BeautifulSoup란?
뷰티풀수프, 줄여서 뷰슾은 파이썬에서 사용할 수 있는 웹데이터 크롤링 라이브러리입니다.
사실 Selenium은 완전히 크롤링을 위한 라이브러리가 아닌, 웹개발자들이 동적 웹이 제대로 작동하는지를 테스트하기 위해서 만든 모듈이라고 합니다.
먼저 뷰슾을 사용하기 위해선 Selenium때와 마찬가지로 html의 태그를 사용하여 크롤링하기 때문에 html태그에 대한 기초적인 이해가 필요합니다.
저는 html태그, 상속에 대한 개념은 알고있는 분들만 글을 본다고 생각하고 사용법에 관해서 이야기하겠습니다.
뷰슾은 우선 bs4라는 라이브러리 내에서 BeautifulSoup라는 모듈을 가져옵니다
from bs4 import BeautifulSoup import requests url = "크롤링하려는 웹페이지의 주소" response = requests.get(url) soup = BeautifulSoup(response.content,"html.parser")
requests 모듈은 http페이지에게 요청을 보내고, 그 요청의 결과를 받아올 수 있는 함수를 가진 모듈입니다.
requests.get(url)은 url에 담겨있는 http페이지 주소를 요청하여(주소로 이동하는 것과 같음) 그 주소의 요소들을 가져올 수 있도록 연결한다고 생각하면 이해가 쉽습니다.
response라는 변수에 연결의 결과를 담고 response.content, 요청으로 받아온 결과의 내용을 html.parser라는 html해석기로 내용을 html tag 구조로 해석합니다.
해석한 결과는 soup.prettify()함수로 확인할 수 있습니다.
print(soup.prettify()실행 결과:
prettify() 함수를 사용하면 정돈 되어있지않은 html구조가 반환되지만, print()함수를 사용하여 그 결과를 출력해주면 위 사진과 같은 모습으로 들여쓰기까지 되어 보기좋게 출력됩니다.
이 모든 태그들이 soup에 담겨있습니다. 그 중에서 우리는 태그명, id, class를 사용하여 검색해서 데이터를 추출하는 방식이 바로 뷰슾의 크롤링 방법입니다.
그럼 벨로그 메인 페이지의 정보를 간단히 크롤링하면서 다른 함수를 사용해보겠습니다.
우선 뷰슾의 가장 큰 한계점은 바로 동적인 크롤링이 안된다는것. 버튼을 누르거나 값을 입력하거나 하는 페이지와의 동적 상호작용이 불가능합니다.
하지만 웹페이지의 모든 정보를 이미 soup에 전부 가져온 뒤 정보를 추출한다는 점에서 셀레니움보다 훨씬 빠르다는 장점이 있습니다.
find
뷰슾에서 사용하는 추출 방식은 find와 select가 있습니다.
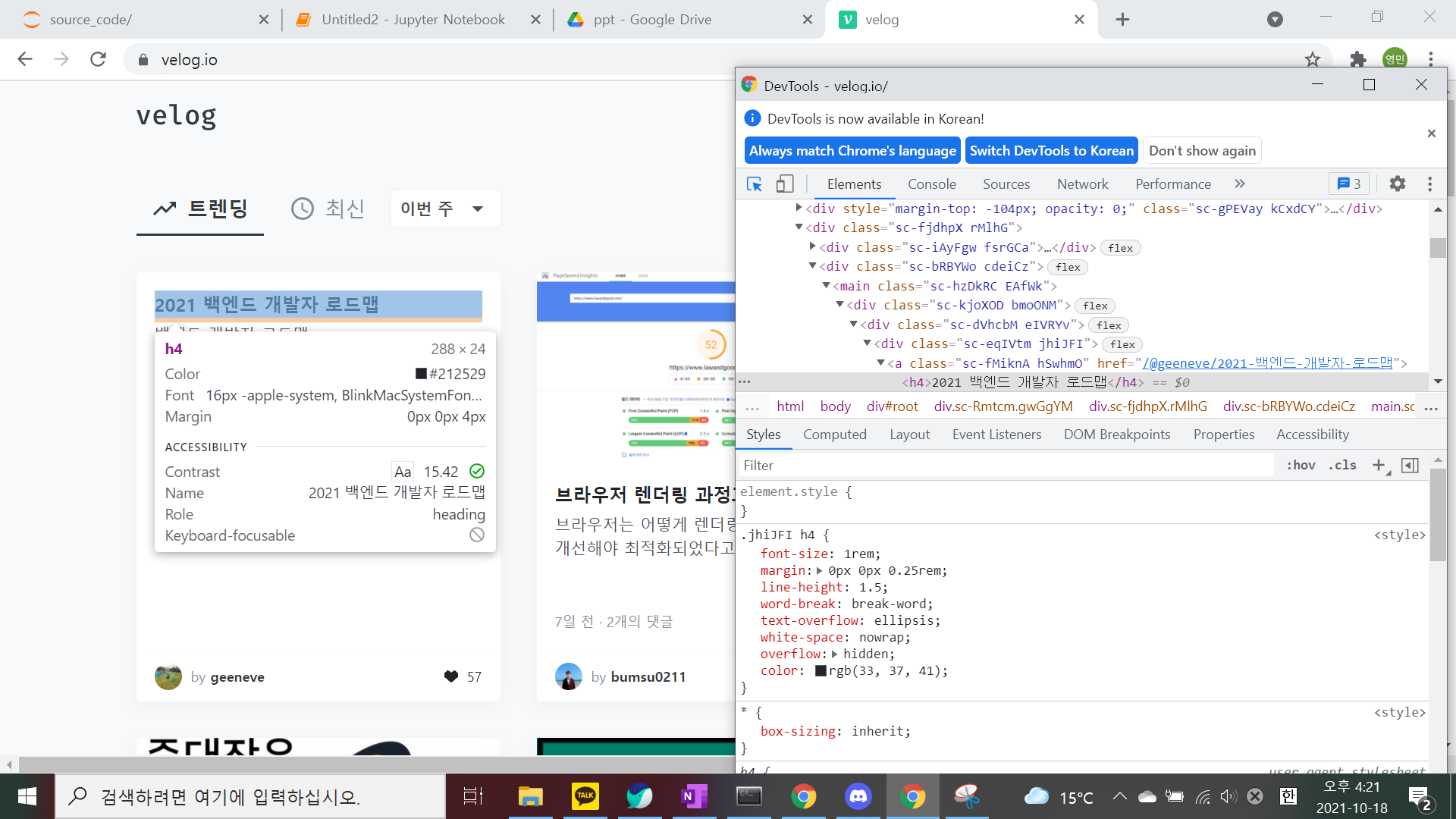
위 사진처럼 개발자 도구를 이용하여 원하는 부분(ex : 게시글 명)의 html태그와 css를 알아내 find함수의 인자로 주어 값을 가져올 수 있습니다.
soup.find("h4")실행 결과 :
<h4>2021 백엔드 개발자 로드맵</h4>
find 함수는 html의 내용을 위에서부터 읽어내려오면서 h4라는 태그를 발견하면 그 값을 반환하고 종료하는 방식이라고 생각하면 됩니다.
그렇기 때문에 원하는 부분을 추출한다거나 여러 값을 추출하는데 부적절하여 find_all()을 사용합니다
soup.find_all("h4")실행 결과 :
<h4>2021 백엔드 개발자 로드맵</h4>, <h4>브라우저 렌더링 과정과 최적화</h4>, .....(생략) <h4>도커 컴포즈를 이용한 Express-Typescript-MySQL 개발환경 구축</h4>, <h4>브라우저 최적화</h4>, <h4>있어보이는 README 작성법</h4>, <h4>15. Deep Generative Models for Graphs</h4>
위 결과처럼 페이지 내의 모든 h4를 가져옵니다.
하지만 태그만으로는 원하는 값을 선택해서 가져올 수 없기 때문에 저는 select() 함수를 더 선호합니다.
len(soup.select("#root > div.sc-Rmtcm.gwGgYM > div.sc-fjdhpX.rMlhG > div.sc-bRBYWo.cdeiCz > main > div > div > div.sc-eqIVtm.jhiJFI > div > span"))실행 결과 :
3len(soup.select("span"))실행 결과:
96
select함수는 select()와 select_one()함수가 있는데, find와 반대로 기본형인 select가 해당하는 모든 요소를 추출하는 함수입니다. css요소들 상속, class명, id명 등을 사용하여 선택할 수 있어 효율적인 사용이 가능합니다.
html요소를 사용하여 찾아온 값들에서 우리가 원하는 텍스트를 추출하는 과정까지가 우리가 원하는 값을 찾는 방법입니다.
가져온 요소에서 text나 get("href) 같은 방법을 통해 텍스트나 링크주소를 추출할 수 있습니다.
link = soup.select("a")[14].get("href") text = soup.select("a")[14].text link,text실행 결과 :
'/@jeon3029/코딩테스트-준비-사이트-모음집단순링크만', '코딩테스트 준비 사이트 모음집(단순링크만)사이트 링크 모음집'
위의 예시 코드까지가 하나의 요소를 추출하는 과정이었고, 이러한 과정을 for문이나 함수화해서 많은 데이터를 추출하여 pandas를 사용해 DataFrame으로 만드는 과정까지가 크롤링의 주 목적입니다.
