SQL 구문 기초
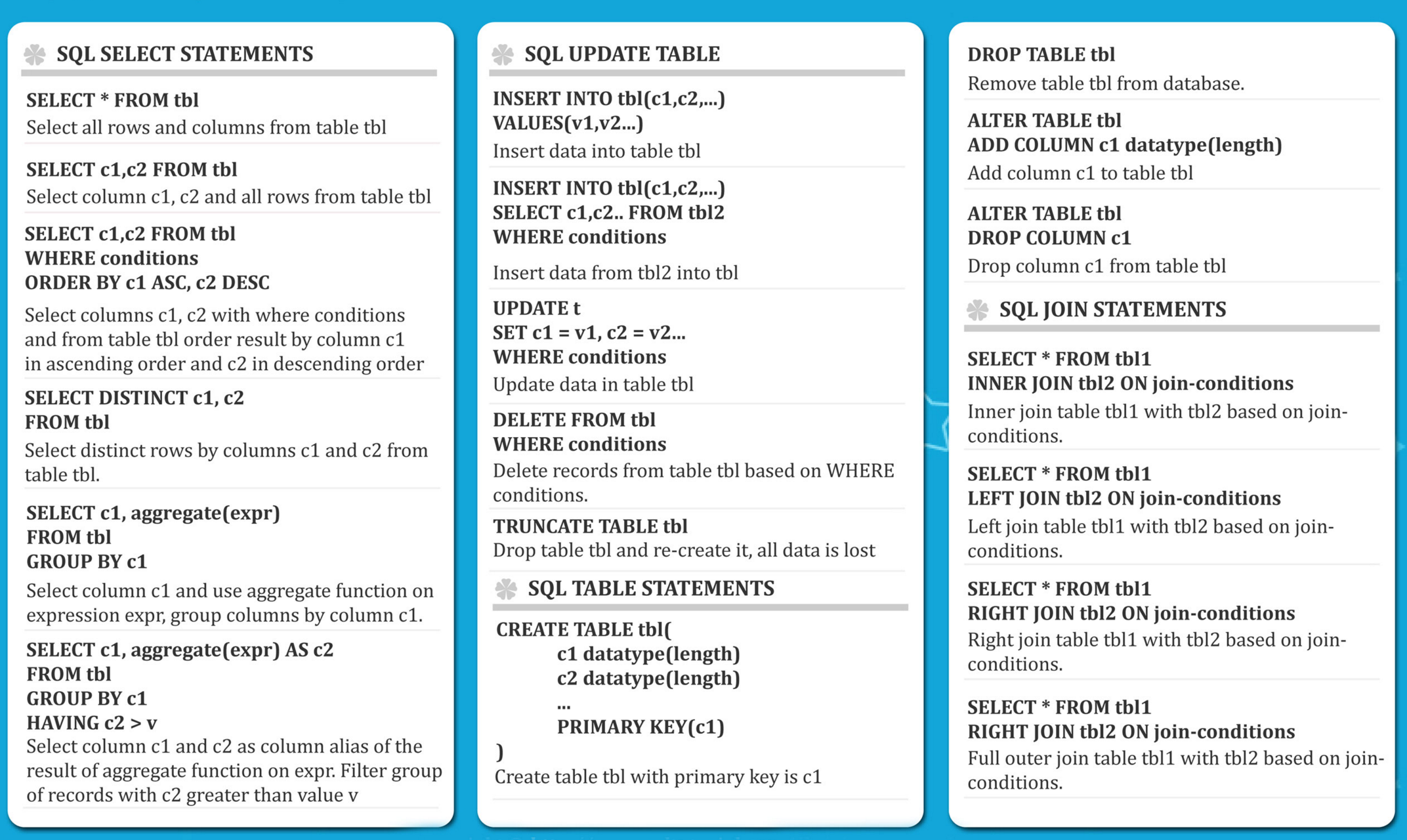
MYSQL, ORACLE등에도 적용 가능(종종 문법이 다른 경우가 있으므로 유의할 것)
대문자 표기와 ; 표기는 가독성을 높이기 위한 것
열 제목은 SQL 구문명과 중복되지 않게 조심할 것
선택(SELECT) -> 필터링(WHERE) -> 집계(GROUP BY) -> 재집계(HAVING) -> 정렬(ORDER BY)
SELECT
SELECT 컬럼명 FROM 테이블명
SELECT DISTINCT 중복값을제외할컬럼명 FROM 테이블명
SELECT DISTINCT (중복값을제외할컬럼명) FROM 테이블명 --DISTINCT의 대상이 되는 컬럼을 명확히 하고 싶을 때작동 원리: 참조하는 테이블명을 먼저 검토 후 컬럼명을 검토
모든 데이터를 전부 가져오고 싶다면 *사용(트래픽 증가)
중복값을 제외하고 싶은 컬럼명 앞에 DISTINCT 사용(UNIQUE한 값만 반환)
DISTINCT의 대상이 되는 컬럼을 명확히 하고 싶을 때 괄호() 사용 가능
DISTINCT를 사용할 경우 NULL도 값으로 카운트됨
COUNT
SELECT COUNT(행수를세고싶은컬럼명) FROM 테이블명특정 쿼리 조건에 맞는 입력 행의 갯수를 반환
괄호가 반드시 있어야 함
모든 데이터를 전부 가져오고 싶다면 COUNT(*)사용(트래픽 증가)
DISTINCT와 함께 사용하여 컬럼의 고유한 값의 갯수를 알 수 있음
SELECT WHERE
SELECT 컬럼1,컬럼2
FROM 테이블명
WHERE --조건1--
AND --조건2--조건
- 비교 연산자:
=><>=<=<>(!=) - 논리 연산자:
ANDORNOT을 통해 여러 조건 연립 가능 - BETWEEN 연산자: 값을 값 범위(이상/이하)와 비교할 때 사용, NOT을 함께 사용하여 범위 초과나 미만인지를 연산할 수도 있음. 날짜는
'YYYY-MM-DD'형식을 사용해야 함(당일 자정 기준, 시분초0:00도 포함한다는 사실에 유의) - IN
조건이 반복될 때, OR문을 반복하는 대신 AND IN을 사용할 수 있음SELECT 컬럼1,컬럼2 FROM 테이블명 WHERE 컬럼1 IN (조건1, 조건2, ... )
NOT과 결합 가능 - LIKE, ILIKE
문자열 데이터에 대한 패턴 매칭SELECT 컬럼1,컬럼2 FROM 테이블명 WHERE 컬럼1 LIKE 'A%' --A로 시작하는 모든 문자 매칭 WHERE 컬럼1 LIKE '%A' --A로 끝나는 모든 문자 매칭 WHERE 컬럼1 LIKE '%A%' --A가 중간에 들어가는 모든 문자 매칭 WHERE 컬럼1 LIKE 'A_' --A 뒤에 글자 하나가 있는 모든 문자 매칭 WHERE 컬럼1 LIKE '__A%' --A 앞에 글자 두개가 있고, A 뒤에 문자가 있는 모든 문자 매칭
LIKE대소문자 구분
ILIKE대소문자 구분X
와일드카드%_사용
%문자의 순서나 문자의 수(0개도 가능)에 관계 없이 매칭
_단 하나의 문자와만 매칭, 문자열 내에 있는 하나의 문자만 사용
REGEX 등의 정규 표현식으로 확장 응용 가능
ORDER BY
SELECT 컬럼1,컬럼2
FROM 테이블명
ORDER BY 컬럼1 ASC, ORDER BY 컬럼2 DESC열의 값에 따라 결과를 오름차순ASC 혹은 내림차순DESC으로 정렬(디폴트는 ASC)
문자열 기반 열: 알파벳 순(A~ / Z~)
숫자 기반 열: 번호순(0~ / ~0)
LIMIT
SELECT 컬럼1,컬럼2
FROM 테이블명
ORDER BY 컬럼1 ASC, ORDER BY 컬럼2 DESC
LIMIT 표시하고싶은행의갯수쿼리에 대해 반환되는 행의 개수를 제한할 수 있는 명령어
상위 몇 개의 행만 표시하고 싶을 때 사용
주로 ORDER BY와 함께 사용
TIP) 테이블 레이아웃을 파악하고 싶을 때
SELECT *
FROM 테이블명
LIMIT 1집계 함수
여러 조건을 입력하여 하나의 결과를 반환
하나의 열에 대해서만 집계 함수 호출 가능(여러 열에 대해 사용하려면 GROUP BY필요)
집계 함수는 SELECT문이나 HAVING문에서만 호출될 수 있음
--기본 집계 함수
AVG() --평균값을 반환(부동 소수점 값을 반환하므로 ROUND()를 같이 사용할 때가 많음)
COUNT() --반환되는 값이나 행의 갯수를 반환. 컬럼명을 넣든 *을 넣든 같은 값 반환
MAX() --최대값 반환
MIN() --최소값 반환
SUM() --특정 열의 모든 값을 더한 값을 반환GROUP BY
SELECT 컬럼1,집계함수(그룹화할컬럼)
FROM 테이블명
GROUP BY 그룹화할컬럼여러 열에 대해서 집계 함수 호출 가능
그룹화할 컬럼을 선택한 후 컬럼의 값에 따라 테이블의 데이터를 분류하여 집계(그룹화할 컬럼의 값별로 집계값을 구할 수 있음)
GROUP BY는 FROM문 바로 뒤 혹은 WHERE문 바로 뒤에 와야 함
실제 SELECT문에서는 컬럼에 집계 함수가 적용되거나 혹은 열 자체가 GROUP BY의 호출 대상이므로, GROUP BY문을 사용하고 특정 컬럼만을 선택하는 경우에는 GROUP BY문에 반드시 그 컬럼을 포함시켜야 함. (예외: 그 컬럼에 집계 함수를 호출하는 경우)
WHERE문에는 집계 함수를 입력하면 안 됨 -> 결과를 필터링하고 싶은 경우 HAVING문 사용해야 함
HAVING
SELECT 컬럼1,집계함수(그룹화할컬럼)
FROM 테이블명
GROUP BY 그룹화할컬럼
HAVING --조건--집계가 이미 이루어진 이후에 자료(집계 결과)를 필터링하기 때문에 GROUP BY 뒤에 위치
WHERE처럼 쓸 수 있지만 GROUP BY가 있을 때만 사용 가능
집계함수의 결과값을 필터링하고 싶을 때 사용
JOINS
여러 테이블의 데이터를 하나로 결합
join을 다중으로 연달아 여러 번 쓸수도 있음
벤 다이어그램으로 설명하는 SQL JOINS
SQL JOINS의 Wikipedia 페이지
AS
SELECT 컬럼 AS 별칭
FROM 테이블명컬럼이나 서브쿼리를 통해 나온 결과에 별칭 부여
쿼리의 제일 마지막에 실행되므로 SELECT, WITH 등에서 사용 가능(WHERE,HAVING 등의 구문에서는 사용 불가)
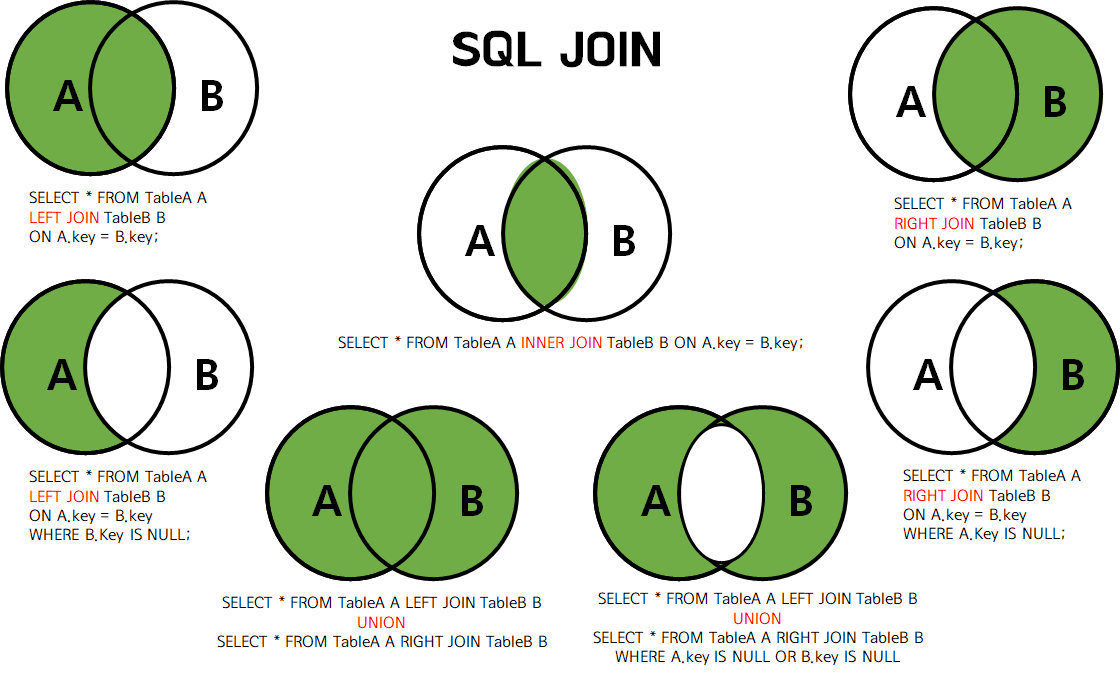
INNER JOIN
SELECT *
FROM 테이블1
INNER JOIN 테이블2 --INNER 없이 JOIN만 써도 INNER JOIN으로 처리
ON 테이블1.키가될컬럼 = 테이블2.키가될컬럼두 테이블을 모두 충족하는 데이터를 반환
벤다이어그램이 대칭이므로 순서를 바꿔도 결과가 같음
컬럼명이 중복될 경우 어느 테이블의 컬럼인지 명시해야 함(컬럼->테이블.컬럼)
--예시
--아래의 두 쿼리는 로직, 결과가 같음
select a.prdt_cd
, sum(stock_qty) as stock_total
from prcs.db_prdt a, prcs.db_scs_w b
where end_dt = '2022-05-22'
and a.prdt_cd = b.prdt_cd
group by a.prdt_cd
order by 1,2
;
select a.prdt_cd
, sum(stock_qty) as stock_total
from prcs.db_prdt a
inner join prcs.db_scs_w b
on a.prdt_cd = b.prdt_cd
where end_dt = '2022-05-22'
group by a.prdt_cd
order by 1,2
;OUTER JOIN
두 테이블 중 하나에만 표시되는 값을 반환
FULL OUTER JOIN(합집합)
SELECT *
FROM 테이블1
FULL OUTER JOIN 테이블2
ON 테이블1.키가될컬럼 = 테이블2.키가될컬럼합집합
한 테이블에만 값이 존재하는 행에는(값이 없는 컬럼) null이 자동으로 들어감
벤다이어그램이 대칭이므로 순서를 바꿔도 결과가 같음
FULL OUTER JOIN(합집합-교집합)
SELECT *
FROM 테이블1
FULL OUTER JOIN 테이블2
ON 테이블1.키가될컬럼 = 테이블2.키가될컬럼
WHERE 테이블1.키가될컬럼 IS null OR 테이블2.키가될컬럼 IS null -- 합집합 - 교집합합집합-교집합(여집합)
벤다이어그램이 대칭이므로 순서를 바꿔도 결과가 같음
한 테이블에만 값이 존재하는 행에는(값이 없는 컬럼) null이 자동으로 들어감
WHERE 테이블1.키가될컬럼 IS null OR 테이블2.키가될컬럼 IS null를 통해 차집합(둘 중 한 테이블에만 있는 값, 합집합-교집합)을 구할 수 있음(FULL OUTER JOIN - INNER JOIN)
LEFT OUTER JOIN(합집합-교집합)
SELECT *
FROM 테이블1
LEFT OUTER JOIN 테이블2 -- LEFT JOIN이라고만 써도 LEFT OUTER JOIN으로 처리
ON 테이블1.키가될컬럼 = 테이블2.키가될컬럼
WHERE 테이블2.키가될컬럼 IS null -- 왼쪽 여집합만왼쪽 테이블만 있는 여집합 + 교집합
오른쪽 테이블에 일치하는 내용이 없으면 그 값은 null로 표시
대칭이 아님
예시)
--아래의 두 쿼리는 로직, 결과가 같음
select *
from prcs.db_prdt a
full outer join prcs.db_scs_w b
on a.prdt_cd = b.prdt_cd
where end_dt = '2022-05-22'
and a.prdt_cd is not null
order by 1,2
;
select *
from prcs.db_prdt a
left outer join prcs.db_scs_w b
on a.prdt_cd = b.prdt_cd
where end_dt = '2022-05-22'
order by 1,2
;RIGHT OUTER JOIN(합집합-교집합)
SELECT *
FROM 테이블1
RIGHT OUTER JOIN 테이블2 -- RIGHT JOIN이라고만 써도 RIGHT OUTER JOIN으로 처리
ON 테이블1.키가될컬럼 = 테이블2.키가될컬럼
WHERE 테이블1.키가될컬럼 IS null -- 오른쪽 여집합만오른쪽 테이블만 있는 여집합 + 교집합
왼쪽 테이블에 일치하는 내용이 없으면 그 값은 null로 표시
대칭이 아님
LEFT JOIN과 완전히 동일한 로직
UNION, UNION ALL
SELECT 컬럼1, 컬럼2, 컬럼3 FROM 테이블1
UNION -- 중복 제거
SELECT 컬럼1, 컬럼2, 컬럼3 FROM 테이블2
SELECT 컬럼1, 컬럼2, 컬럼3 FROM 테이블1
UNION ALL -- 중복 허용
SELECT 컬럼1, 컬럼2, 컬럼3 FROM 테이블2두 집계 결과를 직접 붙이는 함수
붙이는 두 집계 결과의 컬럼이 일치해야 함
고급 SQL 함수(명령어)
시간, 날짜 관련 함수
Timestamp
시간, 날짜 관련 자료형(데이터타입)
- TIME(시간)
시,분,초 - DATE(날짜)
년,월,일,요일 - TIMESTAMP(타임스탬프 = 시간 자료형 + 날짜 자료형)
날짜 + 시간 - TIMESTAMPTZ(타임스탬프TZ)
날짜 + 시간 + 표준시간대
시간, 날짜 관련 함수
SHOW ALL -- 쿼리 실행 시간 값을 포함한, 여러 정보를 반환
SHOW TIMEZONE -- 표준시간대 반환
SELECT NOW() -- 쿼리를 실행하는 시점의 타임스탬프 정보(숫자로 표현) 반환
SELECT TIMEOFDAY() -- 쿼리를 실행하는 시점의 타임스탬프 정보(문자로 표현) 반환
SELECT CURRENT_TIME -- 쿼리를 실행하는 시점의 표준시간대 시간 반환
SELECT CURRENT_DATE -- 쿼리를 실행하는 시점의 날짜 반환EXTRACT
시간, 날짜 관련 자료형 데이터에서 데이터를 추출
EXTRACT(추출하고자하는요소 FROM 추출대상인시간날짜컬럼)
AGE(타임스탬프컬럼) -- 해당 타임스탬프 내~쿼리를 실행하는 시점 사이의 기간 반환
TO_CHAR(날짜컬럼, '형식') -- 날짜를 원하는 형식의 문자열로 변환추출 가능한 요소
YEAR
MONTH
DAY
WEEK
QUARTER
DOW -- 날짜(일요일=0)수학 함수
문자열 함수
서브 쿼리
-- 조건을 만족하는 값을 반환(서브쿼리를 조건절로 활용)
SELECT 컬럼1
FROM 테이블1
WHERE EXISTS ( SELECT 컬럼1 FROM 테이블1 WHERE --조건-- )
-- 예시
SELECT 컬럼1, 컬럼2
FROM 테이블명
WHERE 컬럼1 > ( SELECT 컬럼3 FROM 테이블명2 ) -- IN, =, != 등 사용 가능다른 쿼리의 결과에 대한 쿼리를 실행하거나 다른 쿼리의 결과를 사용할 때 사용
서브 쿼리가 먼저 작동한 후 서브 쿼리의 바깥 쿼리가 작동
WHERE조건에 서브쿼리를 넣을 수도 있음
EXISTS 서브쿼리 서브쿼리의 값이 있으면 TRUE, 없으면 FALSE 반환
SELF JOIN
-- 테이블1 내의 서로 다른 컬럼인 컬럼1과 컬럼2가 같은 경우의 컬럼1,컬럼2 값을 반환
SELECT 테이블2.컬럼1 , 테이블3.컬럼2
FROM 테이블1 AS 테이블2
JOIN 테이블1 AS 테이블3
ON 테이블2.컬럼1 = 테이블3.컬럼2테이블이 그 테이블 자신에 JOIN되는 쿼리
같은 테이블 내의 컬럼들의 값을 비교할 때 주로 사용
동일한 표를 복사해서 합친 것처럼 보일 수 있으나, 실제로 복사된 것은 아님
같은 표를 사용하여 셀프 조인을 할 때에는 테이블명 명명에 주의해야 함(alias)
예시)
-- 예시 1
select full_nm.shop_nm, short_nm.shop_nm_short
from prcs.db_shop as full_nm
join prcs.db_shop as short_nm
on full_nm.shop_nm = short_nm.shop_nm_short
;
-- 예시 2
select pd1.prdt_nm , pd2.prdt_nm, pd1.tag_price
from prcs.db_prdt pd1
join prcs.db_prdt pd2
on pd1.tag_price = pd2.tag_price
where pd1.prdt_nm != pd2.prdt_nm
;데이터베이스 및 테이블 만들기
자료형(data types)
- BOOLEAN
TRUE or FALSE - CHARACTER
CHAR, VARCHAR, TEXT - NUMERIC
INTEGER, FLOATING-POINT NUMBER - TEMPORAL
- TIME(시간)
시,분,초
- DATE(날짜)
년,월,일,요일
- TIMESTAMP(타임스탬프 = 시간 자료형 + 날짜 자료형)
날짜 + 시간
- TIMESTAMPTZ(타임스탬프TZ)
날짜 + 시간 + 표준시간대 - UUID
고유 식별자(Universally Unique Identifiers) - ARRAY
- JSON
- Hstore
key-value 쌍 - URL
- geometric data
- SERIAL MYSQL의 ID
DB를 구축할 때 컬럼에 어떤 값이 들어갈지를 고려하여 컬럼의 데이터타입 지정
(온라인에서 관례, 선례를 참고하여 정하는 것을 권장)
PRIMARY KEY, FOREIGN KEY
PRIMARY KEY(기본키, PK)
테이블의 행들의 식별자로 사용하기 위한 UNIQUE한 컬럼(들)
테이블들을 JOIN할 때 KEY로 사용
FOREIGN KEY(외래키, FK)
다른 테이블에 대한 레퍼런스를 제공하는 키
외래키를 포함하는 테이블을 REFERENCING TABLE 혹은 CHILD TABLE이라고 함
해당 테이블이 다른 테이블들과 많은 관련을 맺고 있을수록 외래키를 많이 포함하고 있음
제약 조건(Constraints)
데이터베이스에 유효하지 않은 데이터가 적재되지 않도록 하여, 데이터의 정확성과 신뢰성 보장
column constraints
특정 조건을 만족하는 컬럼 하나에 적재되는 데이터에 대한 제약조건
예시
NOT NULL해당 컬럼에 NULL값이 들어가면 안 됨UNIQUE해당 컬럼에 들어가는 값들은 모두 UNIQUE해야 함(중복값이 있으면 안 됨)PRIMARY KEY해당 컬럼이 PK여야 함(해당 테이블을 식별, 규정할 수 있는 값이어야 함)FOREIGN KEY해당 컬럼이 FK여야 함(다른 테이블의 데이터에 기반한 값이어야 함)CHECK해당 컬럼의 모든 값이 특정 조건을 만족해야 함EXCLUSION특정 오퍼레이터를 사용한 특정 컬럼이나 식을 사용하여 어떤 두 컬럼이 비교될 때, 비교 값 중 적어도 하나는FALSE여야 함
table constraints
개별 컬럼이 아닌 전체 테이블에 적용되는 제약조건
예시
CHECK(조건)테이블에 데이터를 적재하거나 업데이트할때 특정 조건을 만족해야 함REFERNCES컬럼에 들어가는 값들이 다른 테이블의 컬럼에 존재해야 함UNIQUE(컬럼1,컬럼2,...)컬럼(들)에 들어가는 값들이 모두 UNIQUE해야 함PRIMARY KEY(컬럼1,컬럼2...)컬럼(들)에 들어가는 값들이 모두 PK여야 함
CREATE
CREATE TABLE 스키마.테이블명(
컬럼명1 컬럼1의데이터타입 컬럼제약조건,
컬럼명2 컬럼2의데이터타입 컬럼제약조건,
테이블제약조건 테이블제약조건
) INHERITS 기존에이미있던테이블명 -- 만들고자 하는 테이블이 기존에 있던 다른 테이블과 연관관계가 있는 경우컬럼을 PK로 만들고 싶은 경우 데이터타입을 SERIAL로 설정
INSERT
-- 테이블에 값 직접 적재
INSERT INTO 테이블(컬럼1, 컬럼2...)
VALUES
(값1, 값2, ...)
(값3, 값4, ...)
-- 다른 테이블의 값 옮겨와서 적재
INSERT INTO 테이블1(컬럼1, 컬럼2...)
SELECT 컬럼1, 컬럼2...
FROM 테이블2
WHERE --조건--다른 테이블에서 값을 옮겨와서 적재할 때, 두 테이블의 데이터타입, 제약조건 등이 일치해야 함
이미 있는 테이블명은 다시 쓸 수 없음
테이블의 데이터를 테이블 자신에게 다시 insert할 수도 있음
UPDATE
-- 테이블에 값 직접 적재
UPDATE 테이블
SET 컬럼1 = 값1,
컬럼2 = 값2, ...
WHERE --조건--
-- 다른 테이블의 값 옮겨와서 적재
UPDATE 테이블1
SET 컬럼1 = 테이블2.컬럼2
FROM 테이블2
WHERE 테이블1.키컬럼 = 테이블2.키컬럼테이블 내에 이미 있던 컬럼을 기준으로 새로운 컬럼을 생성할 수도 있음
RETURNING 컬럼1, 컬럼2를 쿼리 마지막에 적으면 값이 변화한 컬럼을 확인할 수 있음
DELETE
-- 조건에 해당하는 행을 삭제
DELETE FROM 테이블명
WHERE --조건--
-- 테이블2와 연관지어서 삭제
DELETE FROM 테이블1
USING 테이블2
WHERE 테이블1.키컬럼 = 테이블2.키컬럼테이블에서 열을 삭제
RETURNING을 사용하여 삭제된 행 확인 가능
ALTER
ALTER TABLE 테이블명 --수정내용--
ALTER TABLE 테이블명
DROP COLUMN 컬럼명
ALTER TABLE 테이블명
ALTER COLUMN 컬럼명
SET DEFAULT 컬럼의디폴트값이미 존재하는 테이블의 구조 수정
컬럼 삭제, 컬럼 추가, 컬럼에 컬럼제약조건(EX. CHECK) 삭제/추가
DROP
ALTER TABLE 테이블명
DROP COLUMN 컬럼1,
DROP COLUMN 컬럼2
ALTER TABLE 테이블명
DROP COLUMN 컬럼명 CASCADE테이블의 컬럼 삭제
컬럼의 값과 제약 조건등은 모두 사라지지만, 그 컬럼과 연관된 모든 관계가 사라지지는 않음(관계까지 다 삭제하고 싶다면 CASCADE를 사용해야 함)
예시)
ALTER TABLE 테이블명
DROP COLUMN 컬럼명 IF EXISTS 컬럼명 -- 없는 컬럼을 삭제하려 하면 에러가 나므로, 컬럼이 있는지 확인한 후 삭제CHECK Constraints
CREATE TABLE 테이블(
컬럼2 데이터타입 CHECK(--제약조건--)
)특정 조건에 맞춤화한 제약 조건 사용 가능
테이블을 만들면서, 컬럼 뒤에 조건을 걸어서 해당 컬럼의 컬럼제약조건을 만들 수 있음
-> 컬럼제약조건에 어긋난 값을 컬럼에 넣으려고 하면 에러 발생
조건식과 프로시저
CASE
SQL의 조건문
특정 조건이 충족되면 쿼리 실행
아래 두 가지를 상황에 맞게 사용
일반 CASE 구문
CASE
WHEN 조건1 THEN 결과1
WHEN 조건2 THEN 결과2
ELSE 결과3 -- 생략가능
END AS 별칭조건1을 충족하면 결과1을, 조건2를 충족하면 결과2를, 둘 다 아니면 결과3을 반환
CASE expression 구문
CASE 컬럼명
WHEN 값1 THEN 결과1
WHEN 값2 THEN 결과2
ELSE 결과3 -- 생략가능
END AS 별칭컬럼의 값이 값1이면 결과1을, 컬럼의 값이 값2이면 결과2를, 둘 다 아니면 결과 3을 반환
예시)
-- 아래 두 쿼리는 동일
select nm
, case
when nm = '모모' then '제일 사랑해!'
else '사랑해!'
end as feeling
from practice.cat
;
select nm
, case nm
when '모모' then '제일 사랑해!'
else '사랑해!'
end as feeling
from practice.cat
;
select distinct case
when cat_nm = '모자' then '모자다!'
when cat_nm = '맨투맨' then '맨투맨이다!'
else '모르겠다!'
end as cat_comment
, count(cat_comment) over(partition by cat_comment) as cat_cnt
from prcs.db_prdt
;
select sum(
case
when cat_nm = '모자' then 1
end
) as caps_cnt
from prcs.db_prdt
;COALESCE
COALESCE(인자1,인자2,인자3...인자n)
COALESCE(컬럼,0) --컬럼값이 NULL이면 컬럼값이 NULL이 아닌 0인것으로 처리인자(갯수 상관없음)들을 받아서, NULL이 아닌 첫 번째 인자를 반환
만약 모든 인자가 NULL인 경우, NULL을 반환
NULL값이 있는 테이블에 대한 쿼리를 작성할 때 주로 사용(EX. NULL이 있는 테이블에 대해 NULL을 처리할 수 없는 쿼리를 작성하는 경우)
CAST
SELECT CAST(값 AS 변환할데이터타입)
SELECT CAST(컬럼 AS 변환할데이터타입)
FROM 테이블
-- postgres의 경우 축약해서 쓸 수 있음
SELECT 값::변환할데이터타입데이터타입을 변환
(모든 데이터타입이 서로 변환가능한 것은 아님)
NULLIF
NULLIF(인자1, 인자2)두 인자의 값이 같으면 NULL, 같지 않으면 첫 번째 값 반환
일종의 CHECK구문이라고 볼 수도 있음
VIEWS
CREATE VIEW 뷰명
--쿼리--반복되는 쿼리를 매번 스크립트로 실행하지 않고, 저장하여, 일종의 가상 테이블로 만드는 것
테이블과 마찬가지로 생성, 삭제, 이름 수정 등을 할 수 있음
기타
ROUND(숫자, 자릿수) --자릿수까지 반올림된 숫자 반환
DATE(타임스탬프) --시간정보를 날짜정보로 변환--집계함수 예시(실제 쿼리)
select prdt_cd, count(*)
from prcs.db_scs_w
where brd_cd = 'M'
group by prdt_cd
having count(*) >= 40
order by count(*) asc
;