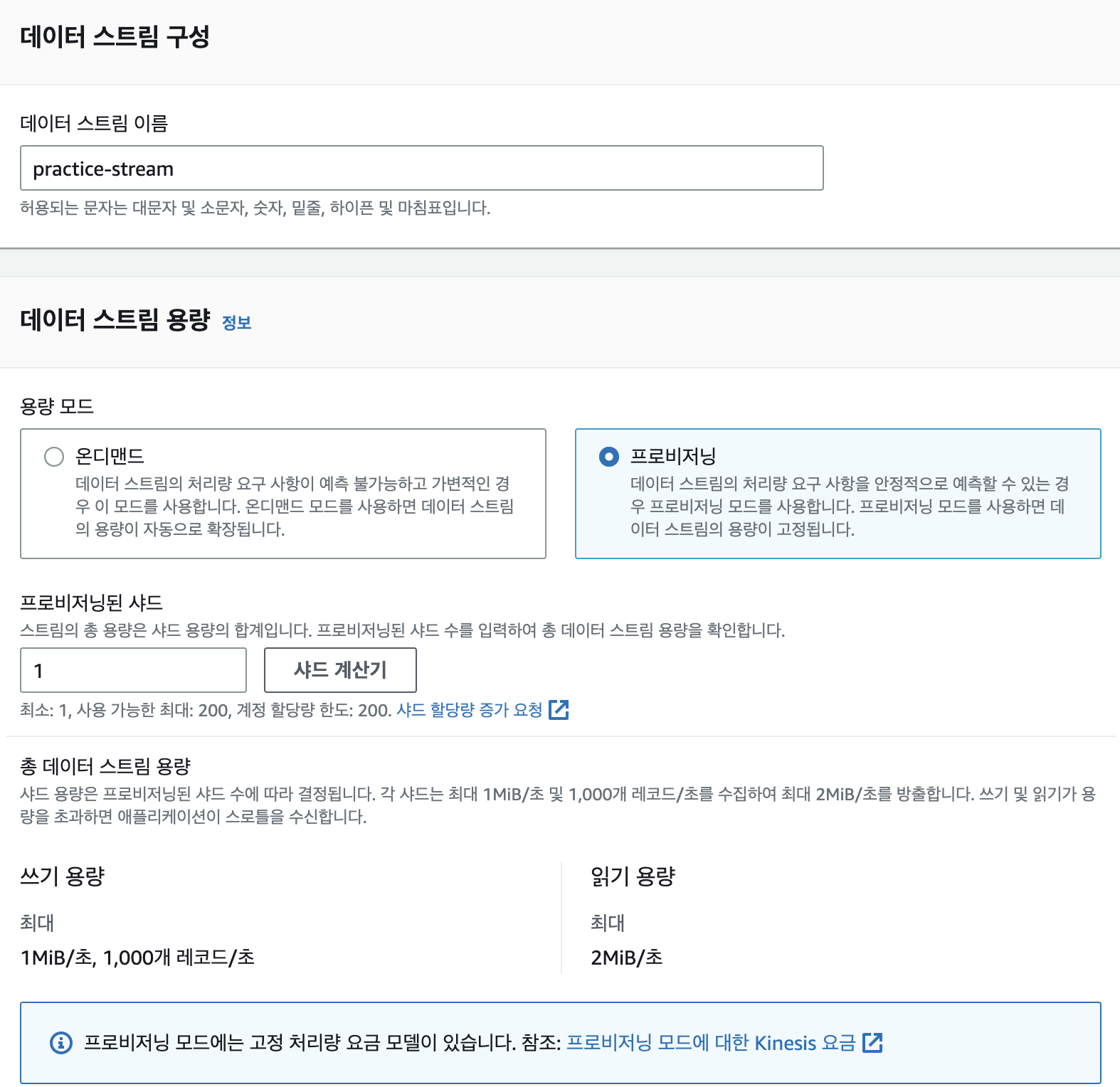
Kinesis Data Streams
아까 코드에서 작성한 데이터 스트림 이름과 똑같은 이름, 프로비저닝으로 Kinesis Data Stream을 생성해준다.
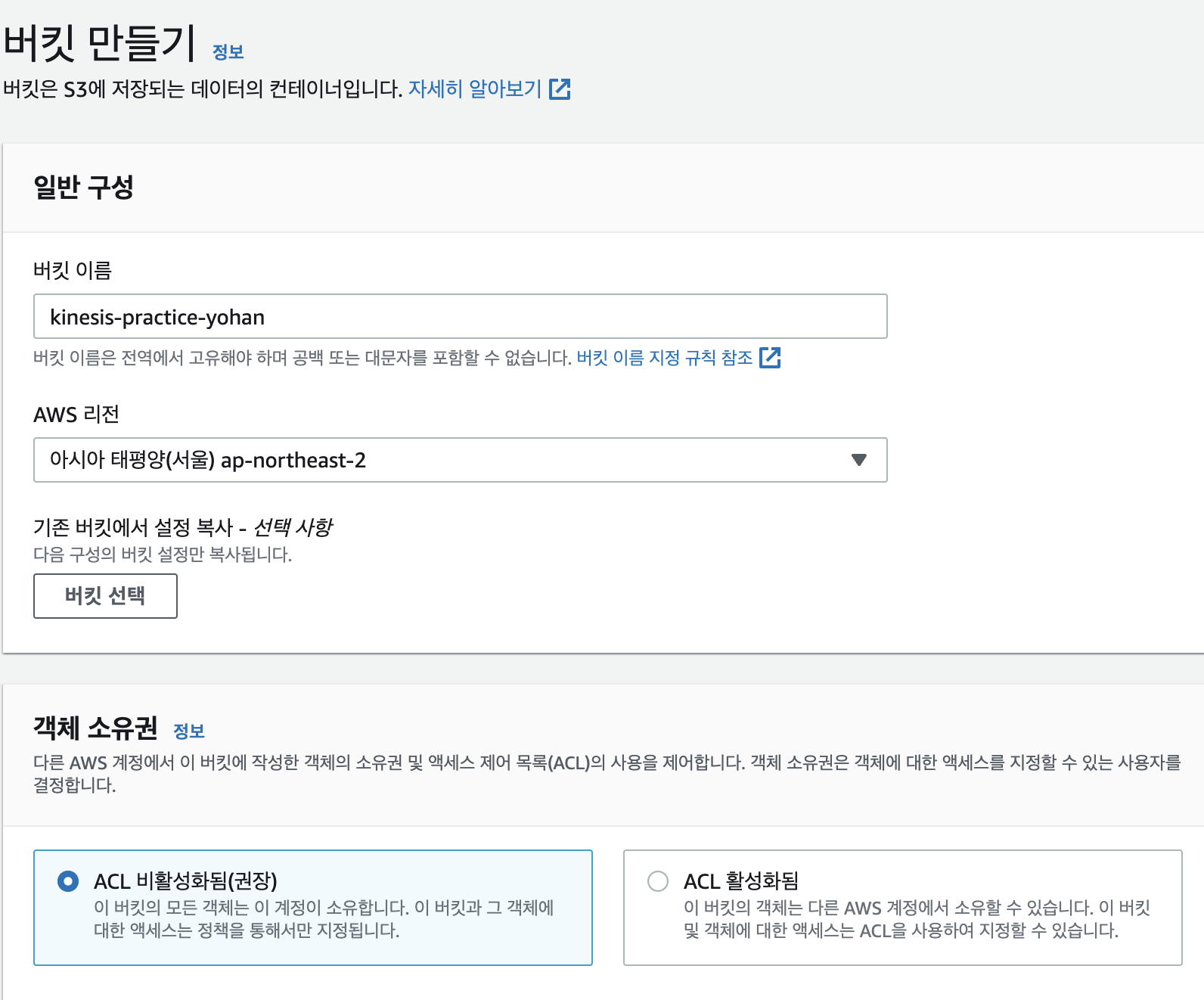
S3
버킷 이름을 대충 지어주고 S3 버킷을 생성해준다.
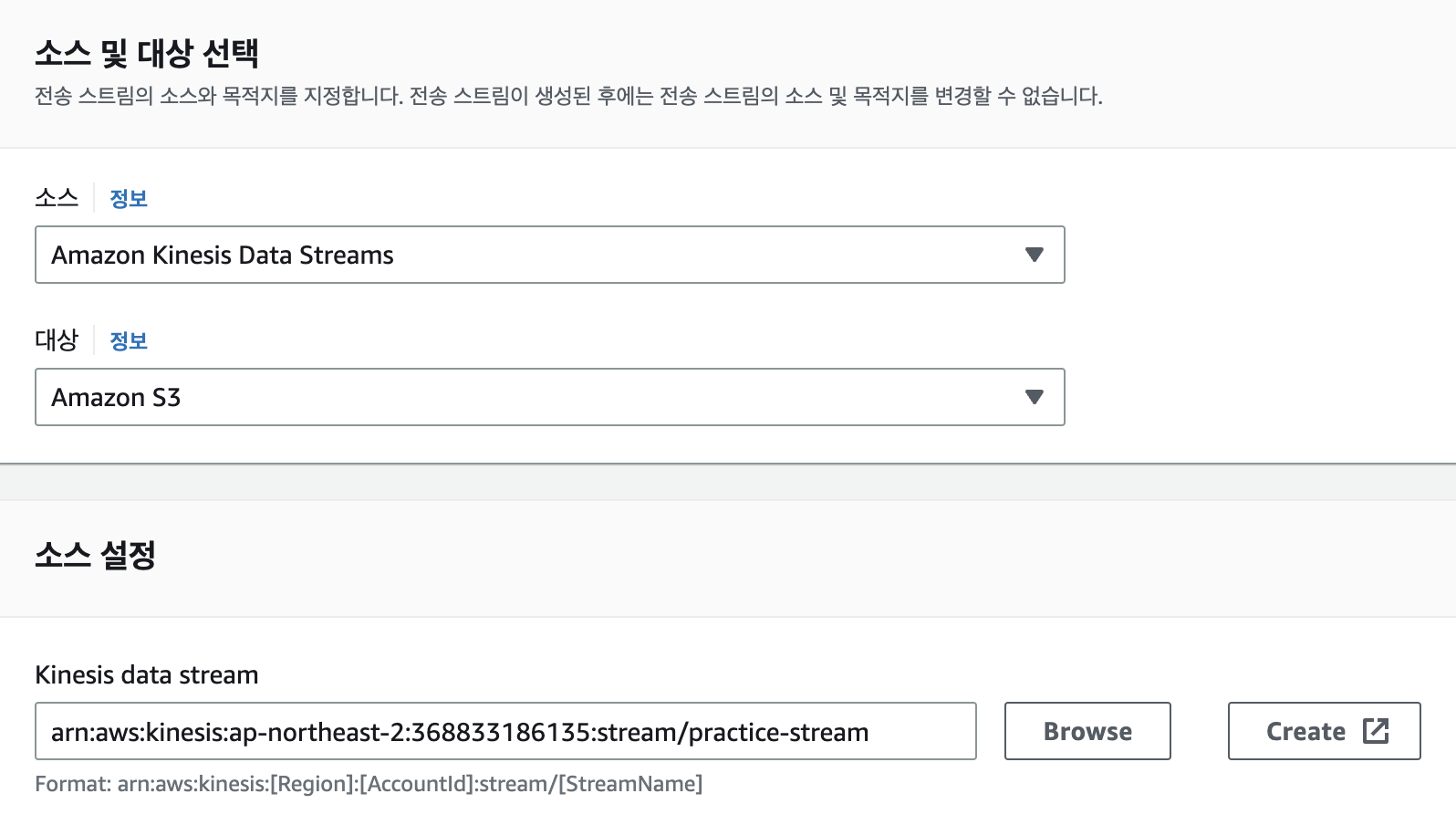
Kinesis Data Firehose
소스는 아까만든 DataStream, 대상은 S3로 지정. 소스 설정과 대상 설정은 만든 Datastream과 s3 버킷을 골라주고 Kinesis Data Firehose를 생성해준다.
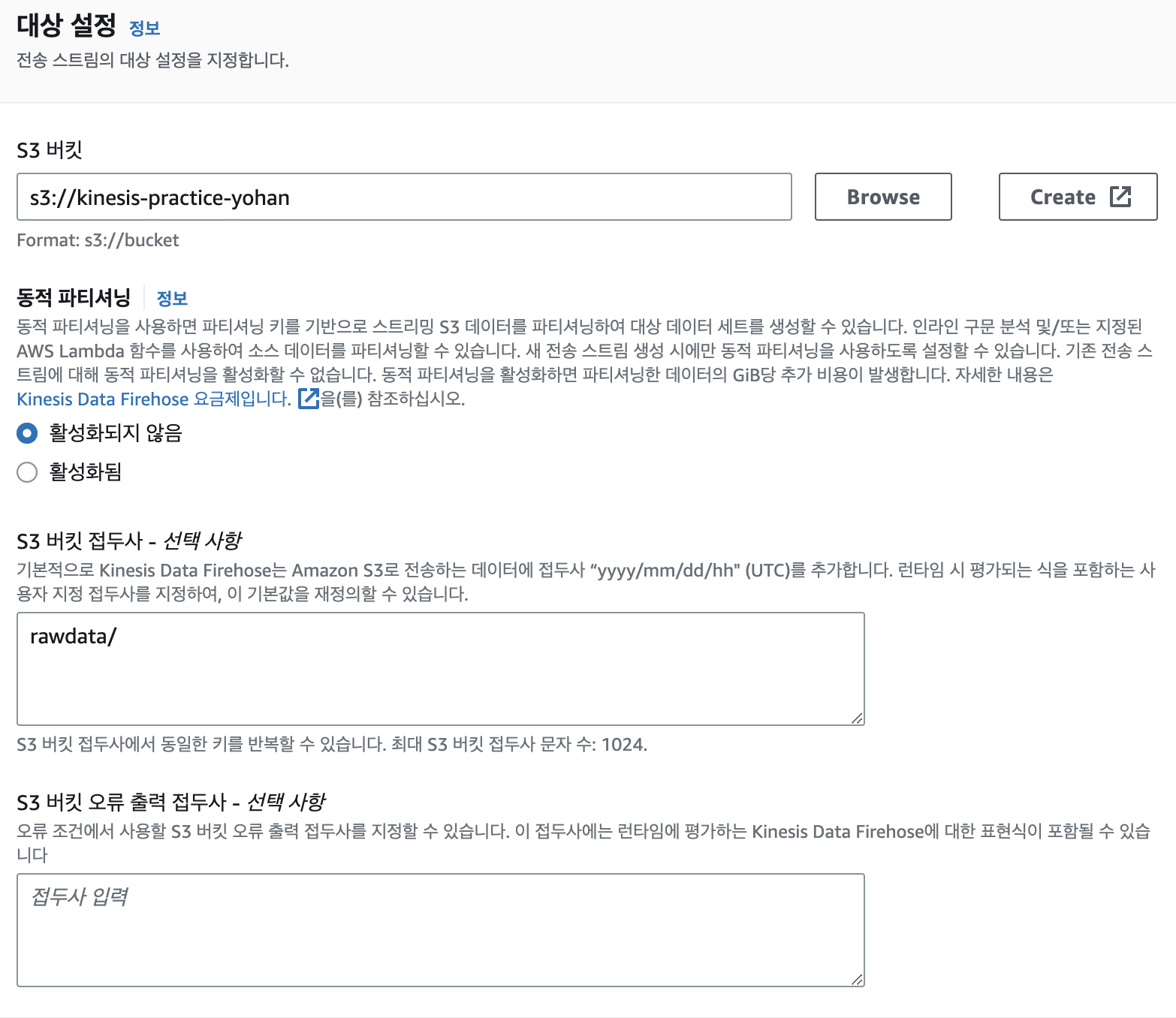
이제 서비스들은 다 생성했고 생성한 서비스들이 서로 연계해서 잘 돌아가는지 확인해보자.
EC2
ec2를 하나 만들고 알잘딱 접속해주자.
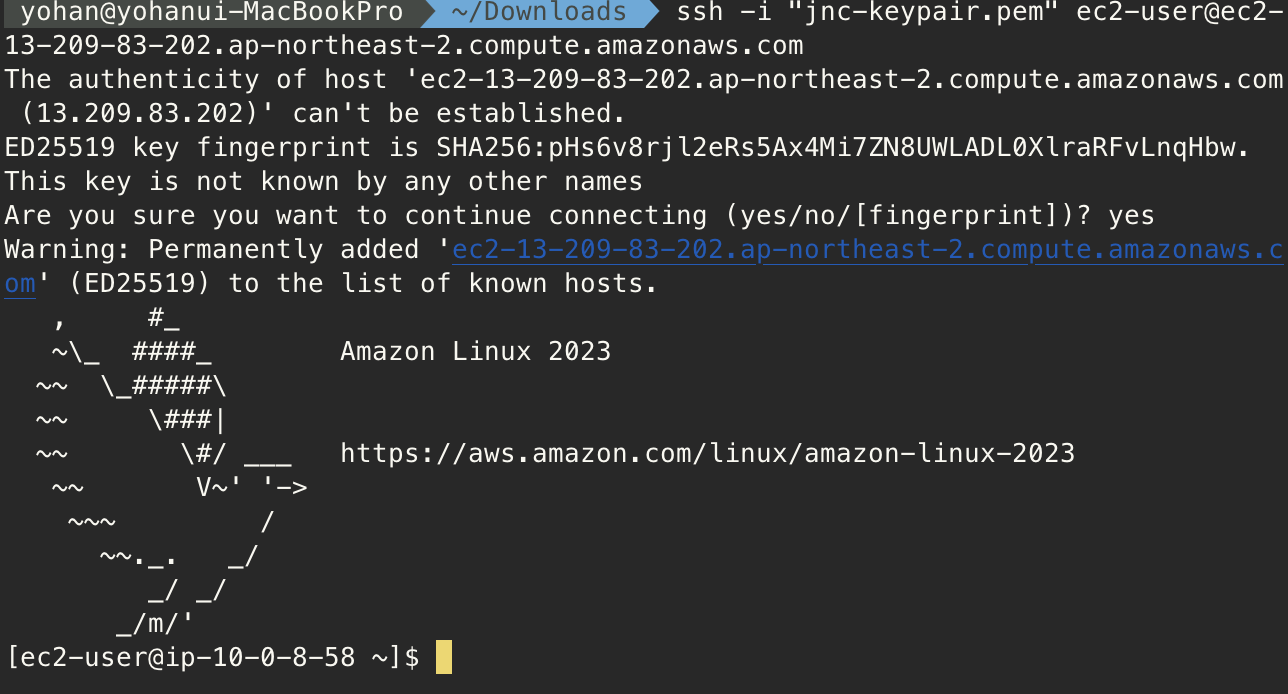
api gateway 스테이지를 보면 URL을 던져줄텐데 이 URL 뒤에 리소스를 엔드포인트로 붙여서 request를 날려보자.

curl -d "{\"value\":\"30\",\"type\":\"Tip 3\"}" -H "Content-Type: application/json" -X POST https://zinascamfh.execute-api.ap-northeast-2.amazonaws.com/PROD2/v1
request가 잘 날라갔으면 아래와 같은 response가 올 것이다.

이후 S3를 가서 확인하면 데이터가 버킷에 잘 저장되어있는 것을 볼 수 있다.
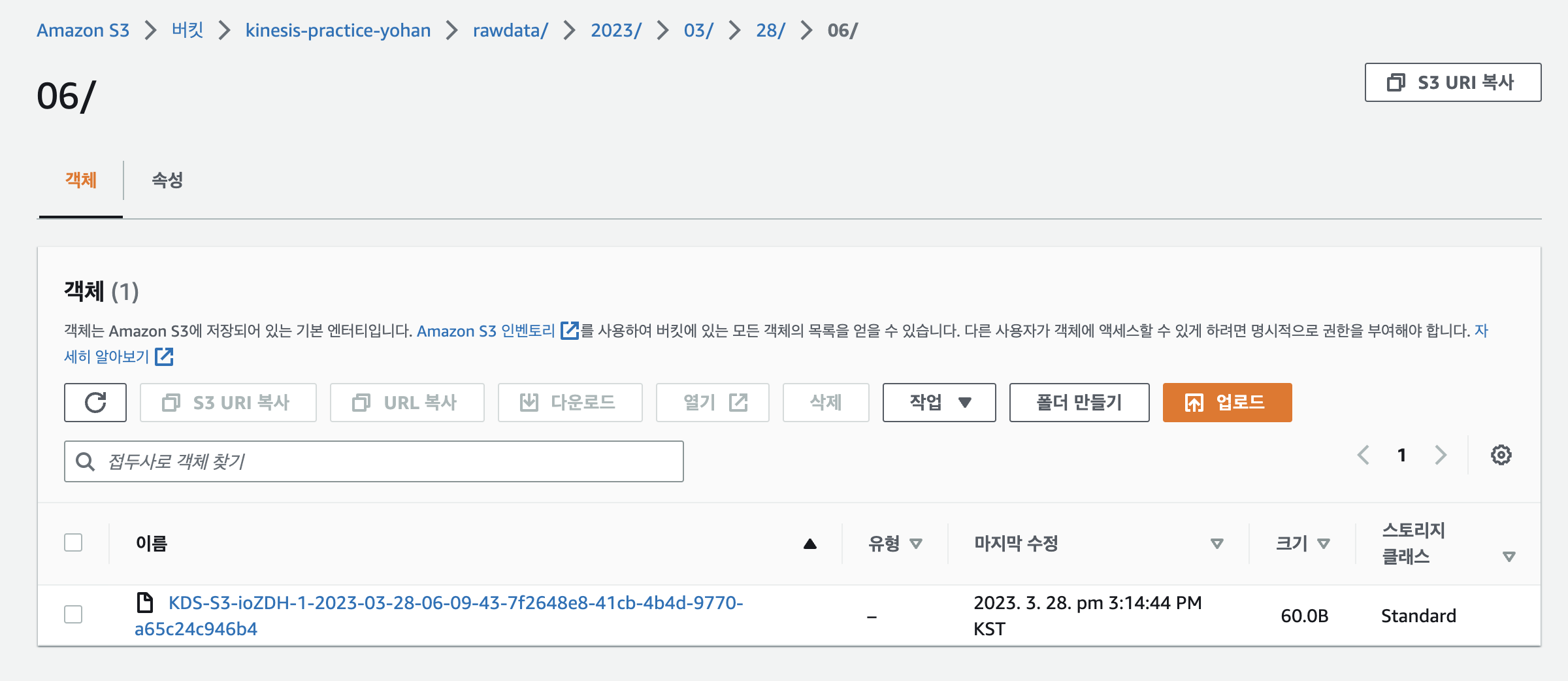
AWS Glue
잘 들어간 데이터를 Glue를 통해 데이터베이스 테이블을 만들어보자.
aws glue로 이동하여 데이터베이스 테이블을 만들어주자.
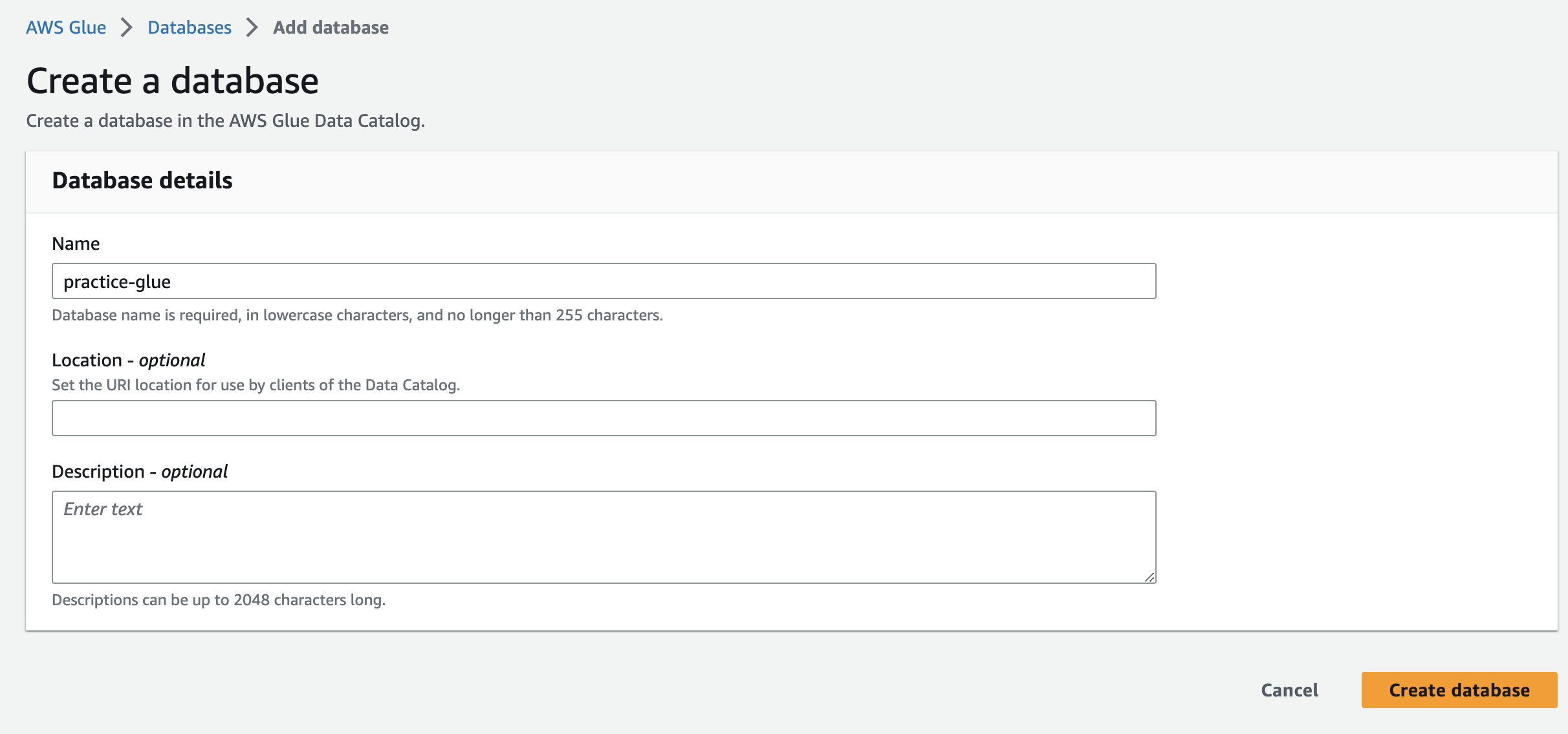
데이터베이스 생성을 다 했으면 크롤러로 이동해주자.
크롤러
크롤러를 생성해주자. 이름을 알잘딱 지어주고 next 클릭.
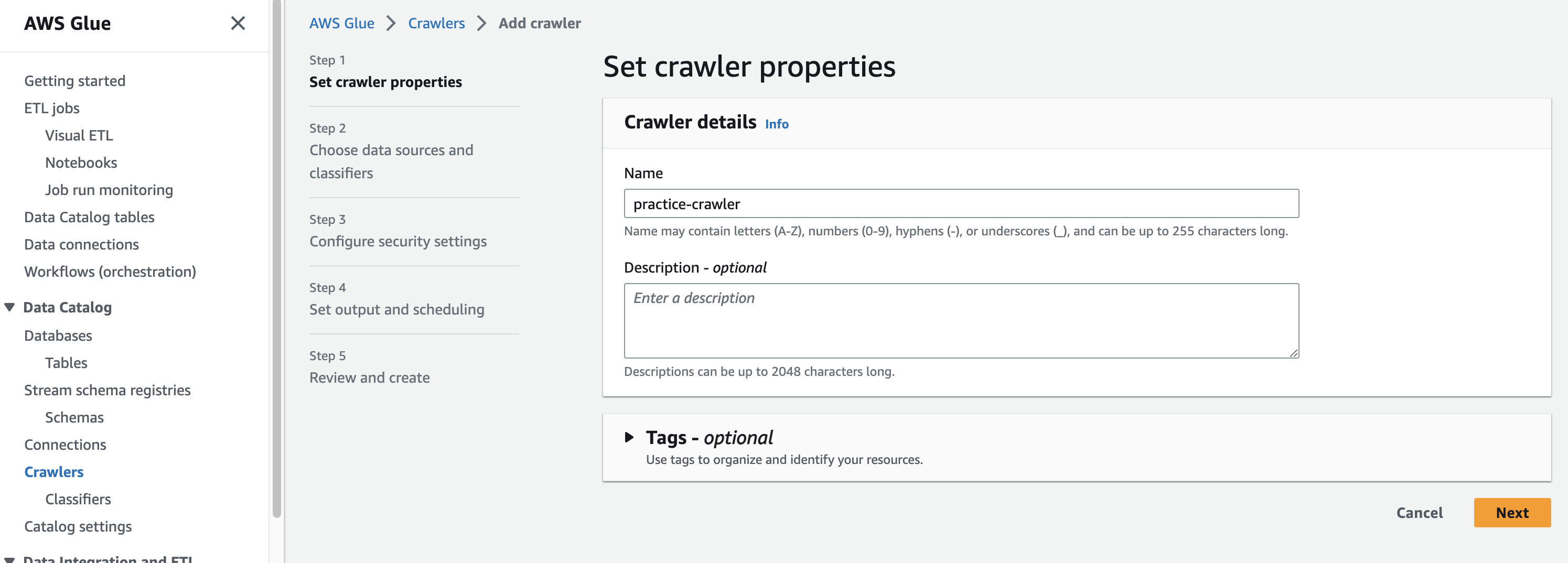
데이터 소스는 aws firehose 로 데이터를 받은 s3 버킷을 선택해준다.
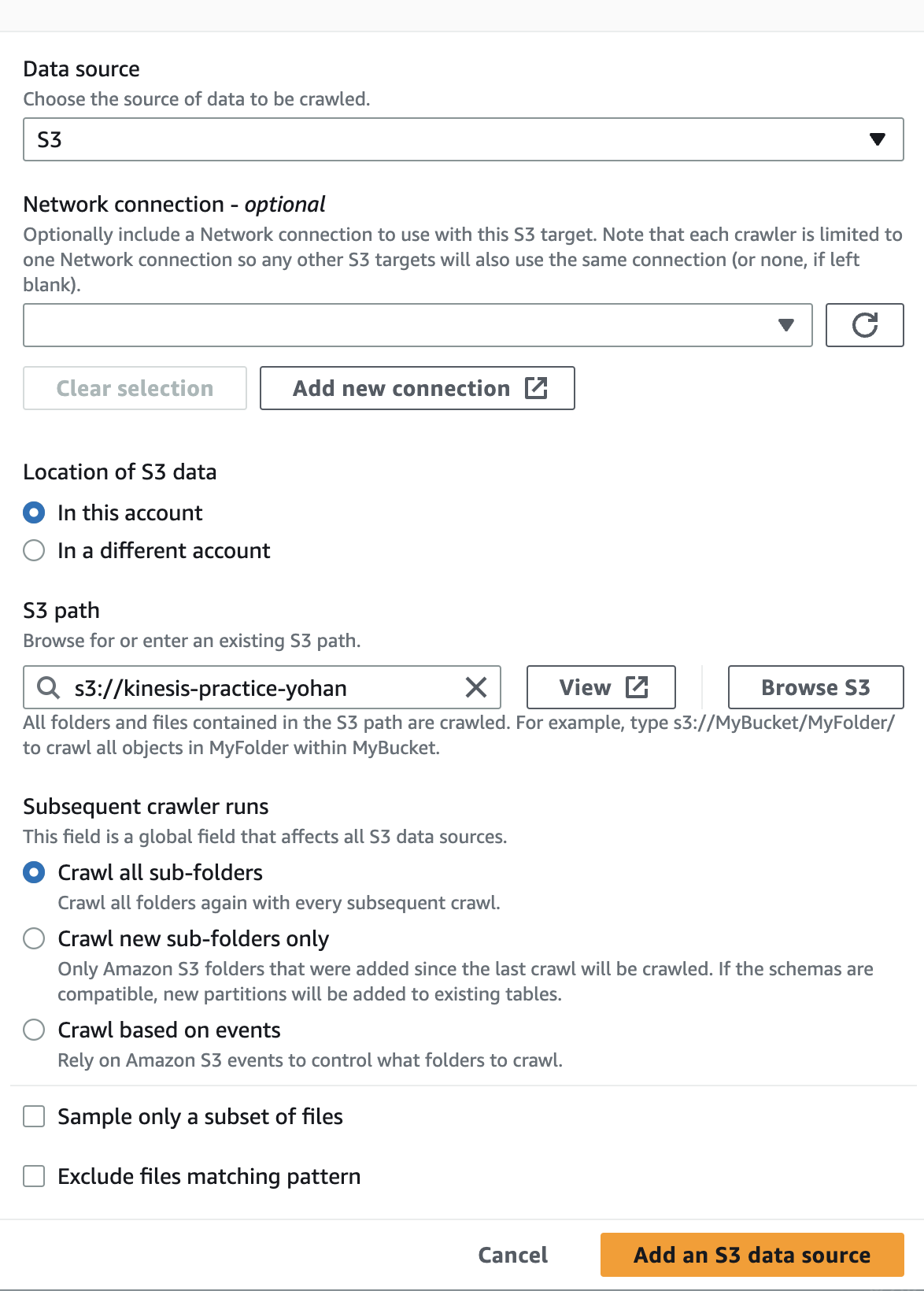
IAM은 create new iam role 을 눌러 이름을 알잘딱 생성해주고 다음으로 넘어가주자.
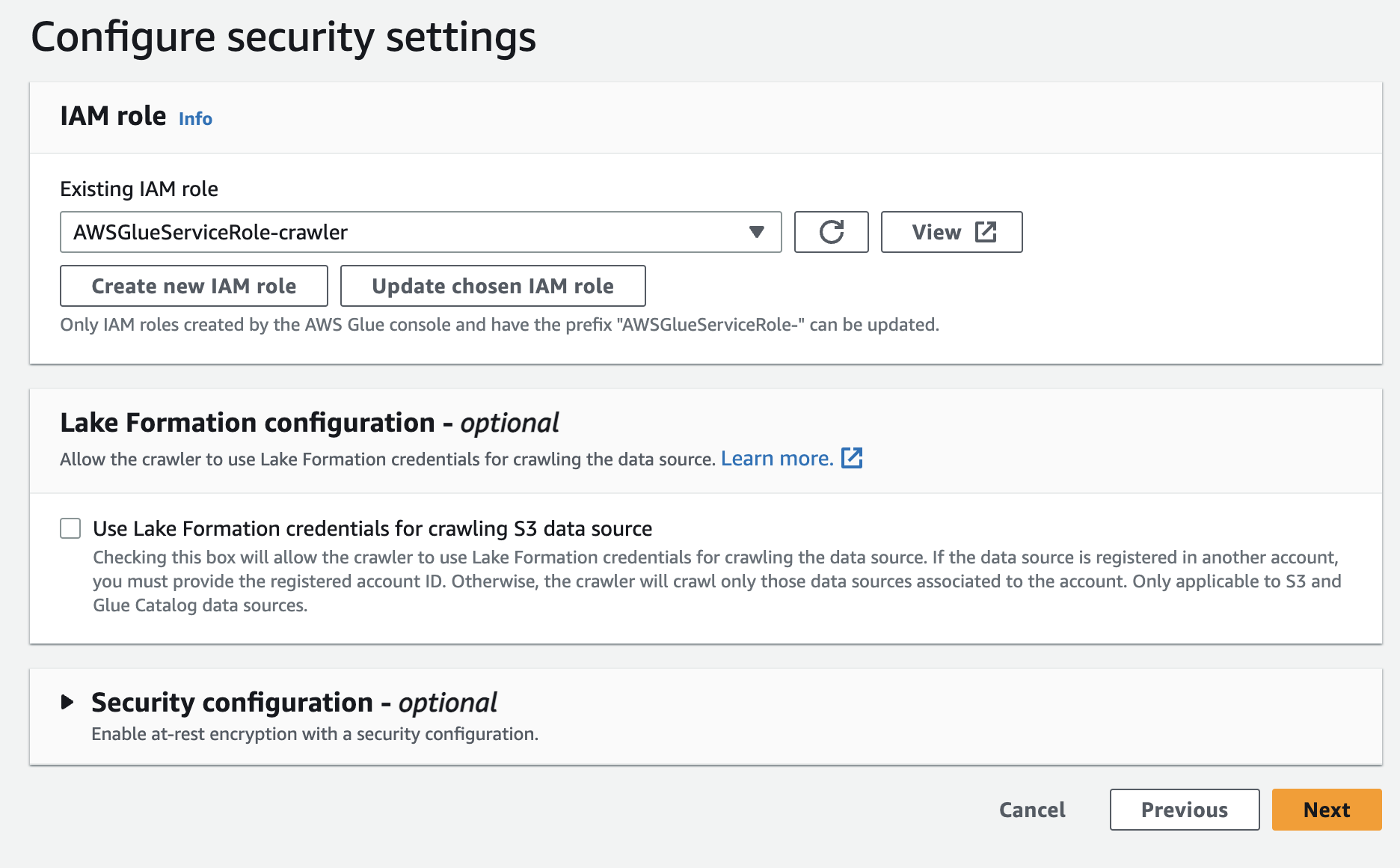
아웃풋을 아까 생성한 데이터 베이스로 설정해주고 다음을 눌러주자. 검토하는 화면이 뜰건데 쓰윽 훑어보고 생성해주자.
생성이 된 것을 볼 수 있다. 크롤러를 선택해주고 Run 버튼을 눌러서 크롤러를 실행시켜주자.
실행시킨 이후에는 running 으로 로딩이 돌아갈 것이다. 시간이 조금 걸리니 기다려보자
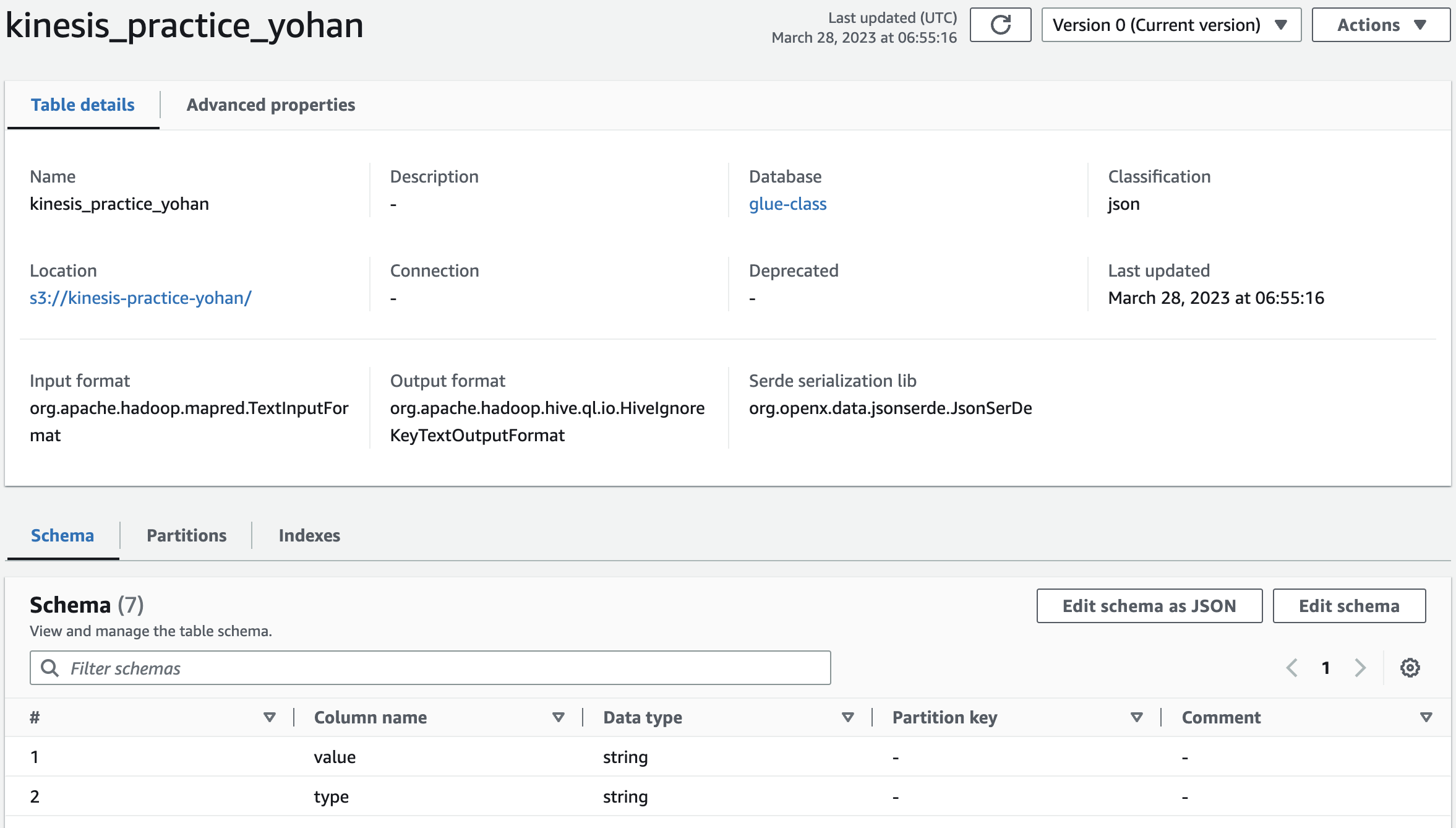
기다리다보면 Ready로 바뀌고 몇개의 테이블이 생성됐다고 보일 것이다. 이후 테이블로 이동하면 스키마들이 잘 생성되어있는 것을 볼 수 있다.