학습계기
PPB(PingPongBall) Depth Estimation을 진행하다가 발생한 문제이다.
Depth Estimation 방법으로 Geometrical Depth Estimation 방법을 사용하였는데 종방향거리 증가에 따라 오차가 발생했다. 따라서 적절한 보정이 필요했고, 급한대로 4개의 Point를 구해서 {(22.5, 35) (45, 71) (67.5, 112) (90, 150)} / {(23.0443) (44.0179) (67.9045) (90.0433)} 이를 보정하기 위한 함수를 적용하였다.
그 결과 값이 정밀하게 나왔다.

- Vision-based Acc with a Single Camera: Bounds on Range and Range Rate Accuracy논문 에서 발췌
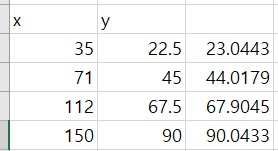
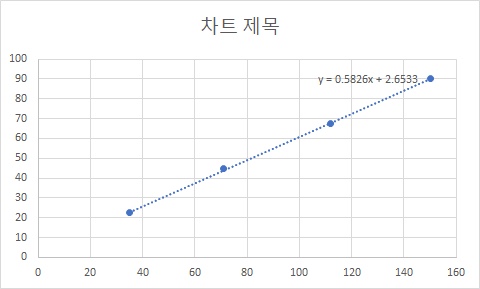
- 차트를 보면 그 그래프가 단순한 선형에 가깝다고 볼 수 있다. 하여 선형회귀를 이용하면 좀 더 정밀한 값이 나올것으로 사료되어 포인트에 대해 선형회귀를 적용해 보기로 하였다.
선형회귀란?
- 주어진 x와 y값을 토대로 서로의 관계를 파악하는 것
- 그 결과, 새로운 x값이 주어졌을 때 y값을 쉽게 유추
선형회귀의 종류
- 1 단순 선형 회귀 분석(Simple Linear Regression Analysis)
독립변수 x와 곱해지는 값 w를 머신러닝에서 가중치(weight), 별도로 더해지는 값 b를 편향(bias)이라고 한다. 직선의 방정식에선 각각 직선의 기울기와 절편을 의미한다. w와 b가 없이 y와 x란 수식은 y는 x와 같다는 하나의 식밖에 표현하지 못한다. 그래프 상으로 말하면 하나의 직선밖에 표현하지 못한다. w와 b값에 따라 x, y가 표현하는 직선은 무궁무진하다. - 2 다중 선형 회귀 분석(Multiple Linear Regression Analysis)
위의 수식은 다중 선형 회귀 분석을 보여준다. 단순 선형 회귀 분석과는 다르게 여러 요소를 고려할때 쓰는 방법이다. 가령 사람의 나이를 예측한다고 가정하면, 성별, 앓고있는 질병, 가족력, 등등 고려할 요소가 많은데 이렇게 다수의 요소를 가지고 분석을 할때 사용하는것이 다중 선형 회귀 분석이다. 위와 같은 상황에는 단순 선형 회귀분석이 좀 더 적절하다고 판단되어, 선형회귀를 적용하기로 하였다.
%tensorflow_version 2.x
import tensorflow.compat.v1 as tf
print(tf.__version__)
device_name = tf.test.gpu_device_name()
if device_name != '/device:GPU:0':
raise SystemError('GPU device not found')
else:
print('Find GPU at: {}'.format(device_name))
# 학습 데이터로 4개의 점을 준다.(22.5, 35.5), (45, 71), (67.5, 112), (90, 150)
x_train = [22.5, 45, 67.5, 90]
y_train = [35.5, 71, 112, 150]
# Weight, bias는 추정할 y = Wx + b의 기울기(Weight)와 절편 (bias)
W = tf.Variable(tf.random_normal([1]), name = 'weight')
b = tf.Variable(tf.random_normal([1]), name = 'bias')
# y = wx + b 라는 뜻
hypothesis = x_train * W + b
# 내가 추정한 값 - 실제값을 제곱해준 것 cost(비용)함수
# 추정값이 실제값과 같은것이 가장 이상적인 상황이므로 cost가 0으로 되는 과정이 필요하다.
cost = tf.reduce_mean(tf.square(hypothesis - y_train))
# 경사하강법 적용
optimizer = tf.train.GradientDescentOptimizer(learning_rate = 0.000001)
train = optimizer.minimize(cost)
session = tf.Session()
session.run(tf.global_variables_initializer())
# 10000번 반복으로 cost가 0이 되는 부분을 찾을 것.
# session.run(train): 학습 시작
# 결과값 출력 weight와 bias를 보겠다.
for i in range(1000000001):
session.run(train)
if i % 100 == 0:
print(i, session.run(cost), session.run(W), session.run(b))- Google colab 환경에서 진행하였습니다.
결과
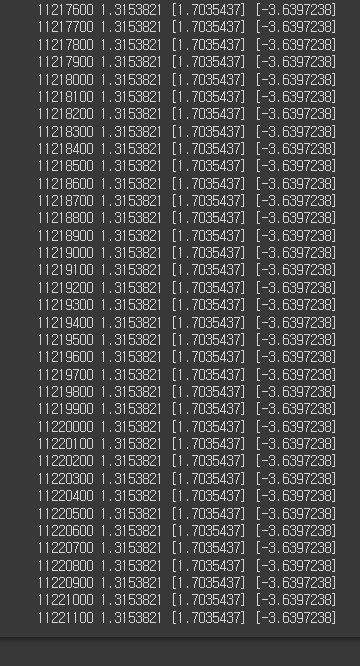
- 11221100번 돌린 결과이다. cost가 0에 가까울수록 이상적인 값이다. 하지만 cost값이 1.3153821에서 더이상 떨어지지 않아 여기까지 진행하였다. 이때의 W값은 1.7035437, bias 값은 -3.6397238이 나왔다.
따라서 함수는 라는 일차함수에 가까움을 알 수 있다. 또한 이번에는 포인트를4개만 잡았는데, 좀 더 많고 정확한 포인트를 잡는다면 그 값이 더 정확하게 나올것으로 사료된다.
