
aws glue로 들어와 Database 페이지로 이동하여 add database 를 클릭해준다.
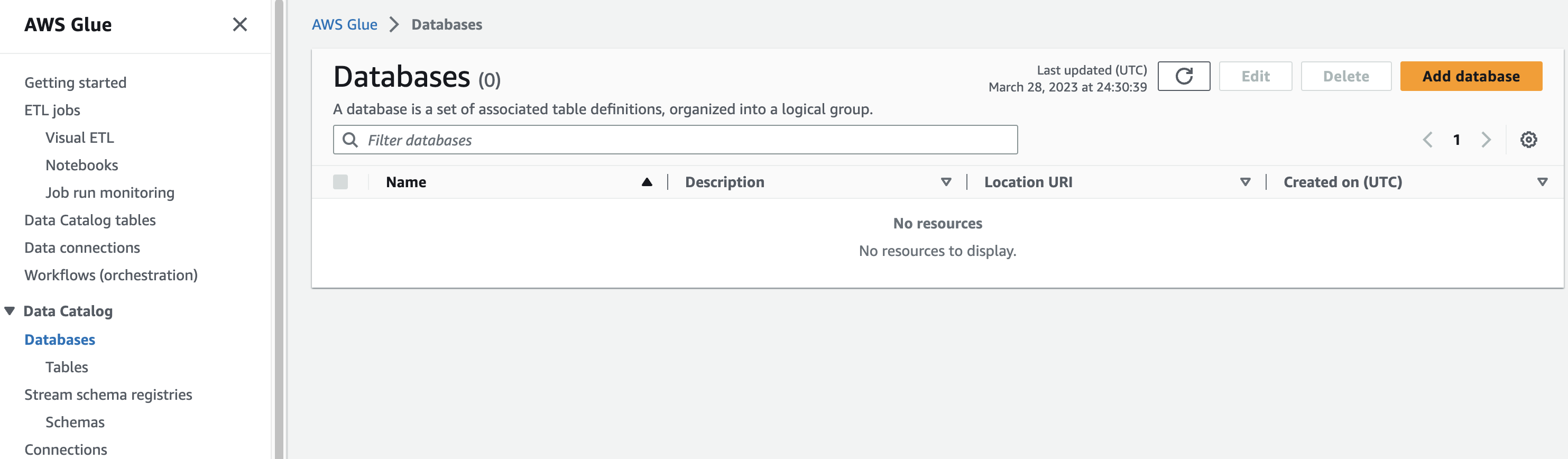
이름만 대충 지어주고 생성버튼을 눌러주자.
이후 사용할 크롤러를 생성해주도록하자.
이름을 알잘딱 지어주고
데이터 소스를 선택해주자. 우리는 저번 실습떄 DataStream과 firehose 를 통해 데이터를 전달받은 s3를 선택하자.
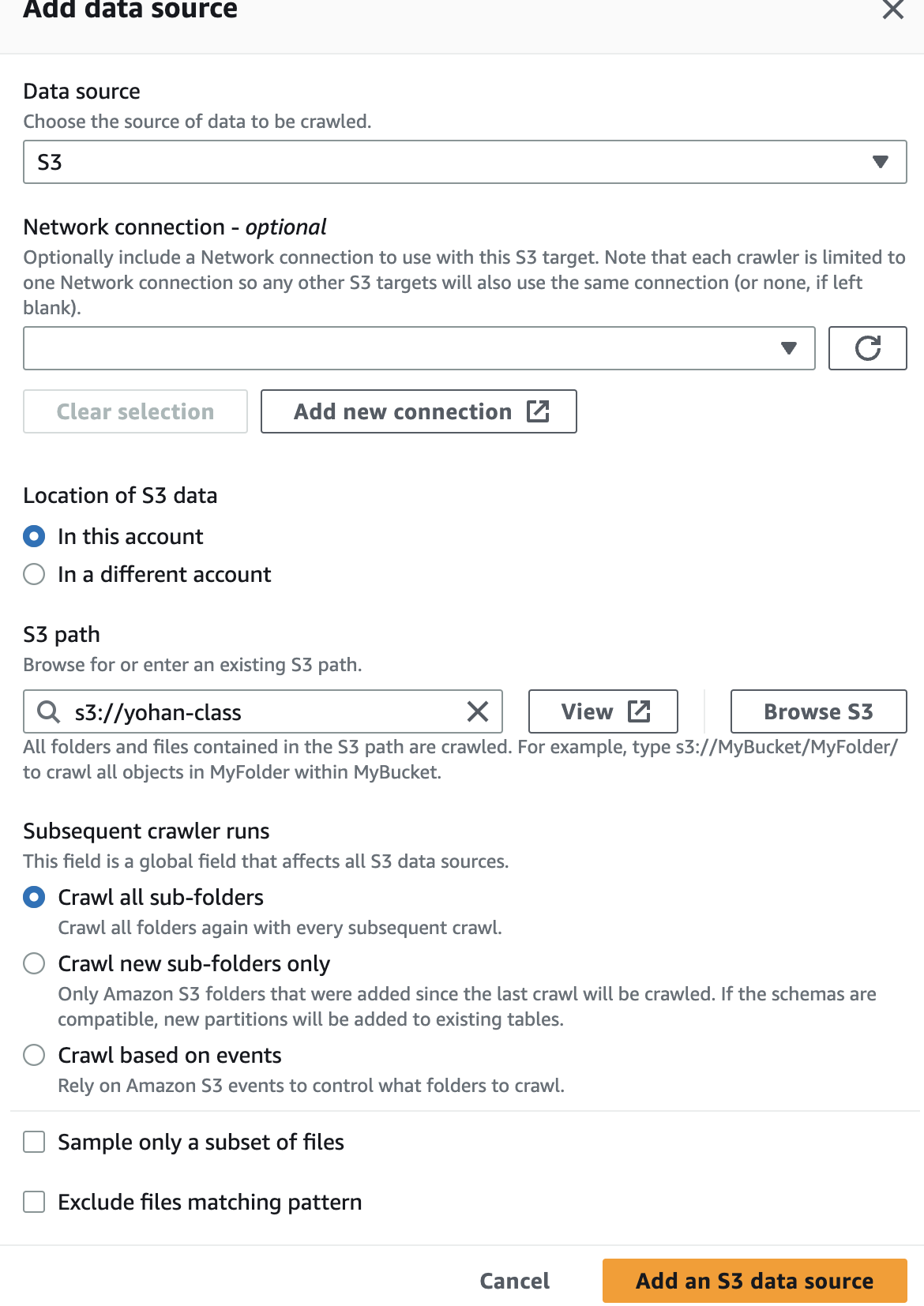
이후 다음으로 넘어가면 IAM role 관련 창이 나올건데 create new iam role 을 선택하여 새로운 iam 을 생성해준다.
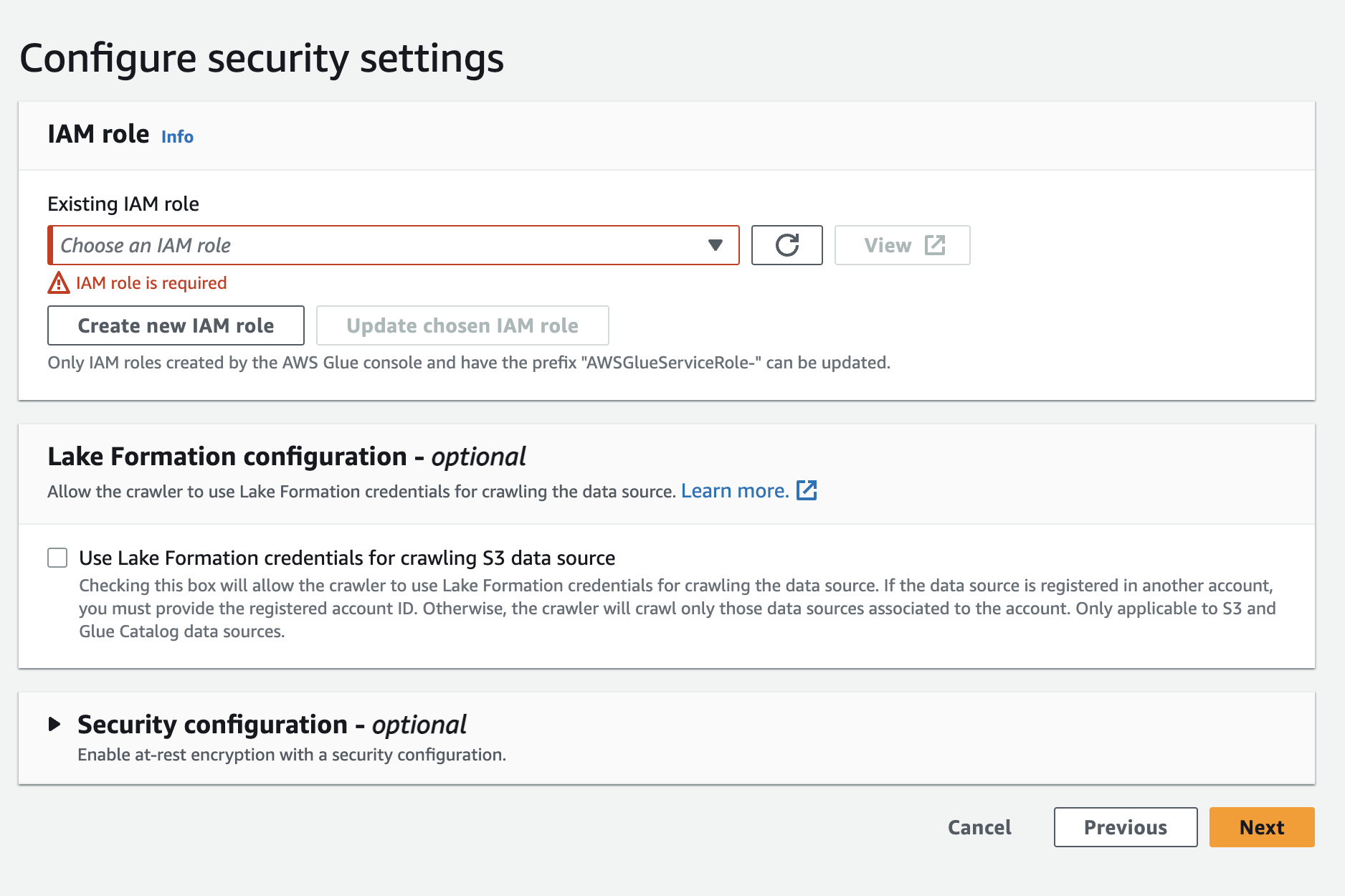
이름은 알잘딱. 지어주고 다음 단계로 넘어가준다.
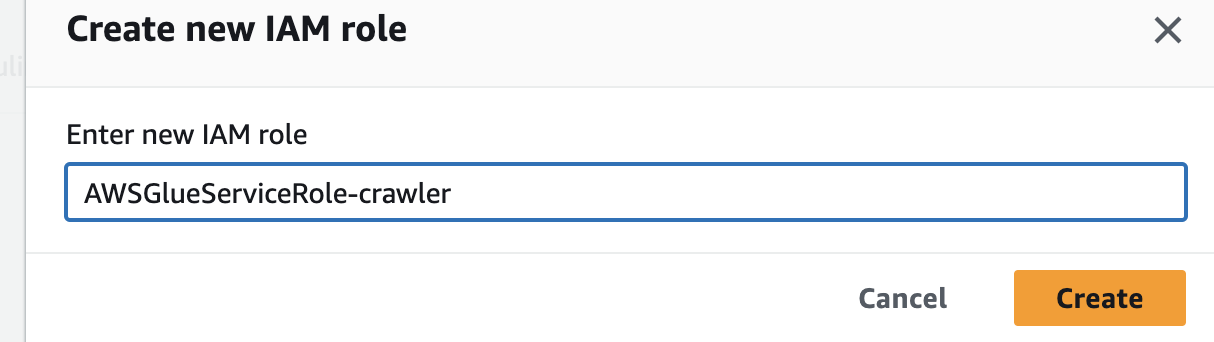
이번 단계는 아웃풋과 스케쥴링이넫 우리가 만든 database인 class 를 선택해주고 스케쥴링은 따로 진행하지 않겠다. 다음 버튼을 누르면 검토창이 뜰 것이다. 쓱 훑어보고 생성해주자.
크롤러가 생성된 것을 볼 수 있다. 클릭 -> Run을 눌러 실행시켜주자. 실행시킨 이후에는 running 으로 로딩이 지속될 것인데 저 데이터들을 받아다가 연결해준 데이터베이스에 꽂는 과정을 진행중인 것이다.
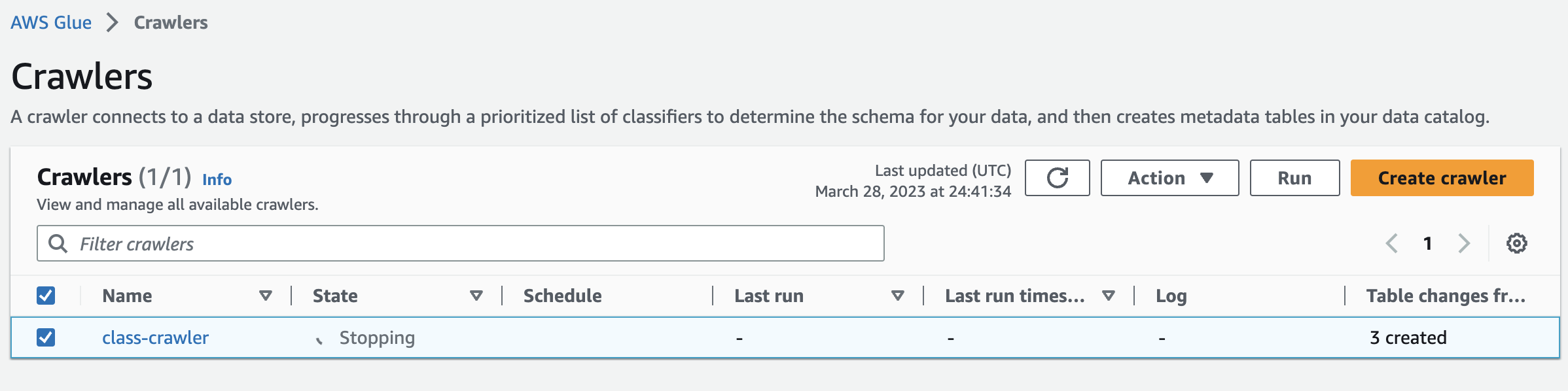
과정이 다 진행되면 stopping이 뜨며 table change .. 에 테이블들이 생성됐다고 나온다.
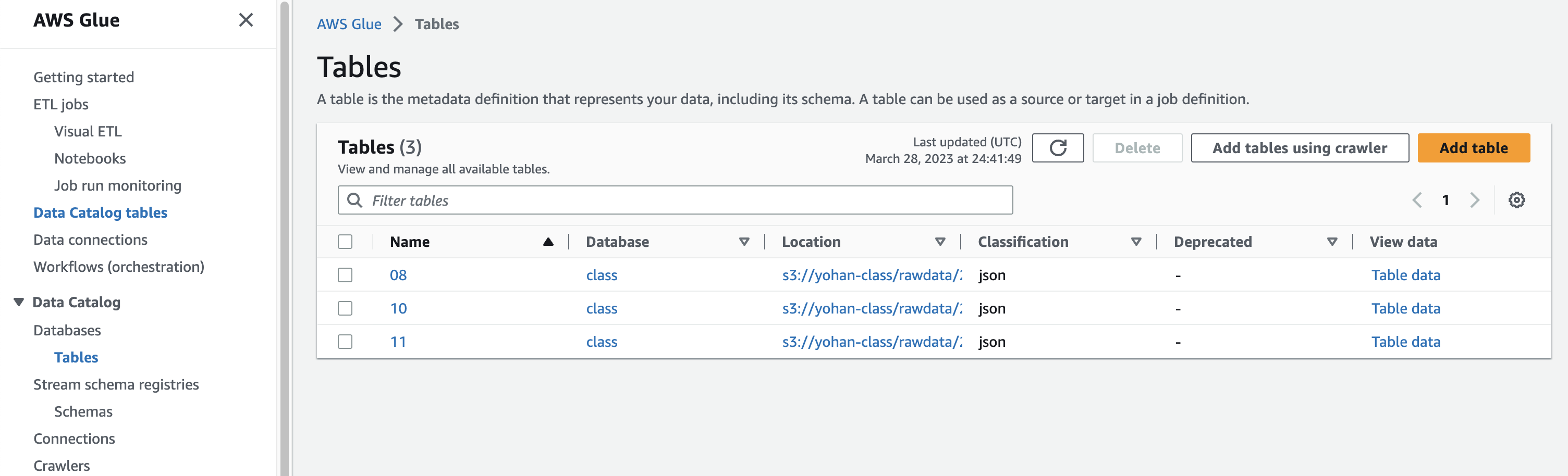
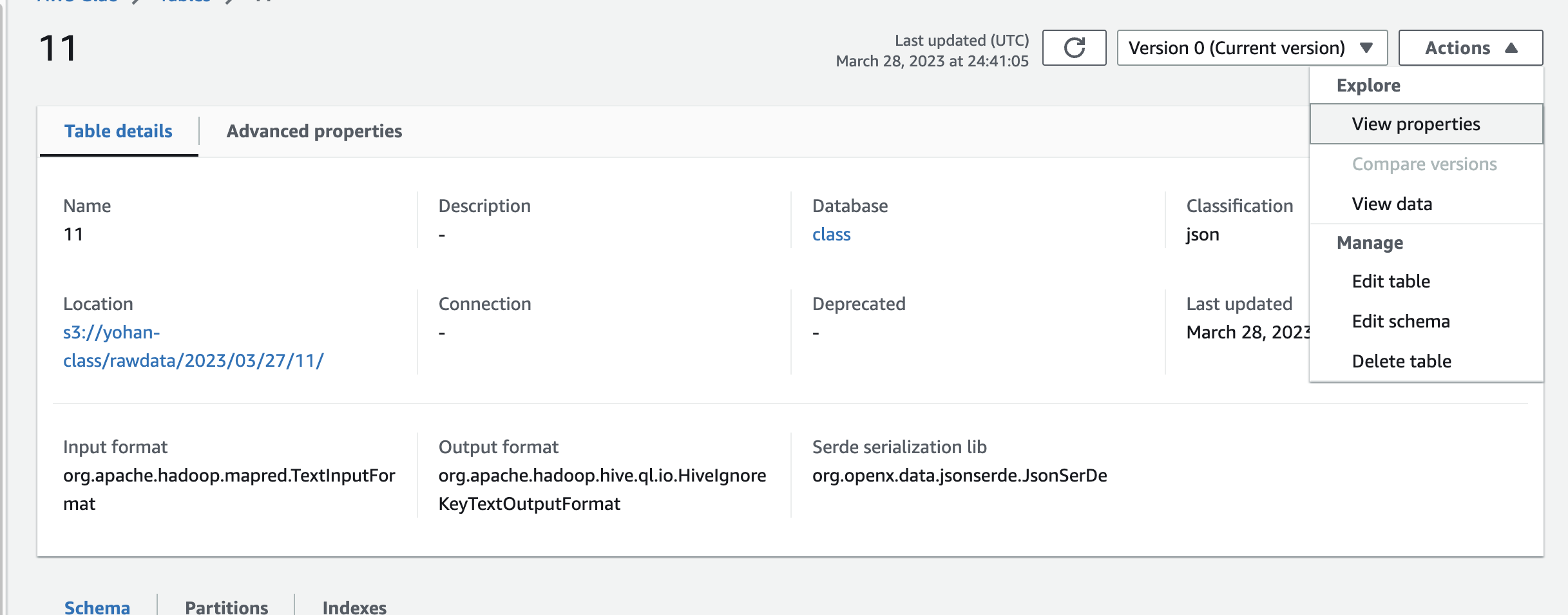
테이블을 클릭해주면 s3에서 봤던 익숙한 폴더 명들이 보일 것이다. 저번 실습 마지막으로 전송한 데이터인 11을 클릭해주자.
데이터들의 column name, data type 등이 제대로 들어온 것을 알 수 있다.
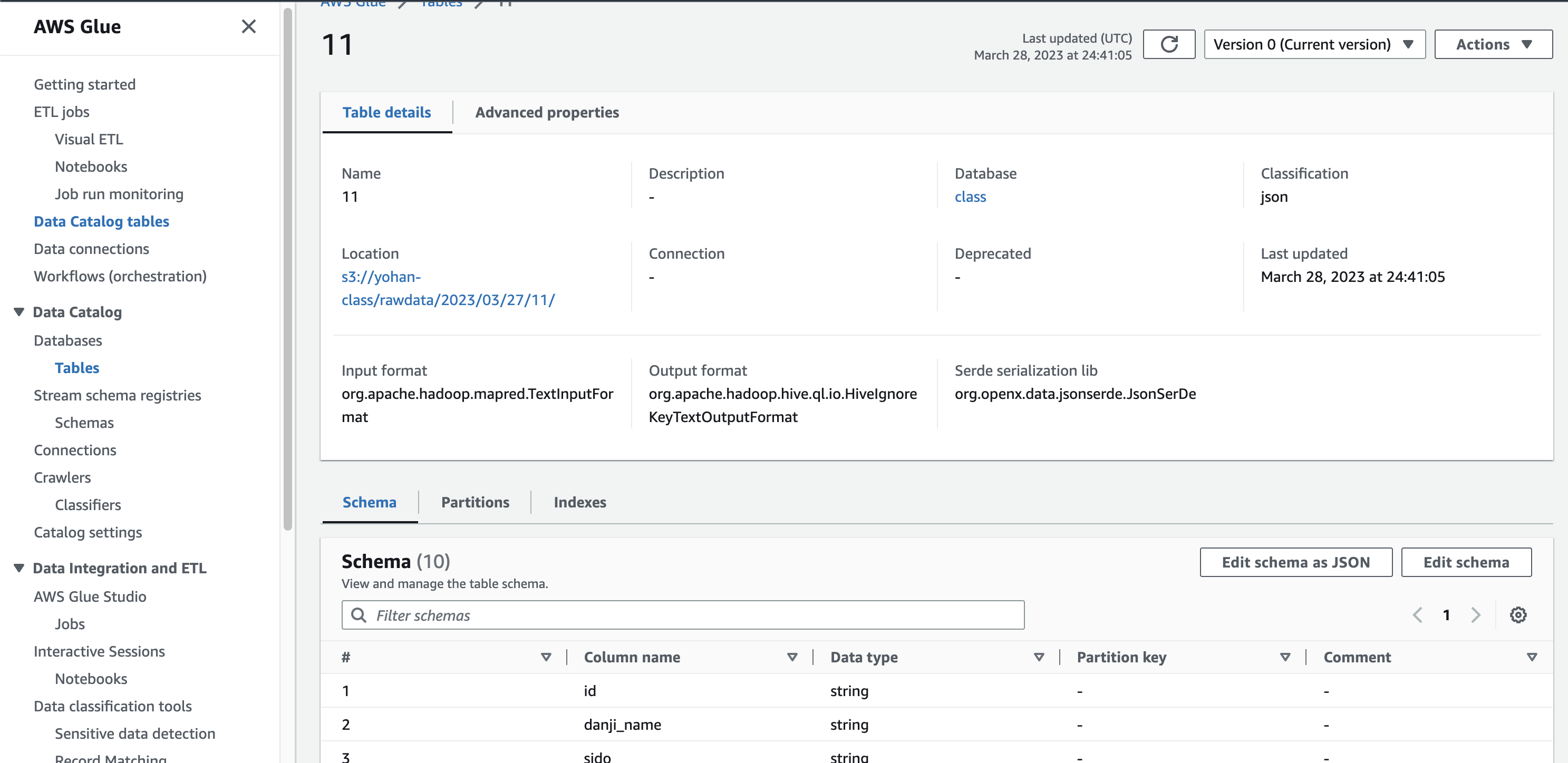
작업 버튼으로 테이블과 스키마등을 수정할 수 있다.

안녕하세요 DevOps 엔지니어로 현업에서 활동중인 요한이라고 합니다.