정렬: 데이터를 특정한 기준에 따라 순서대로 나열하는 것
정렬 문제의 유형
정렬 라이브러리를 사용하여 풀 수 있는 문제
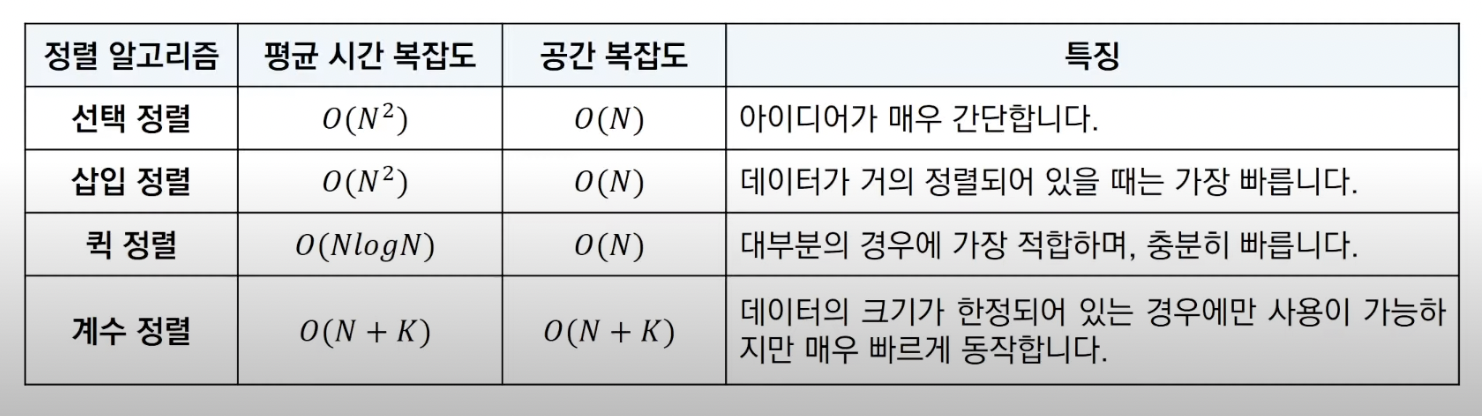
일반적으로 퀵 정렬보다 느리지만 최악의 경우에도 O(NlogN)의 시간복잡도 보장
리스트.sort() # 원본 리스트 변형
리스트2 = 리스트1.sorted() # 원본 리스트를 정렬하지 않고 정렬된 리스트 반환정렬 알고리즘의 원리에 대해 물어보는 문제
선택 정렬, 삽입 정렬, 퀵 정렬 등의 원리를 알아야 풀 수 있는 문제
더 빠른 정렬이 필요한 문제
퀵 정렬 기반의 정렬 기법으로는 풀 수 없으며 계수 정렬 등의 다른 정렬 알고리즘을 이용하거나 문제에서 기존에 알려진 알고리즘의 구조적 개선을 거쳐야 풀 수 있는 문제
Swap
파이썬에서 리스트 안의 두 원소의 위치를 바꾸는 방법
일반적으로 다른 언어에서는 아래 방법과 달리 별도의 임시 저장용 변수를 만들어야 구현할 수 있음
array = ['a', 'b']
array[0], array[1] = array[1], array[0]
print(array) # ['b', 'a']정렬 알고리즘 비교
대부분의 프로그래밍 언어에서 지원하는 표준 정렬 라이브러리는 최악의 경우에도 O(NlogN)의 복잡도를 보장하도록 설계되어 있음 -> 추가적인 조건이 없다면, 해당 언어의 정렬 라이브러리를 사용하여 정렬하는 것이 효율적
선택 정렬
처리되지 않은 데이터(범위) 중 가장 작은 데이터를 선택해 맨 앞에 있는 데이터와 바꾸는 것을 반복
이중 반복문으로 구현 가능
O(N2)의 시간 복잡도를 가짐
N + N-1 + N-2 + ... + 2 = (N2+N-2)/2
# 예시 리스트
array = [7,5,9,3,1,6,2,4,8]
for i in range(array)
min_index = i # 가장 작은 원소의 인덱스
# 처리되지 않은 범위 내에서 가장 작은 원소의 인덱스 구하기
for j in range(i+1, len(array))
if array[min_index] > array[j]:
min_index = j
array[i], array[min_index] = array[min_index], array[i]삽입 정렬
처리되지 않은 데이터를 하나씩 골라 적절한 위치에 삽입
선택 정렬보다 구현 난이도가 높지만 일반적으로 시간복잡도 측면에서 보다 효율적
첫 번째 원소부터 차례로 순회하면서 직전에 처리된 범위에서 해당 원소가 어느 위치로 들어가면 될지 판단하여 처리(알맞은 위치에 삽입) - 이중 반복문으로 구현
리스트의 데이터가 이미 거의 정렬되어 있는 상태라면 매우 빠르게 동작하는 정렬 방식(만약 이미 모든 데이터가 정렬되어 있는 상태라면 O(N)의 시간 복잡도를 가짐)
시간 복잡도는 O(N2)
# 예시 리스트
array = [7,5,9,3,1,6,2,4,8]
for i in range(1, len(array)):
for j in range(i, 0, -1): # 인덱스 i, i-1, ... 1까지 1(step)씩 감소하며 반복
# 왼쪽에 있는 원소와 비교하여 더 작으면 왼쪽에 있는 원소 앞에 삽입
if array[j] < array[j-1]:
array[j], array[j-1] = array[j-1], array[j]
else:
break퀵 정렬
기준 데이터를 고른 후 그 기준 데이터보다 큰 데이터과 기준 데이터보다 작은 데이터의 위치를 바꾸는 방법(기본적으로는 첫 번째 데이터를 기준pivot으로 지정)
일반적인 데이터 정렬에서 자주 사용되며, 대부분 프로그래밍 언어의 정렬 라이브러리의 근간으로 매우 자주 사용
바꾸다가 위치가 엇갈린 경우에는 작은 데이터와 기준pivot값의 위치를 바꿔줌
정렬을 위한 범위를 좁히면서 재귀적으로 수행
평균적으로 O(NlogN)의 시간 복잡도, 최악의 경우에는 O(N2)의 시간복잡도를 가짐
- 기본 코드
# 예시 리스트
array = [7,5,9,3,1,6,2,4,8]
def quick_sort(array, start, end):
if start > end:
return
pivot = start
left = start + 1
right = end
while(left <= right):
while(left<=end and array[left]<=array[pivot]):
left += 1
while(right>start and array[right]>=array[pivot]):
right -= 1
if(left>right):
array[right], array[pivot] = array[pivot], array[right]
else:
array[left], array[right] = array[right], array[left]
quick_sort(array, start, len(array)-1)- 보다 간결하게 작성한 코드
# 예시 리스트
array = [5,7,9,0,3,1,6,2,4,8]
def quick_sort(array):
if len(array) <= 1:
return array
pivot = array[0]
tail = array[1:]
left_side = [x for x in tail if x<=pivot]
right_side = [x for x in tail if x>pivot]
return quick_sort(left_side) + [pivot] + quick_sort(right_side)계수 정렬
데이터 중 최솟값 ~ 데이터 중 최댓값의 범위가 모두 담길 수 있도록 새 리스트 생성
-> 데이터의 값을 순회하면서 데이터의 값과 새 리스트의 인덱스의 값이 같은 경우 리스트의 해당 인덱스 값에 +1
-> 새 리스트를 순회하면서 첫 번째 인덱스부터 하나씩 그 값만큼 인덱스를 출력
데이터의 개수가 N, 데이터(양수)중 최댓값이 K일때 최악의 경우에도 시간복잡도 O(N+K)를 보장
특정 조건이 부합할 때만 사용할 수 있지만 그 조건에서 사용하면 매우 빠르게 동작
- 특정 조건: 데이터의 크기 범위가 제한되어 정수 형태로 표현할 수 있어야 함
데이터의 범위가 크고 간격이 넓을 수록 비효율적이고, 동일한 값을 가지는 데이터가 많을수록 효율적
# 모든 원소의 값이 0 이상이라고 가정한 예시 리스트
array = [7,5,9,0,3,1,6,2,9,1,4,8,0,5,2]
count = [0] * len(array)
for i in range(len(array)):
count[array[i]] += 1
for i in range(len(count)):
for j in range(count[i]):
print(i, end=' ')
이런 유용한 정보를 나눠주셔서 감사합니다.