Ref. https: Jaron Collis's Blog
단어 임베딩의 핵심은 텍스트를 숫자로 변환하는 것이다.
이러한 변환은 많은 ML 알고리즘에서, 연속적인 값의 vector를 입력으로써 요구하기 때문에 필요하다. 텍스트를 바로 입력으로 사용할 순 없다.
따라서 Word Embedding과 같은 자연어 모델링 기술은 어휘에서 단어나 구문을 대응되는 실수 벡터로 매핑하는 데 사용된다. 또한 이러한 vector는 두 가지 중요하고 유리한 특징을 가지고 있다.
- Dimensionality Reduction(차원 감소)
- Contextual Similarity(문맥적 유사성)
Bag of Words 방식은 매우 크고 sparse한 one-hot 인코딩 벡터를 생성하는데, 여기서 벡터의 차원은 지원되는 어휘의 총 개수와 같다. Word Embedding은 이보다 훨씬 낮은 차원의 벡터 표현을 만들기 위해 노력하는데, 이러한 것들을 Word Vectors라고 한다.
의미 파싱(semantic parsing)에 사용되는 Word Vector는, 텍스트에서 의미를 추출하여 자연어를 이해할 수 있게 한다. 텍스트의 의미를 예측하려면 단어의 문맥적 유사성을 인식해야 한다. 예를 들어, 과일이라는 단어(사과 또는 오렌지)는 일반적으로 문장에서 재배, 수확, 섭취, 주스 등의 단어와 함께 나타나지만, 비행기와 같은 단어는 그렇지 않을 것이다.
Word Embedding이 만든 벡터는 이러한 유사성을 보존하여, 텍스트에서 자주 인접하게 나타나는 단어들은 벡터 공간에서도 가깝게 배치된다.
Word2Vec
이제 우리는 Word2Vec이 무엇인지 알았으니, 어떻게 작동하는지 알아보자. dimensionality reduction은 일반적으로 비지도 학습으로 이루어진다. 그리고 Word Embedding 알고리즘 중 가장 유명한 word2vec도 이 접근 방식을 사용한다.
word2vec을 구현하는 방법은 두 가지가 있는데, CBOW(Continuous Bag-Of-Words)와 Skip-gram이다.
CBOW는 어떤 대상 단어 주변에 window를 설정하고, window 내 단어들을 문맥으로 고려한다. 그리고 window의 주변 단어들을 network에 입력으로 제공하면, 대상 단어를 예측하도록 학습한다.
Skip-gram은 그 반대로, 대상 단어를 입력하면 주변에 있는 단어들을 예측하려고 한다. 즉, 단어 주변의 문맥을 예측한다.
입력 단어들은 one-hot 인코딩된 벡터로 변환된다. 이 벡터들은 linear units의 hidden layer를 거쳐 softmax로 들어가 prediction이 된다. hidden layer의 weight matrix을 학습시켜 단어에 효율적인 표현을 찾는 것이다. 이 가중치 행렬은 일반적으로 임베딩 행렬(embedding matrix)이라고 하며, 룩업 테이블처럼 query를 할 수 있다.

embedding matrix는 단어 수와 은닉층의 뉴런 수(embed size)에 따라 크기가 결정된다. 예를 들어, 10,000개의 단어와 300개의 hidden units가 있다면 행렬의 크기는 10,000×300이 된다(입력으로 one-hot 인코딩된 벡터를 사용하기 때문에). 계산이 완료된 후에는 rusult matrix를 조회하여 원하는 단어의 벡터를 빠르게 얻을 수 있다.
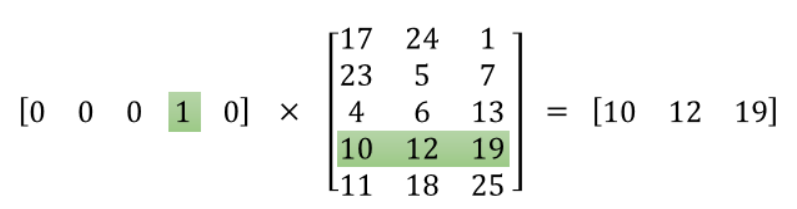
위의 그림처럼 3(hidden layers)x5(단어 개수)로 구성된 matrix를 사전이라고 하면, [0 0 0 1 0]을 query로 사용해 원하는 단어의 vector를 얻을 수 있다. 이렇게 각 단어마다 연관된 vector가 있기 때문에 word2vec이라고 한다.
embed size는 hidden layer의 크기이자 단어 간 유사성을 나타내는 특성의 개수를 의미하며, 일반적으로 사용하는 단어의 총 개수보다 훨씬 작다. 사용되는 embed size는 Trade-off이다. 특징이 많아지면 computational complexity와 run-time 측면에서 좋지 않지만, 더 세련된 표현과 잠재적으로 더 좋은 모델을 제공할 수 있다.
Word Embedding의 흥미로운 특징은 각 단어의 문맥적 유사성을 수치로 나타낸 것이기 때문에 연산이 가능하다는 것이다. 예를 들면, "King" - "Man" + "Woman" = "Queen"과 같은 결과를 얻을 수 있다.
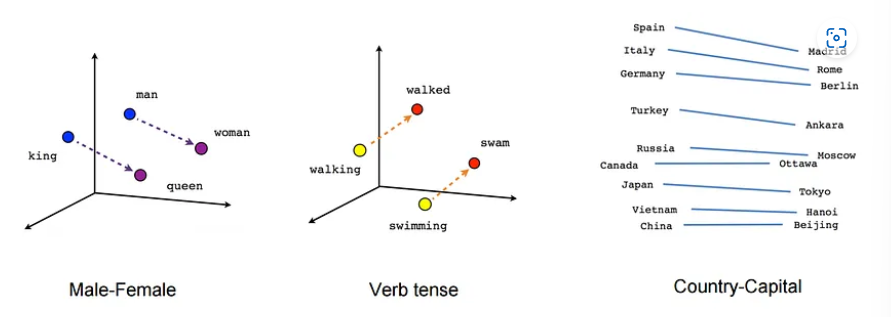 (성별, 시제, 지리 등 문맥에 기반한 유사성을 나타냄)
(성별, 시제, 지리 등 문맥에 기반한 유사성을 나타냄)
Word2vec은 두 개의 layer로 구성된 얇은 신경망이기 때문에 딥러닝의 예시는 아니다. 하지만 이러한 algorithm을 통해 DNN이 이해할 수 있는 형태로 input을 변환할 수 있다는 점이 중요하다.
요약하면, Word Embedding의 목적은 단어를 숫자로 변환하여 딥러닝과 같은 알고리즘이 자연어를 이해하고 처리하는 데 사용할 수 있도록 하는 것이다.
숫자가 언어인 것처럼, 모든 언어가 숫자로 변하면, 모두가 같은 방식으로 이해할 수 있습니다. 글자의 소리나, 입천장을 통해 만드는 pop하는 소리, ooh나 ahh 소리가 사라지고, 소리나 그림을 통해 잘못 전달될 수 있는 것들, 예전부터 있었던 모든 것들이 사라지고 수의 언어로 새롭게 이해하게 됩니다.
- EL Doctorow
단어 임베딩은 단어로 이루어진 언어를 숫자로 표현한 것이다. 이제 만약 인류가 쓴 모든 단어들이 방대한 다차원 가능성 공간으로 변환된다면 어떤 일이 벌어질지 상상해 볼 수 있다.
