Bits and Character
Codes for Characters
Encoding: 대상 information을 code로 변환하는 과정 또는 규칙Decoding: code로부터 원래의 information으로 얻는 과정 또는 규칙
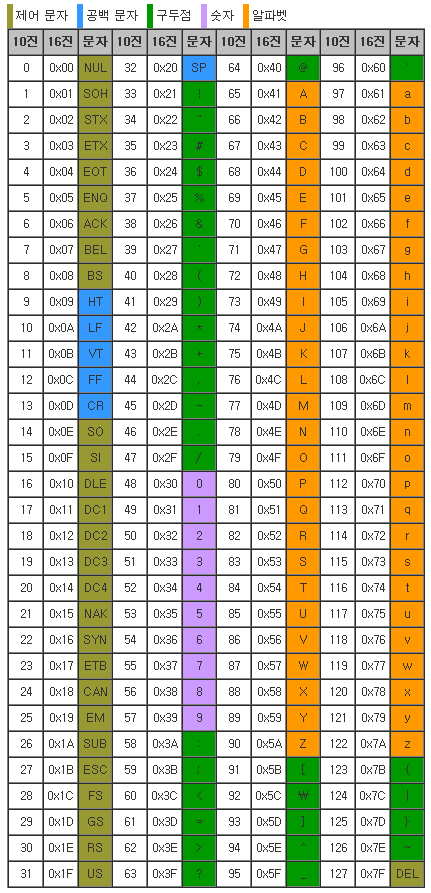
ASCII(The American Standard Code for Information Interchange)
- code 중 가장 오래되었지만 영문자를 처리하는데 여전히 사용됨
- 7bit 만으로 다양한 숫자기호와 영문자, 특수문자 및 Control character들을 표현
- 컴퓨터가 발전함에 따라 ASCII를 사용하는 데이터 type의 크기가 1byte가 되었음.
- 34개의 Control character, 52개의 Alphabet, 10개의 Digit, 32개의 Special character로 구성
ANSI(American National Standard Institute)
ASCII의 7bit base를 8bit로 확장한 code- code page를 이용하여 한번에 해당 code page에 해당하는 나라의 문자를 표현하는 방식
ANSI를 활용한 대표적 한글 code는CP949- 자국어 만을 지원하는 경우 문제가 없지만, 영어 외의 다른나라 글자들을 동시에 표현해야하는 경우 어렵다는 단점.
EUC-KR
- Unix 계열에서 한글 지원을 위해 나타난 encoding 방식이며 2byte를 이용한 완성형 방식.
ANSI를 한글 지원을 위해 확장한 형태로 모든 한글을 표현하진 못함.
Unicode
- 전세계 문자와 기호를 하나의 table에 정리한 code
- 기존 code들과 달리 할당된 code와 다른 byte로 컴퓨터에서 저장
Code and Encoding
Unicode는 엄밀히 말해, code이지 encoding이 아님.Unicode기반의 encoding은UTF-8(가변길이) ,UTF-16(가변길이) ,UTF-32(고정길이) 등이 있기 때문에 사용한 encoding 방식에 따라 저장되는 byte가 달라지게 됨.ANSI,ASCII는 code에 해당하는 바이트가 그대로 저장되기 때문에 code이자 encoding으로 볼 수 있음.
Encodings for Unicode
- 기존에는
UTF-16혹은ANSI계열의 encoding이 사용됨. UTF-8이 등장하며 단일 encoding으로 다국어가 처리가 가능해짐.- 현재는 거의 대부분의 unicode 지원 SW들이
UTF-8을 기본으로 사용하며 실질적인 표준이 됨. UTF-32는 고정형으로 어찌보면 가장 처리가 쉬운 방식이지만 문자 하나에 4bytes를 쓴다는 단점이 있음.UTF-8(Universal Coded Character Set+Transformation Format-8bit
한 문자를 표현하는데 1~4bytes를 사용하며 하위 1byte는ASCII와 호환.
한글의 경우, 한 글자를 나타내는데 대부분 3bytes가 사용되어 효율성이 떨어지는 편.- 1byte만 사용하는 경우
MSB가0으로 시작 - 2bytes 사용하는 경우 상위 byte는
110으로 시작, 하위 byte는10으로 시작 - 3bytes 사용하는 경우 상위 byte는
1110으로, 나머지 하위 byte들은10으로 시작 - 4bytes 사용하는 경우 상위 byte는
11110으로, 나머지 하위 byte들은10으로 시작
- 1byte만 사용하는 경우
Encoding
Quoted-Printable Encoding
- QP encoding은 과거 7bit 만을 지원하는 통신 경로로 데이터 통신을 하던 시절에 개발된 encoding 방식으로 현재 email 첨부파일 전송 등에 사용됨.
- Computer의 internal representation을 1byte 씩 나눔
- 각각의 1byte를 nibble로 쪼개고 각 nibble을 16진수로 표현(2개의 symbol이 나옴)
- 2개의 symbol 앞에
=을 붙임 - 이를 모든 byte에 적용
단,
ASCII의 printable character들은 사실상 7bit로 그대로 전송- 공백문자에 해당하는
TAB,SPACE와 QP encoding에서 사용하는=은 예외로 각 ASCII 코드값에=을 붙여 전송TAB:=09,SPACE:=20,=:=3D - 1 line이 76 character로 구성
- 각 line은 soft linebreak인
=로 끝남- 1byte가 3개의 글자로 표시되므로 전부 non-ascii인 한글 글자의 UTF-8 encoding된 byte의 경우, 25문자가 한 line에 표시됨.
- 이며 soft linebreak를 더해 76글자
Base64 Encoding
- QP encoding보다 효율이 좋은 encoding 방식으로 역시 email의 첨부파일을 encoding 하는데 사용됨.
- 3bytes 씩 묶어서 4개의 character로 encoding하는 방식
- 3bytes를 4등분하여 6bit 씩 나누고 이들 6bit를 64진수로 표현
- 64진수를 위해 Alphabet에서 26개의 upper-case와 26개의 lower-case, digit 10개,
+,-문자들을 사용 - raw data가 3byte의 배수가 아니라면, 끝에
=문자로padding을 하여 3의 배수로 맞춰줌.
URL Encoding
- URL에서
escape sequence(특별한 의미를 가진 문자)를 그냥 문자 그대로 사용하기 위해서 해당 문자의 ASCII 값을 16진수로 표현하고 이를%뒤에 붙여서 기재함. - 한글 같은 경우 한글자가 3bytes이므로 각 byte에 해당하는 16진수를 각각
%를 붙여 변환됨. - 한글을 UTF-8로 변환하고 해당 byte를 1byte씩 자른 후 이를
%와 16진수 숫자 2개로 바꾸어 처리함.
Web Browser
- 가장 널리 사용되는 복잡한 SW 중 하나이면서 다양한 instruction set을 지원하며 이를 조합하여 새로운 기능을 추가할 수 있는 일종의 virtual machine
- Software로만 구현된 Abstract computer라고도 할 수 있음.
- 일반적으로는 인터넷 망에서 정보를 검색하는데 사용되는 응용 프로그램
- 인터넷에서 문자, 영상, 음향 등 다양한 형태로 저정되어 있는 정보를 찾아 접근, 열람할 수 있도록 해주는 SW
Interpreter or VM(Virtual Machine)으로서의 Web browser
- Web browser는 일종의 interpreter라고 생각할 수 있음.
- 다양한 interpreter language의 source code를 원격지 등에서 읽어들여서 이들을 해석하고 대응하는 instruction들의 집합을 수행하는 interpreter라고 볼 수 있음.
Interpreter language
- line단위로 컴파일 없이 시행되는 언어
- 컴파일 없이 라인 단위 실행이 가능하기 때문에 개발단계에서 적은 양의 수정에 대한 결과 쉽게 확인 가능
Python,Java Scriptetc...
Virtual Machine
- HW의 발전으로 가능해진 것으로 마치 여러 application에서 시분할 기술을 통해 단일 OS에서 실행하는 것처럼, 여러 OS를 단일 물리적 시스템에서 시분할로 실행하는 방법
- OS는 HW에서 수행되는 instruction set이 있고 HW와 상호작용 하기 때문에 "실제 물리적 시스템의 HW에서 해당 작업을 담당하는 “Host OS" 와 "VM 내의 OS" 사이에서 VM 내 OS 요청을 Host OS가 수행할 수 있는 요청으로 변환해주는 중간자가 필요함
- 이는 일종의
interpreter라고 볼 수 있음.- 클라우드 환경을 이루는 데이터 센터에서 가장 유용하게 사용됨.
Engine(or Layout Engine, Randering Engine)
- HTML과 CSS, XML 등으로 작성된 웹페이지를 읽어들여서 사람이 읽을 수 있는 문서로 표시해주는 웹 브라우저의 핵심기능을 담당하는 component를 지칭.
- Markup language 등에 대한 일종의 interpreter라고 볼 수 있음.
- 최근의 web browser에는 프로그램 같이 사용자의 입력에 대한 반응 등을 하기 위해 자바스크립트 엔진 등이 추가되어 있음.
Web browser의 중요성
- 다양한 정보와 문서의 집합체인 internet에서 data를 열람하기 위해 web browser는 필수적인 SW
Reference:
1) https://shaeod.tistory.com/228
2) https://dsaint31.me/mkdocs_site/CE

노정훈