
row를 column으로 출력하기 (sum + decode)

select sum(decode(deptnom,10, sal,0)) as "10",
sum(decode(deptnom,20, sal,0)) as "20",
sum(decode(deptnom,30, sal,0)) as "30" -- 숫자를 alias로 사용할 땐 더블 쿼테이션
from emp;여기서 0이 아니라 null을 사용하면 성능이 훨씬 좋아짐 (혹은 아예 아무것도 작성하지 않으면, null값을 명시한 것과 같음)
oracle은 null값을 연산에서 무시하기 때문에 연산 효율이 더 좋은 편이다.
select sum(decode(deptnom, 10, sal, null)) as "10",
sum(decode(deptnom, 20, sal, null)) as "20",
sum(decode(deptnom, 30, sal, null)) as "30" -- 숫자를 alias로 사용할 땐 더블 쿼테이션
from emp;row를 column으로 출력하기 : PIVOT
PIVOT(그룹함수 FOR 기준 컬럼 IN (데이터1, 데이터2 ...))
IN LINE VIEW (FROM절 서브쿼리)
: 쿼리문이 가장 처음 실행되는 FROM절에 새로운 쿼리를 작성하는 방식 SELECT *
FROM (SELECT DEPTNO, SAL FROM EMP) // 필요한 컬럼만 가져와서 출력
PIVOT ( SUM(SAL) FOR DEPTNO IN (10,20,30) ); -- 10,20,30에 대한 토탈월급을 출력서브쿼리를 불러올 때 1차적으로 선별하여 불러오기 위해 작성해야 함
<- 부서번호와 월급 칼럼이 필요
SELECT "10"
FROM (SELECT DEPTNO, SAL FROM EMP) // 필요한 컬럼만 가져와서 출력
PIVOT ( SUM(SAL) FOR DEPTNO IN (10,20,30) ); -- 10,20,30에 대한 토탈월급을 출력"10" 칼럼에 대해서만 출력됨

COLUMN을 ROW로 출력하기 : UNPIVOT
unpivot(컬럼별칭(값) FOR 컬럼별칭(열) in (데이터1, 데이터2 ...))
unpivot문 작성 시 쿼테이션 마크는 작성하지 않아도 괜찮음
in() 안에 컬럼으로 구분된 이름들을 모두 작성해야 함
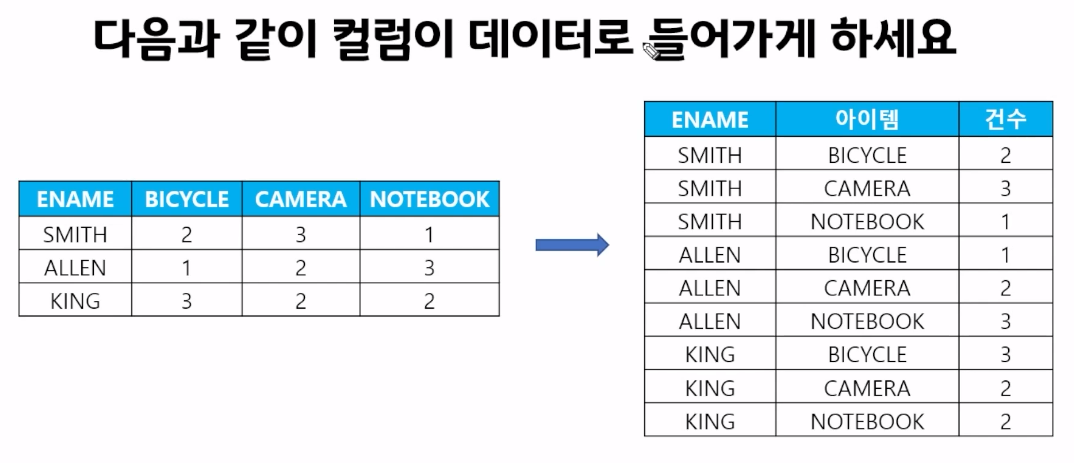
select *
from order2
unpivot ( 건수 for 아이템 in (BICYCLE, CAMERA, NOTEBOOK));
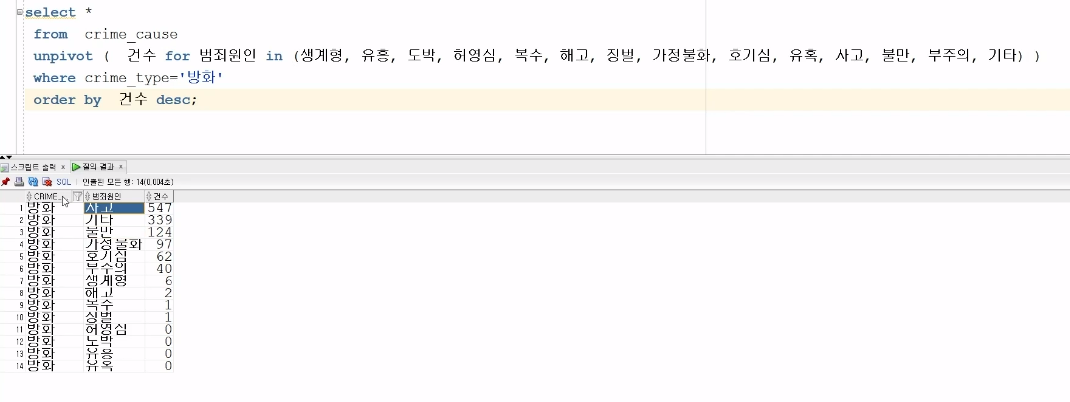
order by 절은 select절 다음에 실행되므로 alias가 적용된 이름을 사용함

성장하는 개발자