
YOLO Series
-
SOTA of Real time detector :
현재 실 사용되는 모델들 중 가장 빠른 모델 중 하나.
기존 존재하던 2-stage detector 에서 1-stage detector 로 task를 진행하며 빠른 속도가 장점.
속도 향상에 비해 정확도가 크게 낮아지지 않아 기존의 trade-off를 깨고 등장한 모델. -
Unified Detection :
YOLO의 저자는 YOLO의 detection 과정이 unified 라고 명시.
Bounding box 예측, Classification을 일련의 과정으로 학습. -
Agenda:
YOLO model series의 발전동안의 engineering적 요소들을 파악
YOLOv1 (Original)
- First YOLO :
S x S 크기의 Grid Cell로 Input Image를 분리.
Cell마다 B개의 Bounding boxes, confidence score, Class probabilities를 예측.
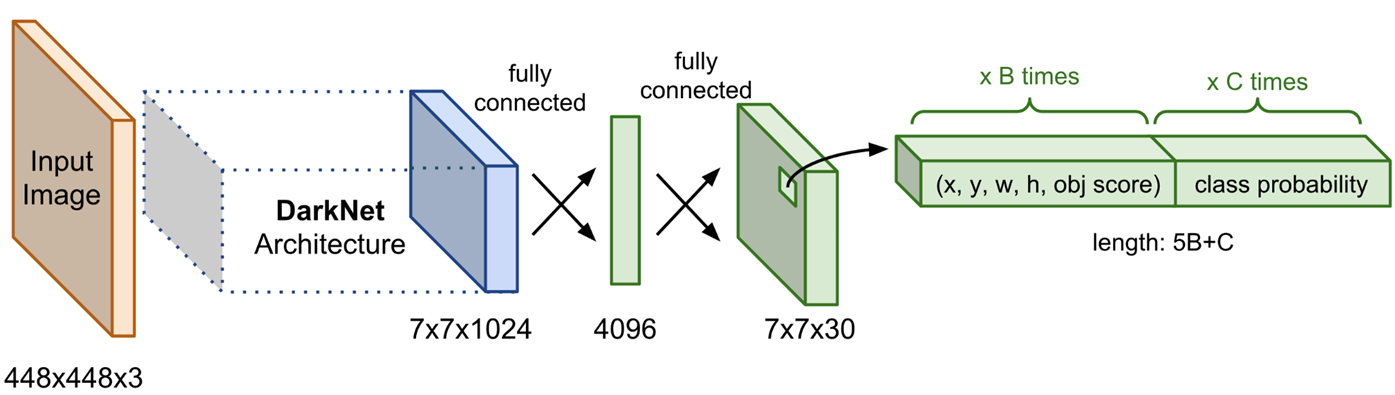
Final Output : S x S x ( B * 5 + C ) [ S : Num of Cell, B : Num of Bounding boxes, C : Num of Classes]
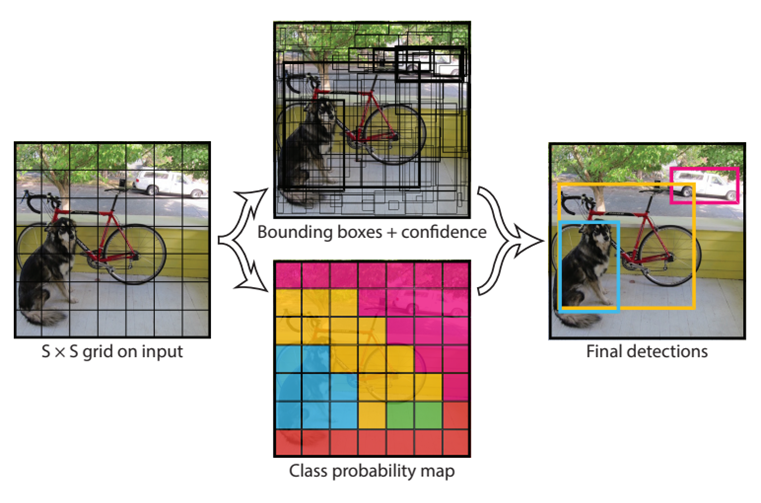
- NMS (None Maximum Suppression) :
각각의 Grid Cell마다 B개의 Bounding Box 생성.
인접한 Cell이 같은 객체를 예측하는 Bounding Box를 생성하는 문제 발생.
이를 해결하기 위해 IOU를 측정하여 가장 높은 IOU를 제외한 나머지 Bounding Box 삭제.

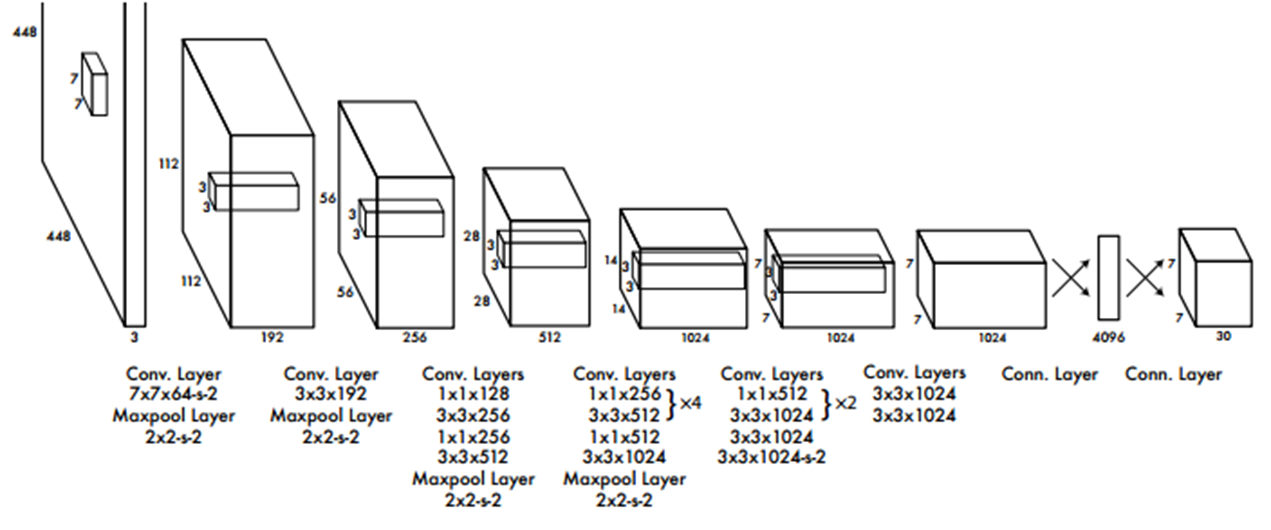
- Architecture :
24개의 Conv layer와 2개의 FC layer로 구성.
Darknet network라고 부르며 ImageNet dataset으로 Pre-trained된 network를 사용.
1x1 Conv layer와 3x3 Conv layer의 교차를 통해 Parameter 감소( GoogleNet 인용 ).
- Loss Function :
Bounding box loss와 Classification Loss를 한번에 Optimizing.
𝛌를 사용하여 각 loss들에 가중치를 부여하여 학습.
SSE(Sum Squared Error) 사용.
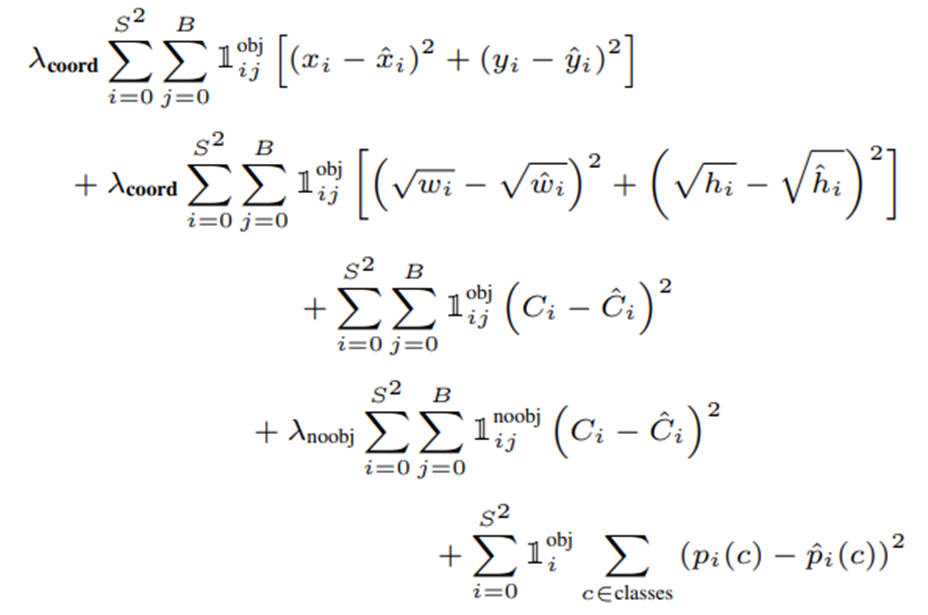
- YOLOv1의 특징 :
각 Grid cell은 하나의 Class만을 예측.
인접한 Cell들이 동일한 객체에 대한 Bounding Box를 생성할 수 있음.
Background Error가 낮다.
당시 SOTA들에 비해 Real-Time 부분에서 가장 좋은 성능을 보임.
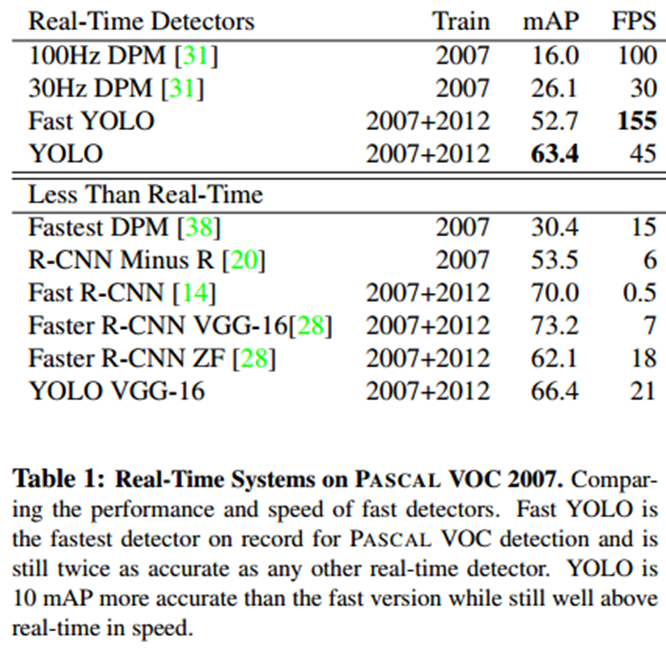
YOLOv2 (YOLO9000)
- YOLOv2의 특징 :
기존 YOLO의 다소 낮은 정확도의 개선.
높은 해상도의 이미지로 Back Bone network Fine tuning.
Anchor Box 도입으로 인한 학습 안정화.
높은 해상도의 Feature map을 낮은 해상도의 Feature map에 합치기
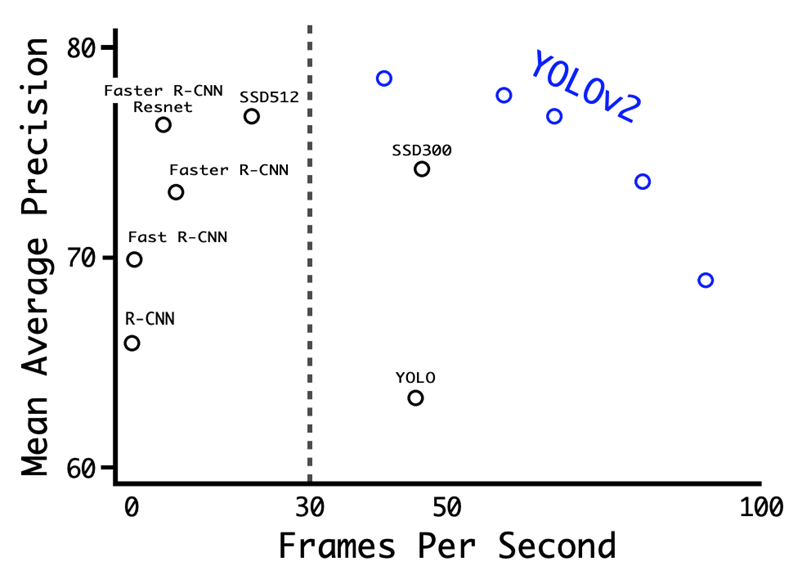
-
Batch Normalization :
기존 모델에서 Dropout Layer를 제거하고 Batch Norm을 사용. mAP 2% 향상.
High Resolution Classifier
기존 모델은 224x224 size로 Pre-train, 448x448 size를 input으로 사용하여 불안정한 학습.
448x448 size로 Pre-train 후 학습하여 mAP 4% 향상. -
Anchor Box :
mAP는 약간 감소하지만 recall이 높아져 더 많은 예측이 가능.
No Anchor box = mAP : 69.5 | recall : 81%
Anchor box = mAP : 69.2 | recall 88% -
Fine-Grained Features :
YOLO의 주된 문제점으로 이야기되는 작은 물체 탐지, 세밀한 classification 가능.
작은 물체도 탐지하기 위해 상위 Layer의 Feature map을 하위 Layer의 Feature map에 concatenate.
또한, 여러 스케일의 이미지를 학습하기 위해 해상도를 바꿔주며 학습 진행.
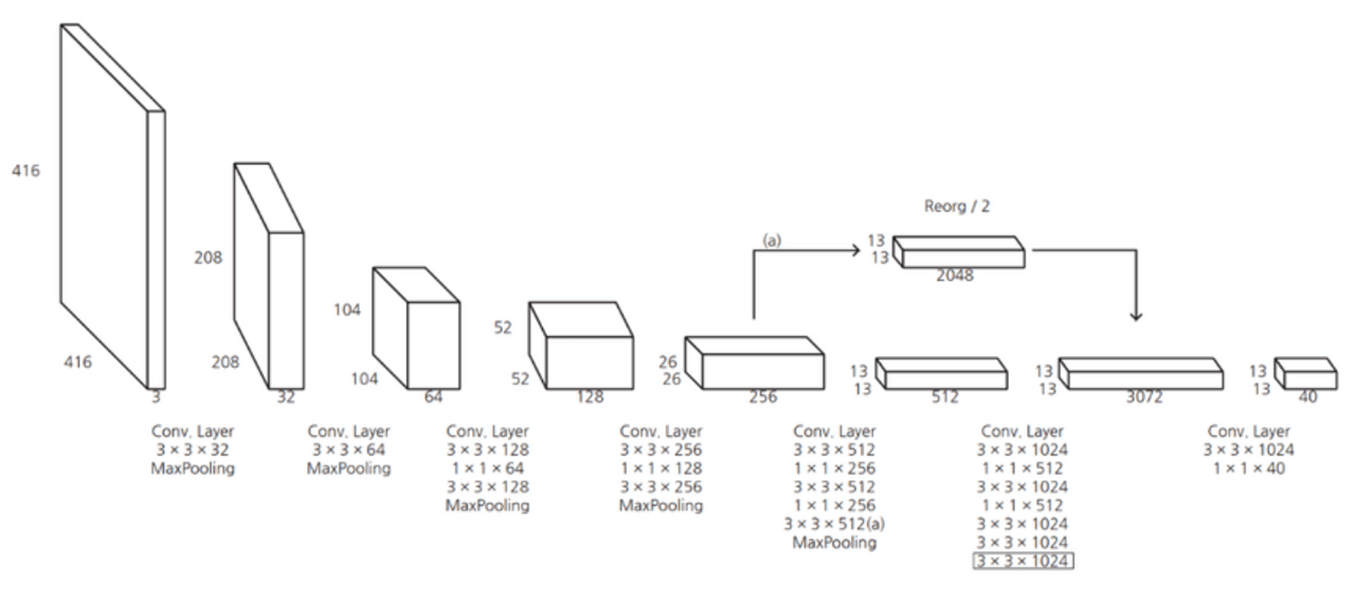
- Architecture :
기존의 Darknet을 개선한 Darknet19 제안.
기존 network의 마지막 FC layer를 삭제.
Global Average Pooling을 사용해 파라미터를 줄여 속도 향상.
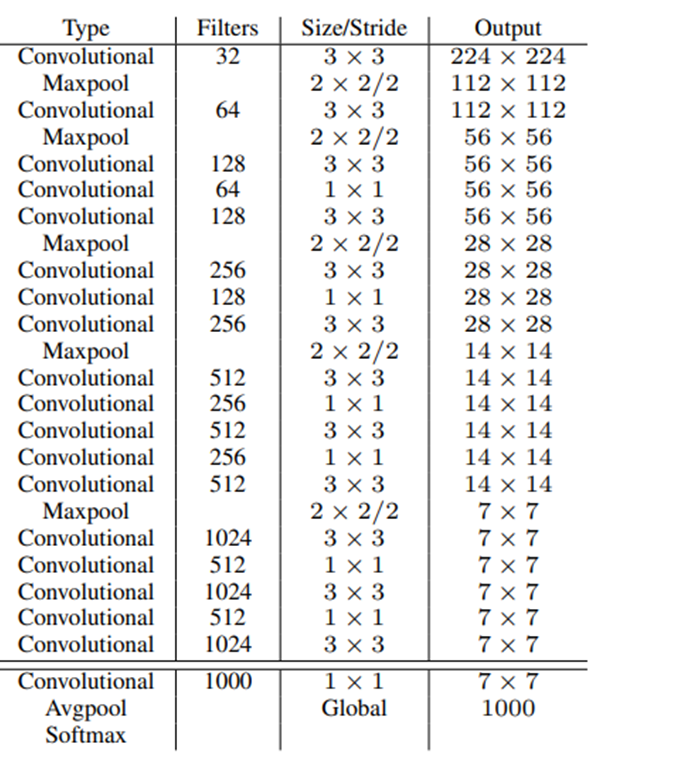
- Comparison :
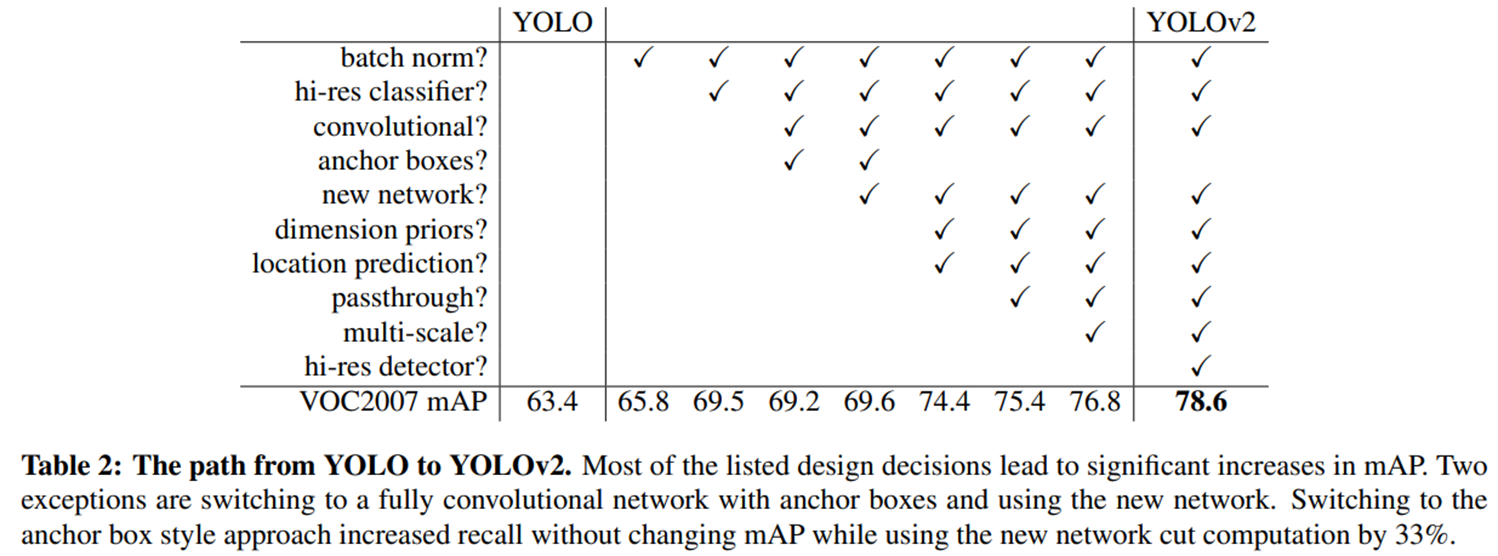
YOLOv2에서 YOLOv1과 다른 어떤 방식을 사용하여 정확도가 올라갔는지를 나타내는 표.
V2는 v1보다 정확하고 빠르게 개선된 모델.
YOLOv3 (An Incremental Improvement)
- Main Idea :
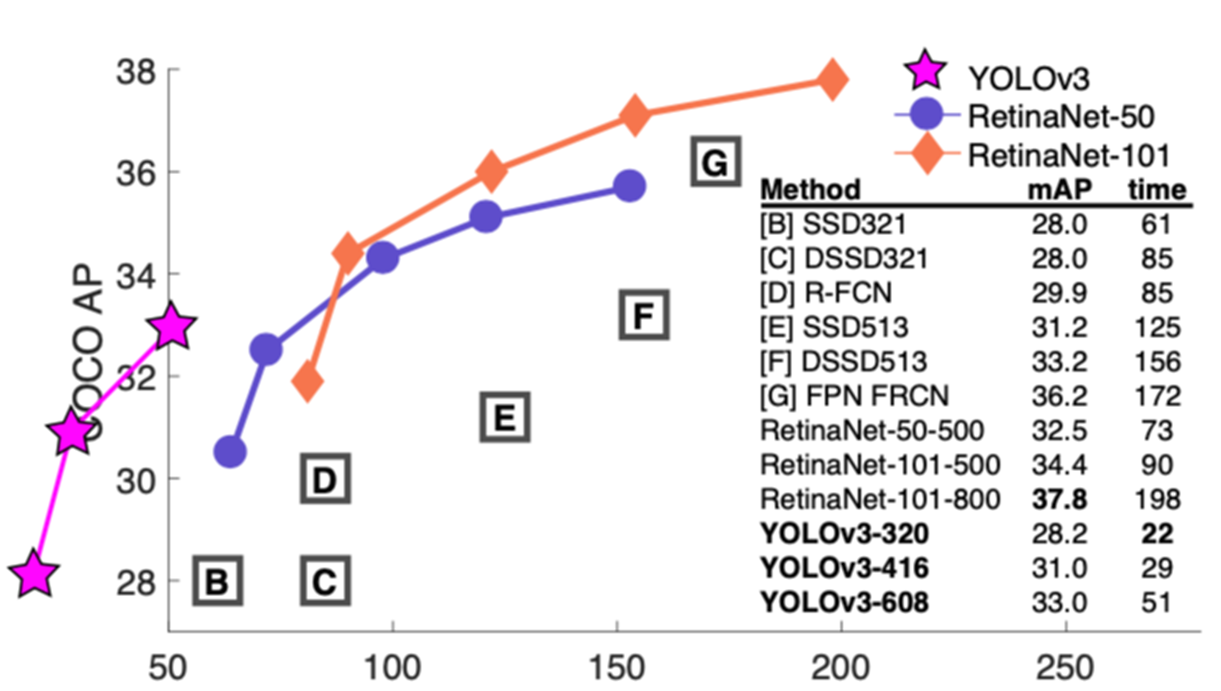
YOLOv3는 다른 사람들의 아이디어를 차용한 내용.
17년 당시 SOTA였던 RetinaNet과 비교했을 때, Facebook이 상정한 최소 시간조차 뚫어낸 속도.
- Architecture :
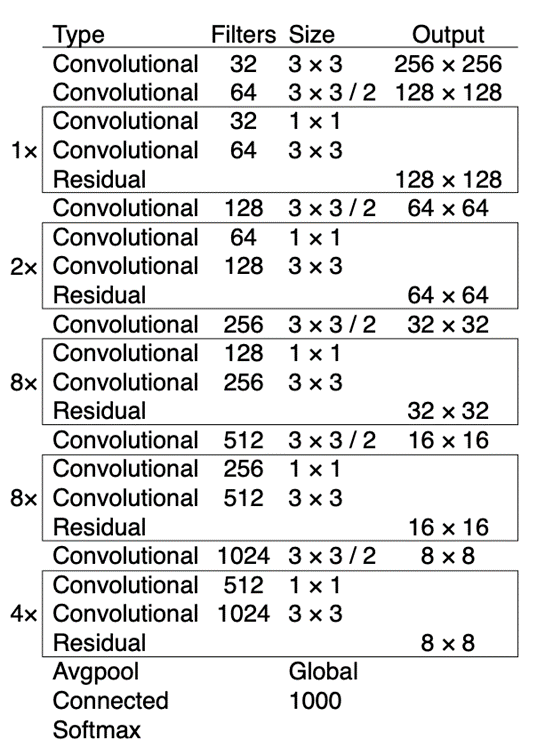
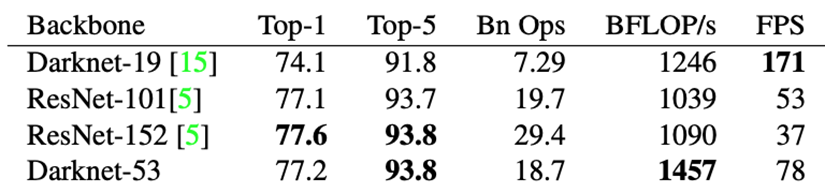
Backbone network를 Darknet-53으로 변경.
이전 Darknet-19에 ResNet에서 제안된 skip connection 개념을 적용.
- Multi-Label Classification :
Loss function을 Softmax가 아닌 Binary cross entropy으로 변경.
하나의 Box 안에 여러 객체가 존재할 경우 Softmax는 적절한 객체 포착 불가능.
Binary cross entropy를 통해 box에서 각 class의 존재 여부를 확인하여 적절한 포착을 가능하게 변경.

- Prediction across scales :
서로 다른 3개의 scale을 사용하여 최종 결과 예측.
각 feature map을 FCN(Fully Convolution Network)에 입력.
더 높은 Level의 feature map으로부터 fine-grained 정보를 얻을 수 있다.
더 낮은 level의 feature map으로부터 유용한 semantic 정보를 얻을 수 있다.
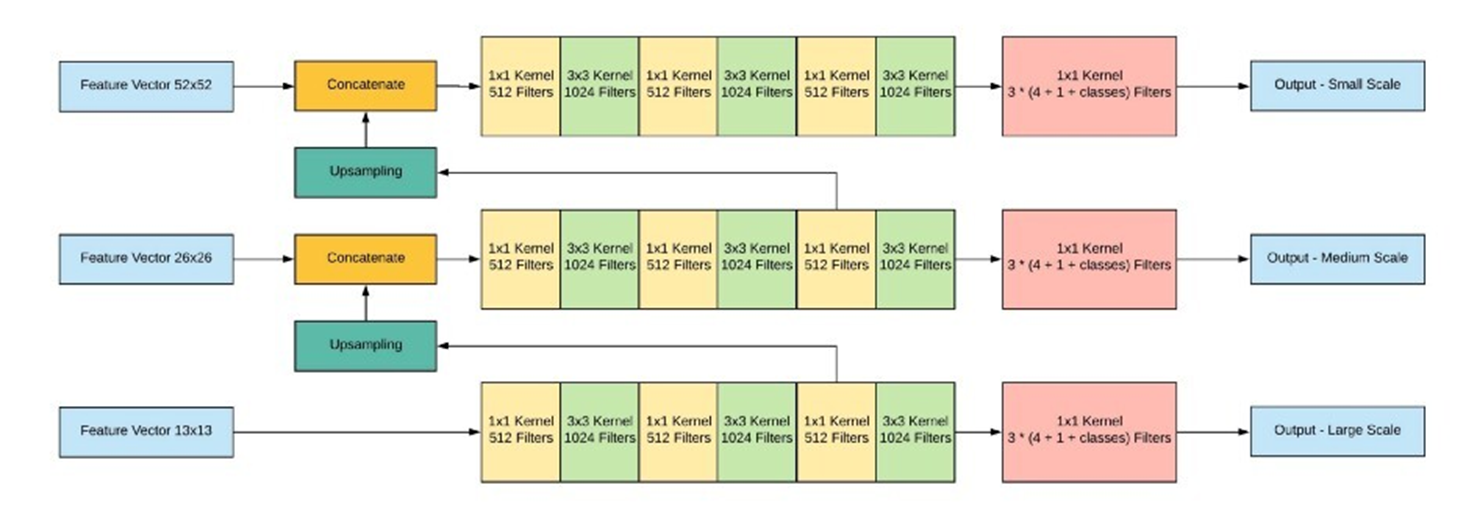
- Comparison :
YOLOv2까지는 Pooling layer를 사용했지만, v3에선 사용하지 않음.
Network가 더 깊어지고, Bounding box를 multi scale마다 생성하여 굉장히 많은 수를 생성.
V2보다 속도가 느려지고 성능을 높인 모델.
연산이 급격하게 늘었기 때문에 이전보다 하드웨어 스펙에 더 의존하게 된 모델.
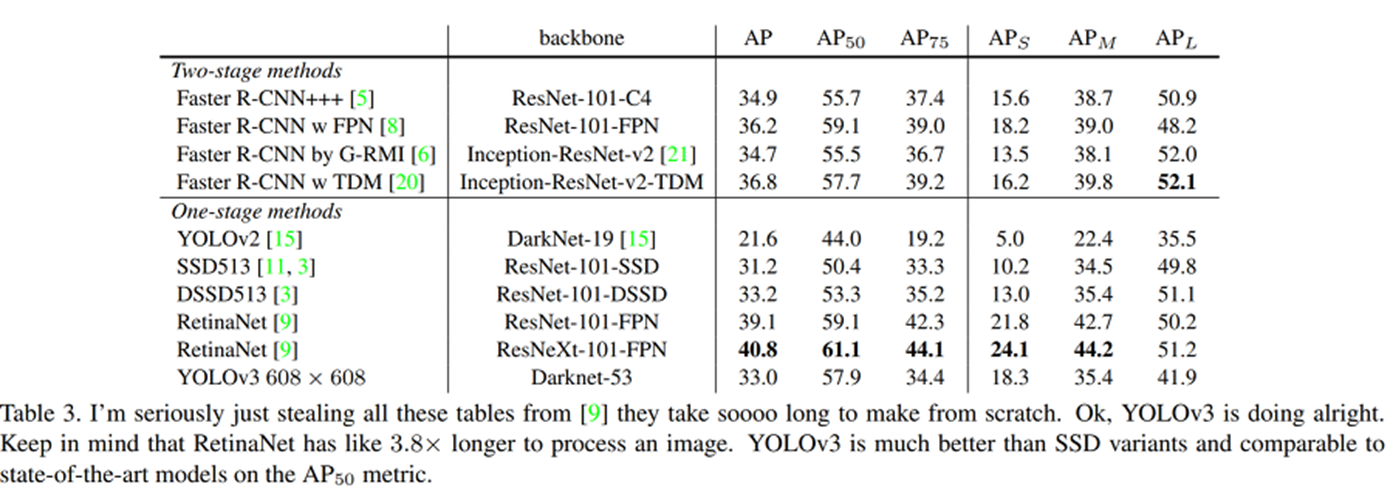
YOLOv4 (An Incremental Improvement)
- Object detection models :
기존의 detector 모델들은 Backbone과 head로 구성되어있었다.
최근(v4 기준) 서로 다른 scale의 feature map을 수집하는 neck layer가 등장!.
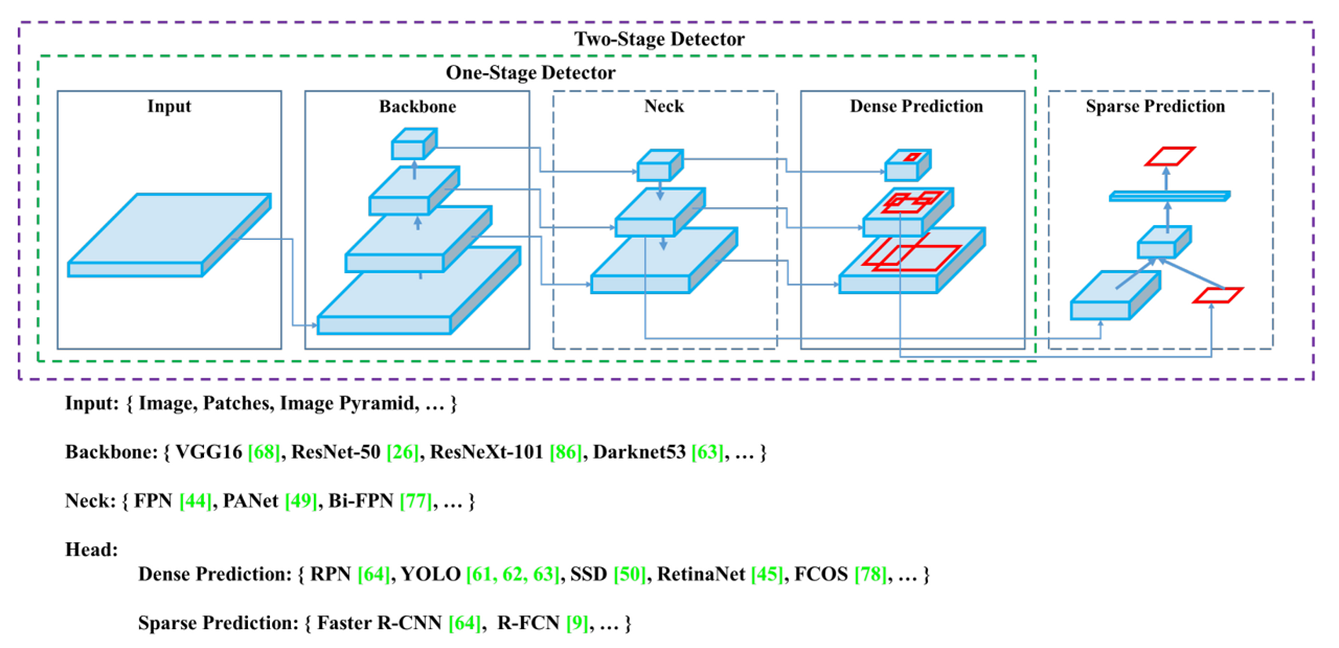
- Main Idea :
Computing power가 높지 않은 환경에서도 기존의 1-GPU를 사용해서 Realtime detection을 가능하게 하고자 하는 목적.
V3와 마찬가지로 당시 연구된 detector 관련 좋은 기술들을 Grid search 를 통해 접목시켜 최적의 model을 생성.
연산양의 숫자를 줄이는 것이 아닌 병렬적으로 계산이 가능하게 하여 속도를 최적화.
YOLOv4 = YOLOv3 + CSPDarknet53(Backbone) + SPP + PAN + BoF + BoS.
V3와 비교했을 때, AP, FPS가 10%, 12% 증가.
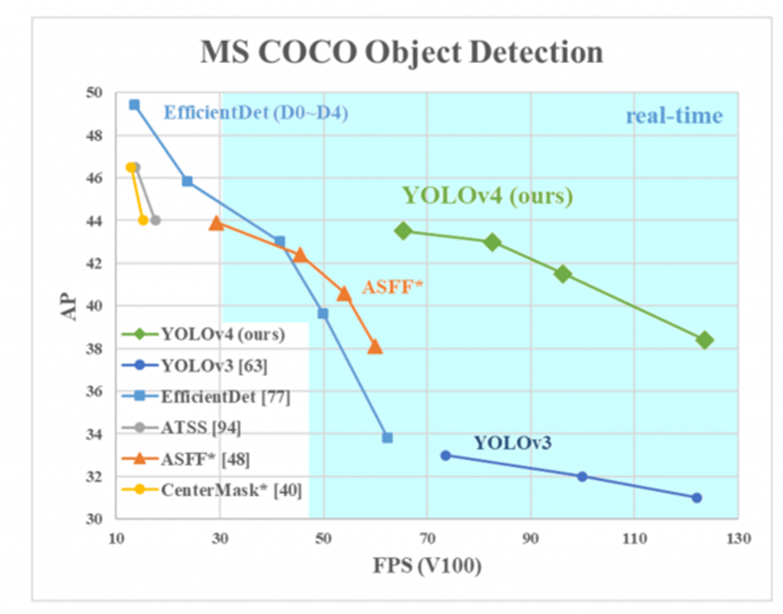
-
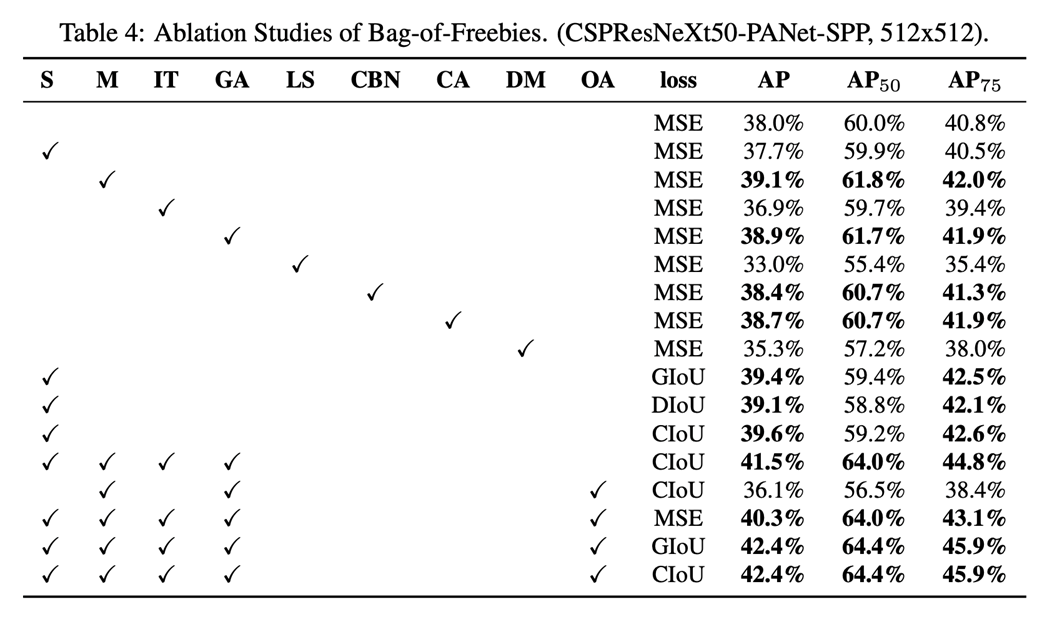
BoF(Back of Freebies) :
Inference time은 증가시키지 않으면서 더 높은 정확도를 얻기 위해 학습시키는 방법.
Data augmentation : CutMix, Mosaic 등
Bounding Box Loss function : 기존의 MSE 대신 CIoU 사용
Regularization method : DropBlock -
BoS(Back of Special) :
Inference time은 조금 증가시키지만 정확도를 크게 향상시키기 위해 학습시키는 방법.
모델 및 후처리에 적용하는 기술.
Enhance receptive field : SPP( Spatial Pyramid Pooling )
Attention module : SAM( Spatial Attention Module )을 사용하여 Inference time 유지, 정확도 향상
Activation Function : Mish
Skip-connections : Cross stage partial connections -
Backbone :
CSPDarknet53
기존 Darknet에 CSP layer를 연결.
Layer도 깊고 parameter도 많지만 속도를 빠르게 해준다.
정확도에 손실 없이 빠른 연산이 가능.
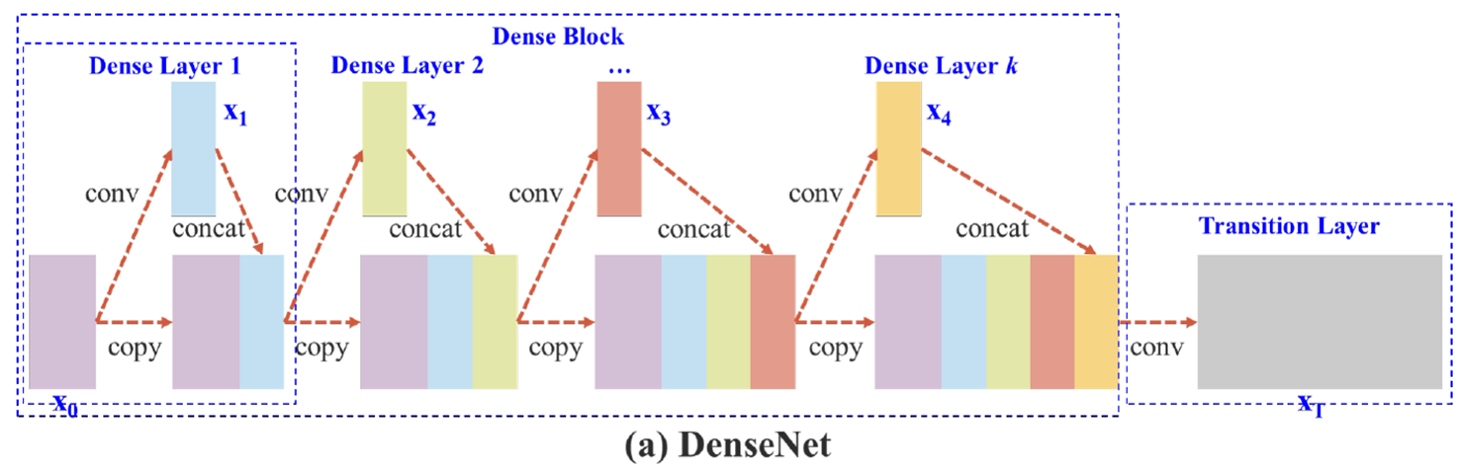
- Neck
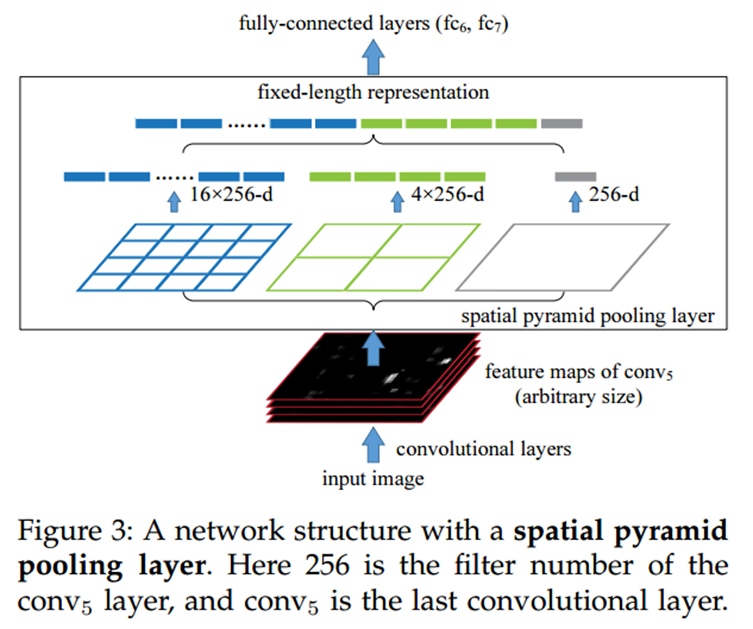
SPP(Spatial Pyramid Pooling)
어떤 사이즈의 input image가 들어오든 일정한 개수의 값을 return
- Comparison :
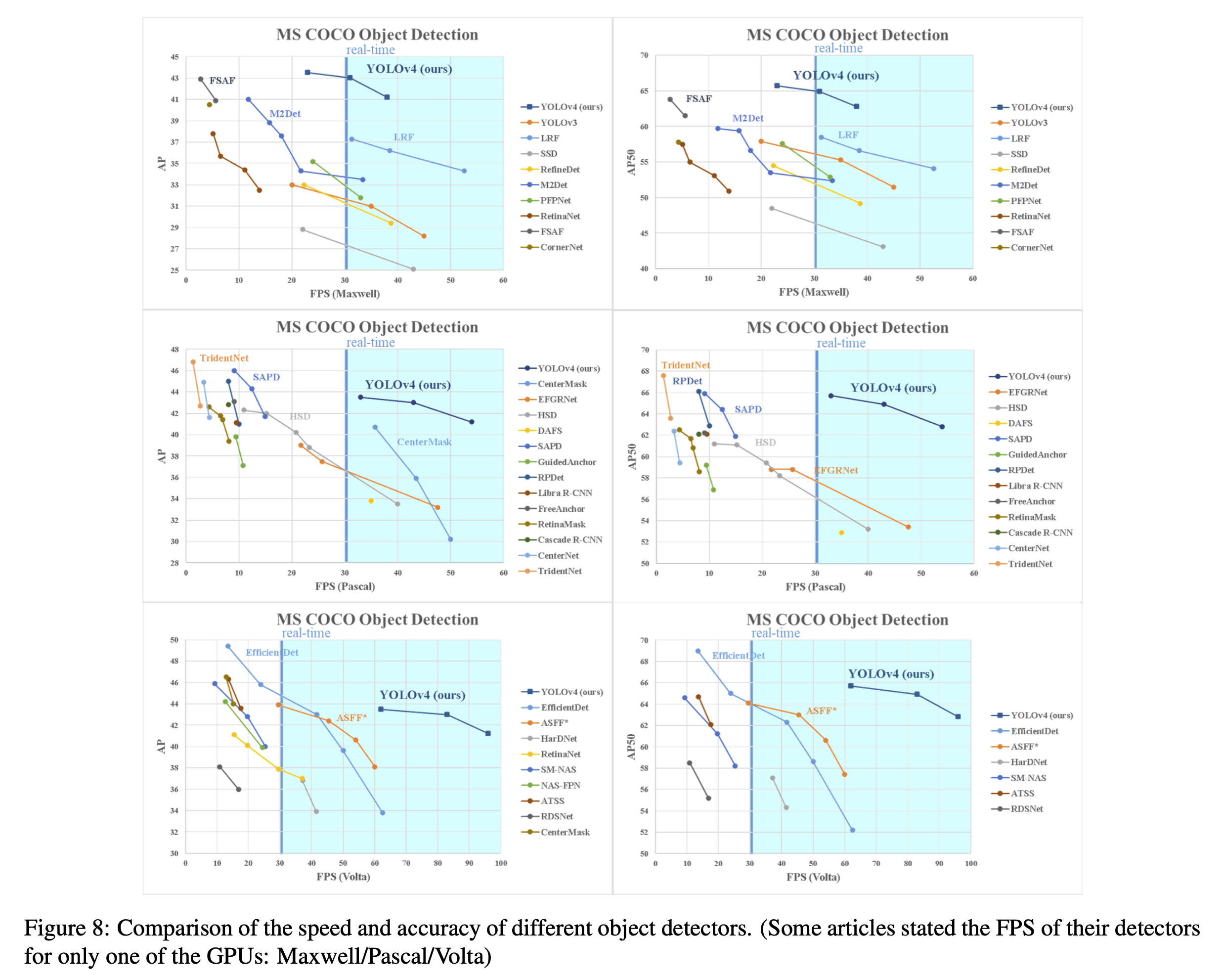
기존 v3 모델보다 AP, FPS 둘 다 10%가량 상승.
Bag of Freebies의 도입.
추론 비용을 증가시키지 않고 정확도를 향상시킨 좋은 방법.
BoF를 통해 추후 모델 연구 발전의 가능성을 제시 ( YOLOv7이 이에 해당 )
- Comparison :
YOLOv5
- No Paper and Report :
Paper와 Tech Report조차 없이 코드만 공개.
저자는 기존 v3를 Pytorch로 구현을 했던 사람.
V5는 v4 공개 2달 후인 20년 6월, v6는 21년 10월에 공개.
성능과 코드 외에는 명시한 사항이 없다.
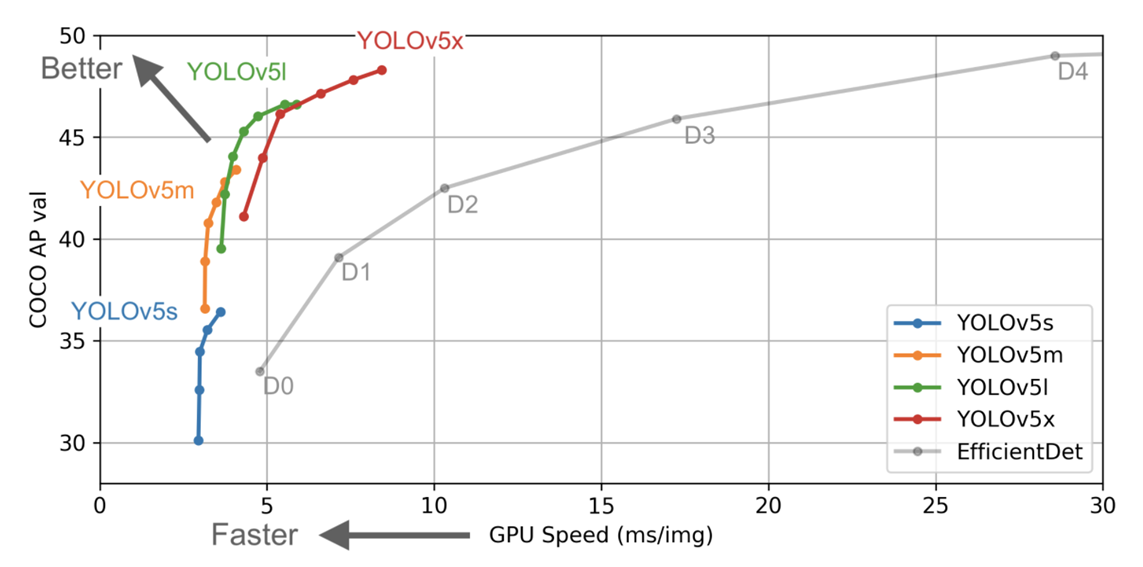
- Comparison :
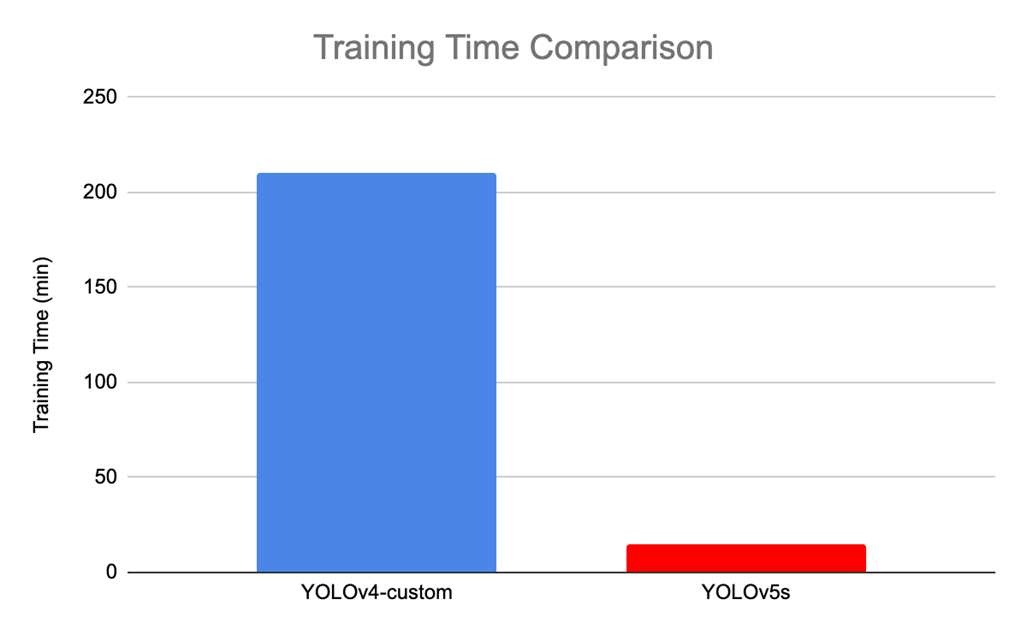
v4 보다 훨씬 빠른 training time.
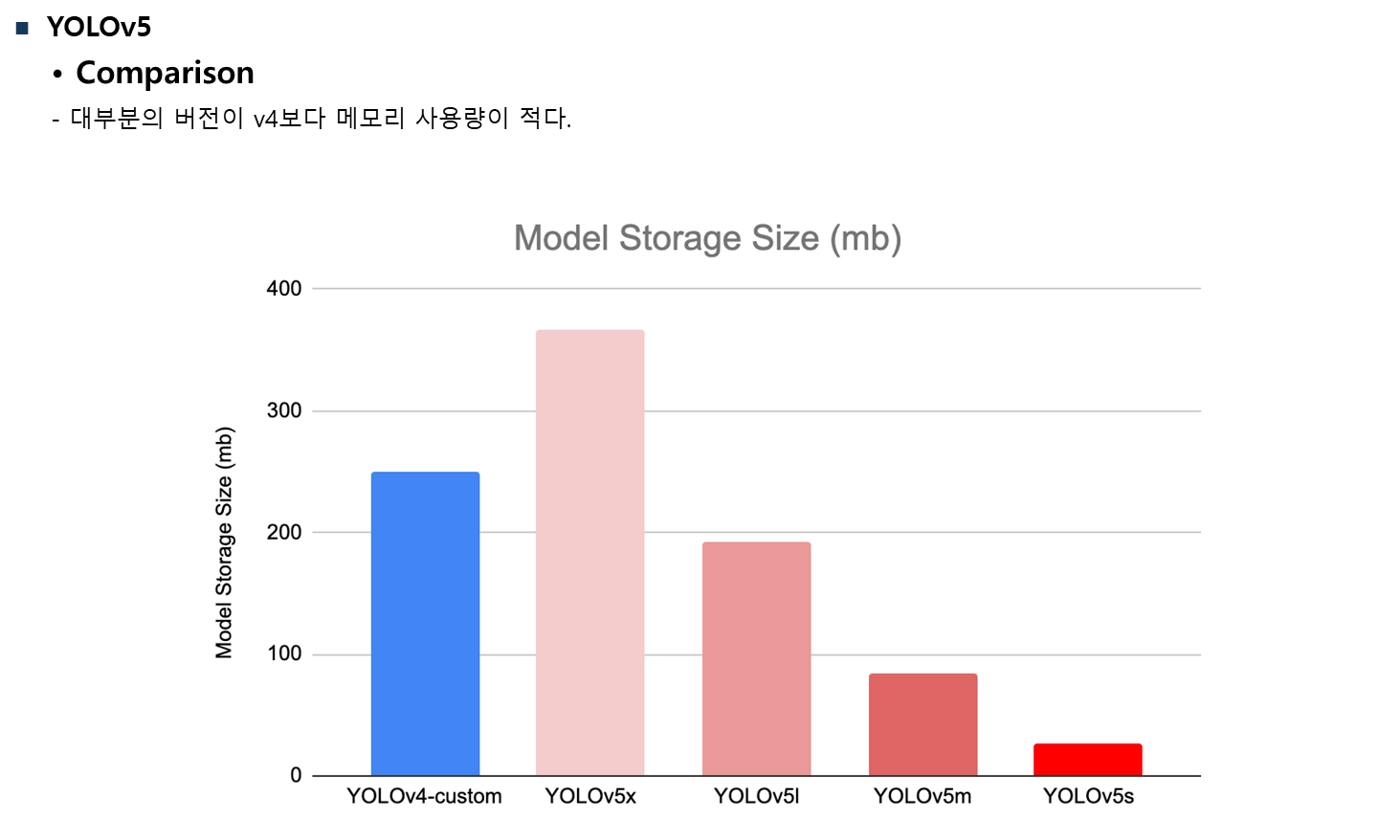
대부분의 버전이 v4보다 메모리 사용량이 적다.
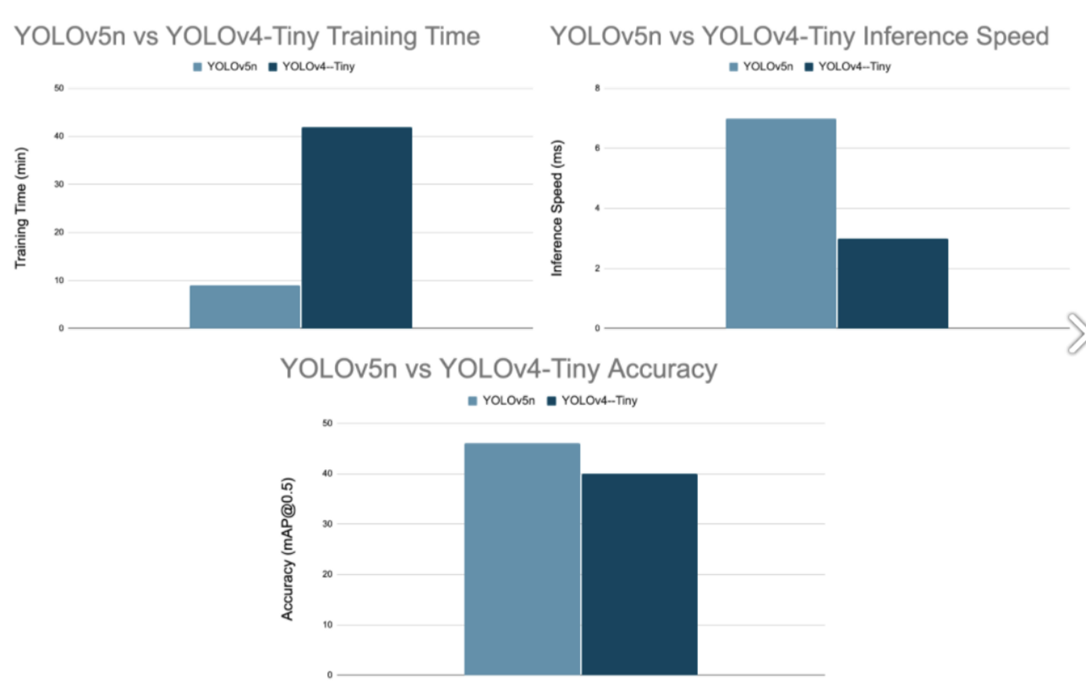
정확도, 성능면에서 모두 v4보다 향상.
-
Architecture :
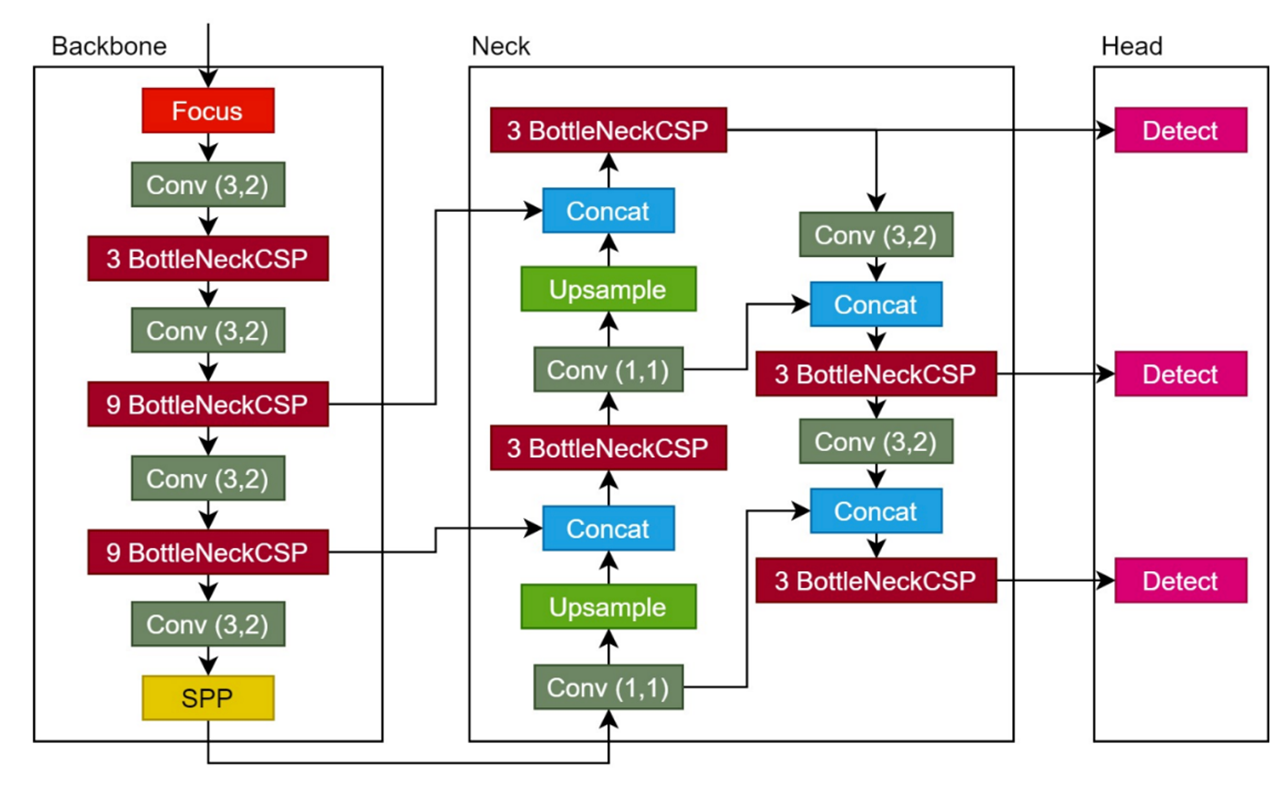
-
특징 :
최적화가 잘 되어있어 weight file 크기가 이전 모델보다 작음.
다양한 크기의 network 를 사용하여 상황에 맞는 선택이 가능 ( 속도, 정확도 trade-off ).
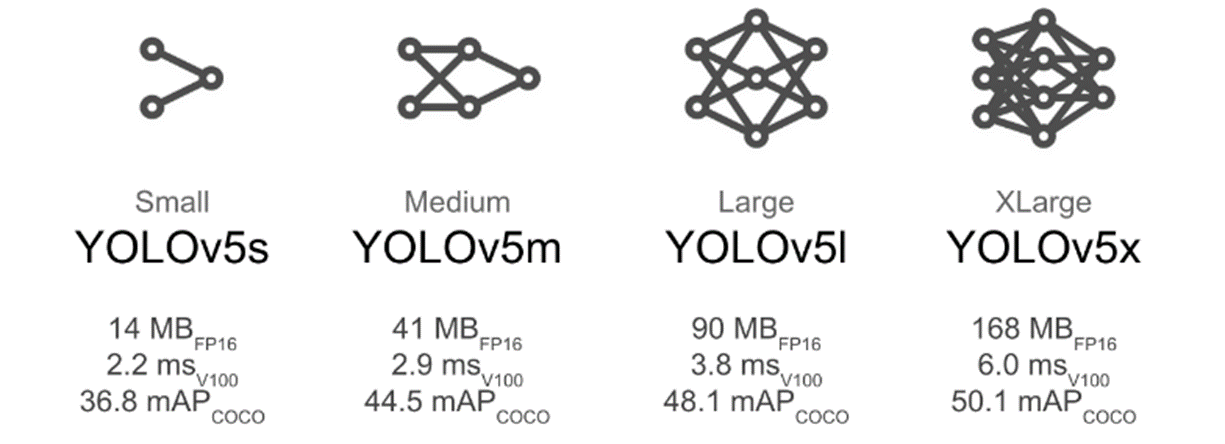
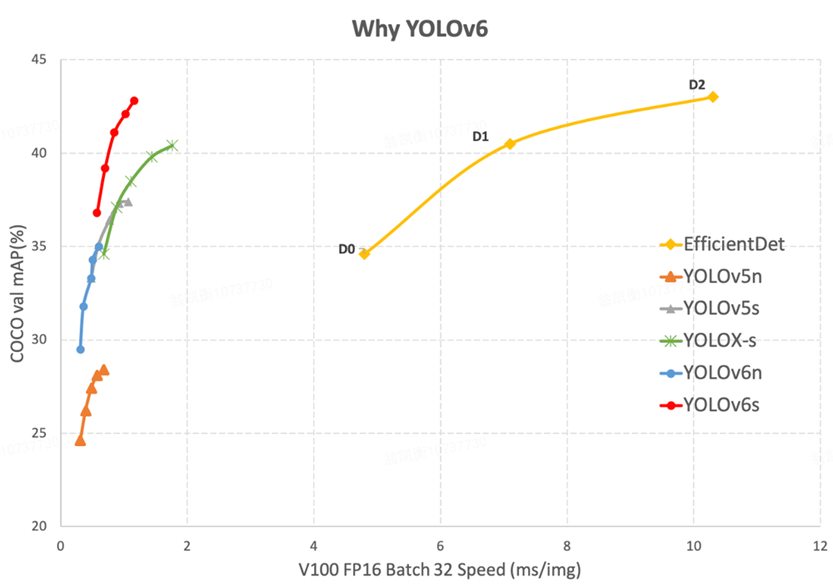
YOLOv6
- 특징 :
더 깊어진 network
Head가 3개의 scale에서 4개의 scale로 변화.
이전 v5의 대다수의 모델보다 월등히 빠른 속도를 자랑.
- Architecture :
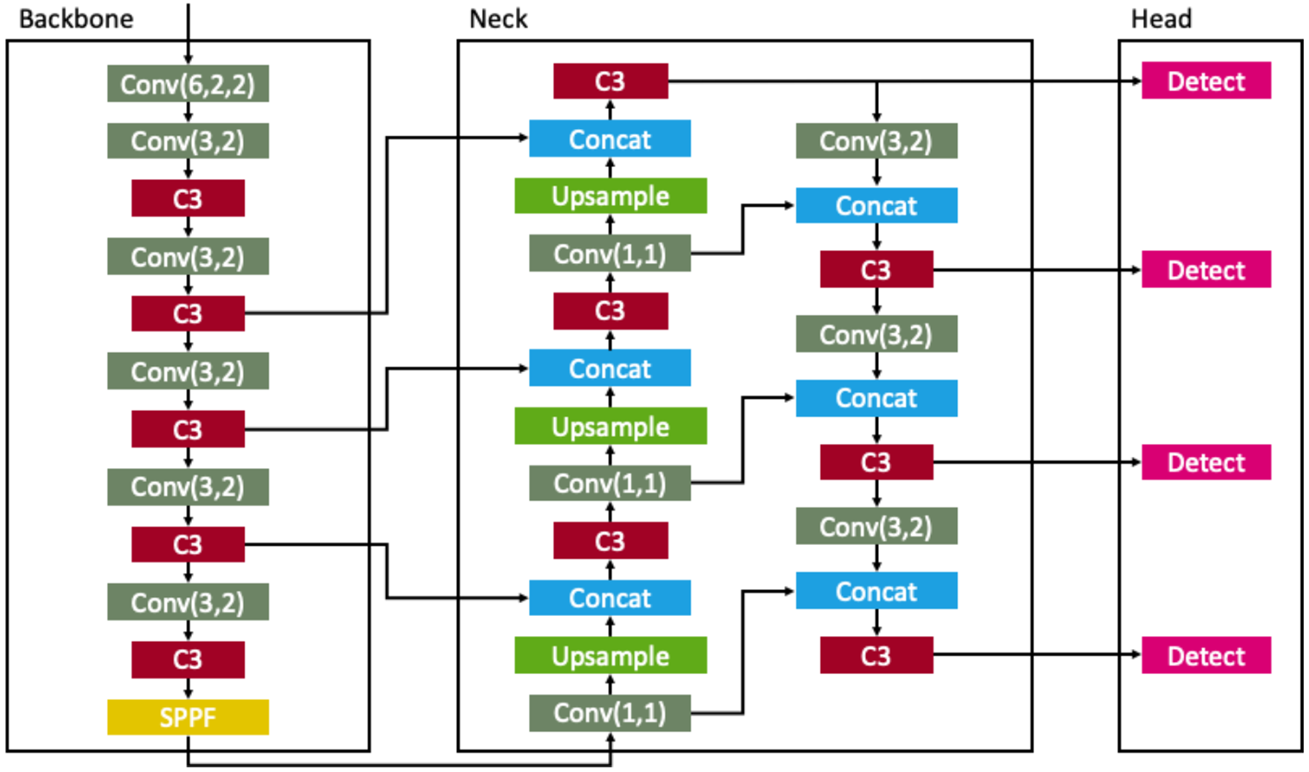
YOLO Series
전체적인 모델 변화점
- V2 부터 Anchor box 도입.
- V3 부터 multi scale의 도입으로 작은 물체 탐지 문제 완화.
- V4 부터 Mosaic, MixUp등 Augmentation 도입.
- V4까지는 C기반의 Darknet, 5부터는 Pytorch로 구현된 Backbone 사용.
- V6 부터는 기존 3개 scale로 detection 하던 것에서 4개로 늘려 더 다양한 size의 Object를 Detection.
공통적인 원론
- Unified detection 으로 비교적 빠른 Inference time 보장.
- 통계적, 수학적 개선만이 아닌, Architecture 수정, 보완으로 인한 성능 개선 가능.
- 당시 SOTA에서 제안된 방법들을 Grid Search를 통해 최고의 mAP와 FPS를 갖는 형태로 선정.
YOLO Series 선택
-
상황별 적합한 모델
속도, 성능의 Trade-Off를 고려하여 선택해야한다.
하지만, v5와 v6를 안정성 보장 없이 사용이 가능하다면 최신 버전을 사용하는 것이 가장 좋다.
Detection 해야하는 object의 크기에 따라 모델 종류 고려. -
모델 학습시의 고려 사항
High resolution 을 사용한 학습을 권장, Training data와 test data의 size가 차이날수록 정확도에 악영향.
공개된 Hardware spec이 해당 논문, 자료에 명시된 실험 당시 GPU 외에는 공개되지 않은 점.
최소 가동 GPU같은 Worst case를 고려하기 쉽지 않다.

정리 감사드립니다!!