머신러닝 이론 정리
1.머신러닝
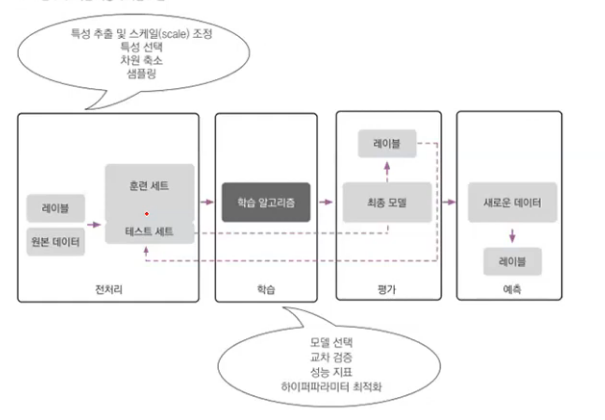
순서형 변수일 때onetime -> 1 twotime -> 2 ..... 범주형 변수일 때OneHotEncoder, 요일, LabelEncoderStandardScaler숫자형 자료를 표준화로 변환결정나무, 랜덤 포레스트, 나이브 베이즈 분류 : 원본 데이터 그대
2.confusion matrix
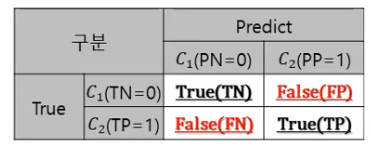
대칭적 상대적인 표현들정확도(Accuracy) vs 오류율(Error Rate) TPR (True Positive Rate) vs FPR ( False Positive Rate)민감도 vs 특이도재현율 vs 정밀도정확도 : 클래스 0과 1 모두를 정확하게 분류오류율
3.과대,과소적합
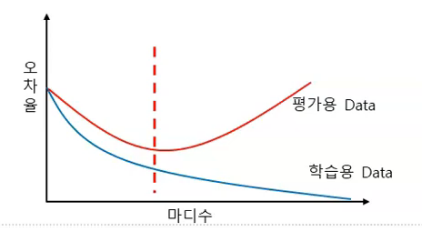
학습용 데이터에 완전히 적합학습용 집합에서 잡음(noise)도 모형화하기 때문에 평가용 집합에서 전체 오차는 일반적으로 증가학습용 Data에서는 높은 성과 => 평가용 Data에서는 낮은 성과 ( x )현재 데이터의 설명 => 미래 데이터 예측 ( O )훈련, 검증 정
4.모델 최적화
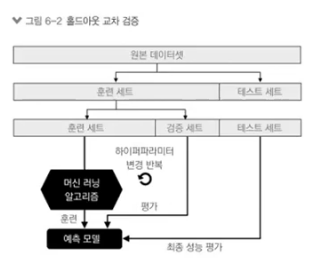
모델의 성능을 검증하기 위한 방법홀드아웃 검정K-fold 검정홀드아웃 검정훈련 데이터 / 테스트 데이터를 나눈다.훈련 데이터로 모델을 만든다.테스트 데이터로 성능 평가문제점 모델을 변경하는 방법론최적화 파라미터를 찾기 어렵다. ( max_depth...) 일일이 대입해
5.의사결정나무
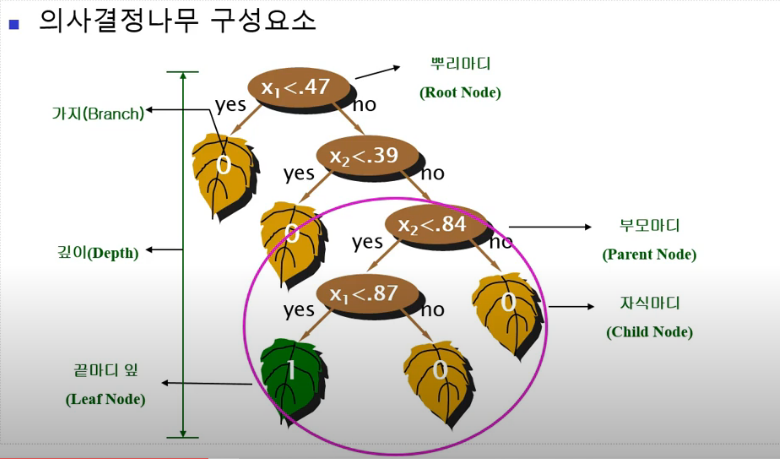
의사결정규칙(decision rule)을 나무 구조로 도표화하여 분류(classification)와 예측(prediction)을 수행하는 분석 방법Tree and rule 구조규칙(rule)은 나무 무델로 표현결과는 규칙으로 표현재귀적 분할 나무 만드는 과정 -> 계속
6.연관규칙
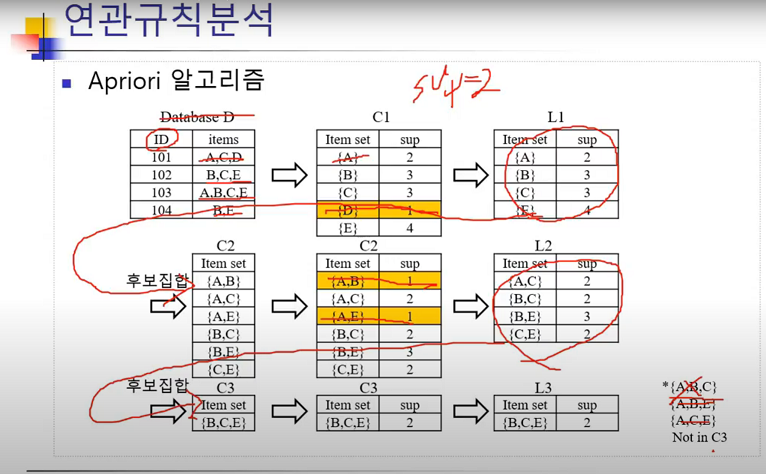
마케팅 전략상 유용한 결과가 나온 경우ex) 주말을 위해, 목요일 소매점에 기저귀를 사러 온 아빠들은 맥주도 함께 구매 -> 주말에 football을 보면서 마심기존의 마케팅 전략에 의해 연관성이 높게 나온 경우ex) 정비 계약을 맺은 소비자들은 많은 설비를 구매 ->
7.앙상블
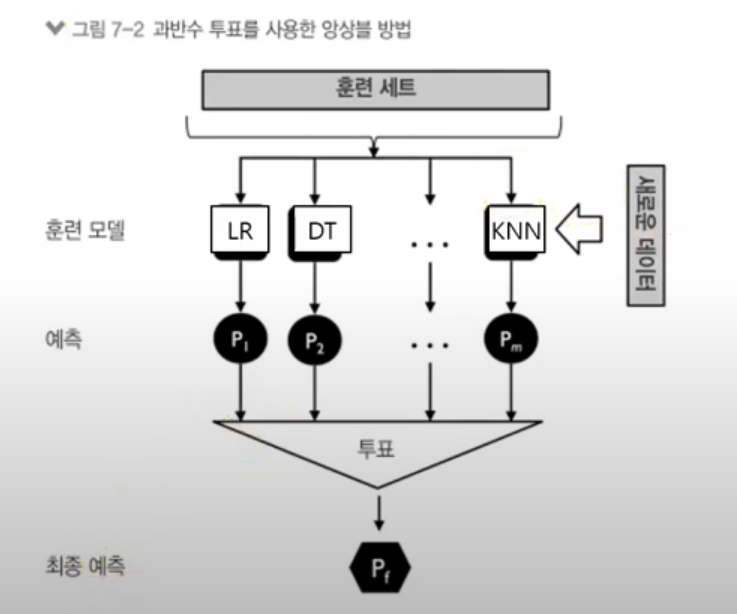
앙상블 학습이란과반수 투표 분석배깅 분석랜덤 포레스트 분석부스팅 분석여러 분류기( 모델 )를 하나의 메타 분류기로 연결( 통합한다는 의미가 강하다) 하여 개별 분류기보다 더 좋은 일반화 성능을 달성여러 분류 알고리즘 사용 : 다수결 투표하나의 분류 알고리즘 이용 : 배