1과목 - 데이터 모델링의 이해
1장 데이터 모델링
제1절 데이터 모델의 이해
- 데이터 모델링: 현실 세계를 데이터베이스에서 표현하기 위한 추상화 과정
-
특징
- 추상화: 일정한 형식에 맞춰 표현함
- 단순화: 제한된 표기법이나 언어로 표헌함
- 명확성: 이해가 쉽게 표현함 -
관점
- 데이터 관점(what): 업무와 데이터 및 데이터 사이의 관계
- 프로세스 관점(how): 진행되고 있거나 진행되어야 하는 업무
- 데이터와 프로세스의 상관 관점(interaction): 데이터에 대한 업무 처리 방식의 영향
* 데이터 모델링의 중요성과 유의점
1) 중요성: 파급효과, 간결한 표현, 데이터 품질 유지
2) 유의점:- 중복: 여러 장소에 같은 정보 저장x
- 비유연성: 데이터의 저의를 데이터 사용 프로세스와 분리
- 비일관성: 모델링 할때 데이터 간 상호 연관 관계 명확히 정의
-
데이터 모델링의 3단계
- 개념적 모델링(계획/분석): ERD 도출, 멉무중심, 포괄적인 수준의 모델링
- 논리적 모델링(분석) : 테이블 도출, (key, 속성, 관계)를 표현, 재사용성, 정규화 수행
- 물리적 모델링(설계): DB 구축, 물리적 성격, 개념적보다 구체적
-
데이터 독립성
- 데이터의 구조가 변경되어도 응용 프로그램이 변경될 필요가 없음
- 논리적 독립성 + 물리적 독립성으로 실현됨
- 필요성: 데이터 중복성과 복잡도가 증가 -> 요구사항 대응 저하, 유지보수 비용 증가
* 데이터 베이스 스키마
- 데이터 모델링 대상(틀)
- 데이터베이스 구조, 데이터 타입, 제약조건에 대한 명세
- 데이터 베이스 설계 단계에서 명시되며 자주 변경되지 않음
* 데이터베이스의 3단계 구조
- 외부 스키마 : 응용프로그램 관점에서의 요구사항, 사용자 관점, DB 정의
- 개념 스키마 : 외부 스키마가 필요로 하는 데이터 모두 모아놓은 것, 설계자 관점
- 내부 스키마: 데이터베이스가 물리적으로 저장된 형식, 개발자 관점
-> 데이터 모델링은 통합 관점의 개념 스키마를 만들어 가는 과정
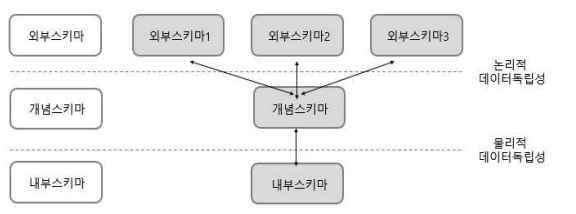
*사상 (mapping)
- 상호 독립적인 개념을 연결시켜주는 다리
- 논리적 사상: 외부화면 및 사용자 인터페이스 스키마 구조는 개념스키마와 연결
- 물리적 사상: 개념스키마 구조와 물리적 저장된 구조와 연결
* 논리적 독립성
- 논리적 사상(개념적-내부적)을 통해 논리적 독립성 보장
- 개념 스키마가 변경되어도 외부 스키마에는 영향 x
- 논리적 구조가 변경되어도 응용프로그램에는 영향이 없음, 통합구조 변경 가능
* 물리적 독립성
- 물리적 사상(개념적-내부적)을 통해 물리적 독립성 보장
- 내부 스키마가 변경되어도 외부/개념 스키마는 영향 x
- 응용프로그램과 개념스키마에 영향 없이 저장장치 구조변경 가능, 물리적 구조
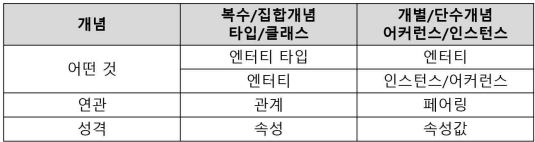
- 데이터 모델링 3요소(개체, 속성, 관계)
- 업무가 관여하는 어떤것: 엔티티 ㅏㅌ입, 엔티티 / 엔티티, 인스턴스, 어커런스
- 어떤 것이 가지는 성격 : 속성/ 속성값
- 어떤 것들 간의 관계 : 관계/ 페어링
* 데이터베이스 인스턴스
- 특정 시점에 데이터베이스에 실제로 저장되어 있는 데이터의 값
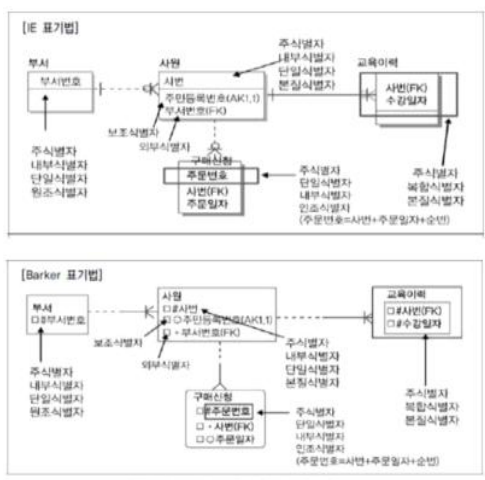
- ERD(Entity Relationship Diagram)
- 데이터 모델 표기법: 엔티티를 사각형 관계를 마름모 속성을 타원형으로 표현
- ERD 표기법을 이용하여 모델링 하는 방법
- 엔티티를 그린 후 적절하게 배치
- 엔티티 간 관계 설정
- 관계명 기술
- 관계차수, 관계의 참여도, 선택성 표시
- 좋은 모델링의 요건
- 완정성 : 업무에서 필요로하는 모든 데이터가 데이터 모델에 정의되어야 한다
- 중복배제: 동일한 사실은 반드시 한번만 기록
- 업무규칙: 업무규칙이 데이터 모델에 표현되어야 한다
- 데이터 재사용 : 회사 전체 관점에서 공통 데이터 도출, 전 영역 사용할 수 있도록 설계
- 통합성: 동일한 데이터는 조직의 전체에서 한번만 정의되고 이를 참조, 활용
제2절 엔티티
- 엔티티
- 업무에 필요한 정보를 저장하고 관리하기 위한 집합적인 것
- 엔티티는 인스턴스의 집합 (인스턴스는 엔티티 안의 데이터)

2. 엔티티의 분류
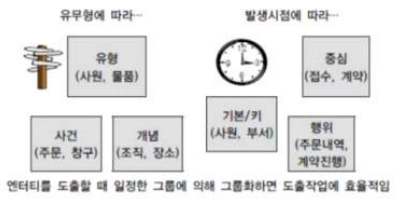
* 유형 무형에 따른 분류
1. 유형 엔티티
- 물리적인 형태가 있고 안정적이며 지속적 활용
- 개념 엔티티
- 물리적인 형태는 존재하지 않으나 관리해야 할 개념적 정보
- 사건 엔티티
- 업무 수행 과정에서 발생, 비교적 발생량 많음(통계자료에 이용)
* 발생시점에 따른 엔티티(기본/중심/행위)
1. 기본 엔티티 : 독립적으로 생성되는 엔티티
2. 중심 엔티티 : 기본 엔티티와 행위 엔티티 중간에 존재하는 엔티티
3. 행위 엔티티 : 2개 이상의 부모 엔티티로부터 발생, 비즈니스 프로세스를 실행하면서 생성되는 엔티티, 지속적 정보가 추가되고 변경되어 데이터양이 가장 많음
3. 엔티티의 특징
- 어무에서 필요로하는 정보 포함
- 유일한 식별자를 가짐(식별자에 의해 식별이 가능하도록, 관계엔티티 예외)
- 2개 이상의 인스턴스를 포함함(인스턴스의 집합)
- 업무 프로세스에 이용됨
- 속성 없이 엔티티의 이름만 존재할 수 없음
- 다른 엔티티와 최소 1개 이상의 관계가 존재(통계성, 코드성, 내부필요 엔티티 예외)
4. 엔티티의 명명 - 엔티티 생성 의미대로, 실제 업무에서 사용하는 용어를 사용 - 약어 사용x, 단수명사 사용 - 이름이 동일한 엔티티가 중복으로 존재x
제3절 속성
- 속성의 정의
- 사물의 특징 또는 본질적인 설징
- 인스턴스에 대해 의미상 더 분리되지 않는 최소의 데이터 단위
* 엔티티, 인스턴스 속성의 관계
- 1개의 엔티티 : 2개 이상의 인스턴스 집합 가짐
- 1개의 인스턴스 : 2개 이상의 속성을 가짐
- 1개의 속성 : 1개의 속성값을 가짐
- 속성의 특징
- 해당 업무에서 필요하고 관리해야 하는 정보
- 모든 속성은 정해진 주식병자에 함수적으로 종속되어야 함
- 하나의 속성은 한 개의 값만을 가짐
- 속성의 명명
- 현업에서 사용하는 이름을 부여
- 약어 사용은 가급적 x
- 수식어/소유격 x, 서술식 속성명 x, 명사형 속성명 o
- 전체 데이터 모델에서 유일성 확보
- (속성의) 도메인
- 각 속성이 가질 수 있는 값의 범위
- 엔티티 내에서 속성에 대한 데이터 타입과 크기, 제약사항을 지정
- 속성의 분류
1) 특성에 따른 분류
- 기본 속성 : 가장 일반적인 속성으로 원래의 업무로부터 유래된 속성
- 설계 속성 : 데이터 무델링을 위해 새로 만든 속성(코드, 일련번호)
- 파생 속성 : 다른 속성들로부터 유도된 속성(통계, 계산된 값)
2) 분해 가능 여부에 따른 분류
- 단일 속성: 하나의 의미
- 복합 속성: 여러 의미, 단일 속성으로 분해 가능
- 단일값 속성: 속성 1개에 한개의 값
- 다중값 속성: 속성 1개에 여러 값, 엔티티로 분해 가능
3) 엔티티 구성방식에 따른 분류
- 기본키 속성(pk) : 엔티티의 인스턴스를 구별할 수 있는 속성
- 외래키 속성(fk) :타 엔티티의 pk를 참조하는 속성
- 일반 속성 : 엔티티에 포함되고 pk나 fk속성이 아닌 속성
제4절 관계
- 관계와 페어링
- 관계 : 엔티티의 인스턴스 사이의 논리적인 연관성으로서 존재의 형태로서나 행위로서 서로에게 연관성이 부여된 상태
- 페어링 : 엔티티 내 인스턴스 간 개별적 관계 -> 이것의 집합을 관계로 표현
- 인스턴스의 집합 -> 엔티티 페어링의 집합 -> 관계
-
관계의 분류
1) ERD : 존재에 의한 관계/ 행위에 의한 관계 (구분 없이 단일화된 표기법 사용)
2) UML : 연관 관계 / 의존 관계 (실선과 점선 표기법으로 구분) -
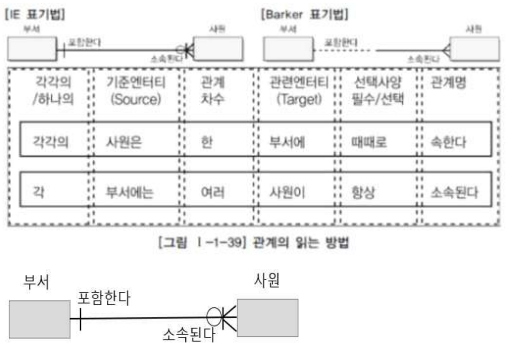
관계의 표기법
1) 관계명 : 엔티티가 관계에 참여하는 형태, 각 관계는 2개의 관계명 및 관점을 가짐
2) 관계차수 : 1:1, 1:N, N:M (관계 엔티티 이용)
3) 관계선택사양 : 필수참여, 선택참여 -
관계 읽기
제5절 식별자
- 식별자의 개념
- 하나의 엔티티에 구성되어 있는 여러 개 속성 중 엔티티를 대표할 수 있는 속성을 의미
- 하나의 엔티티는 반드시 하나의 유일한 식별자가 존재
- 식별자의 분류
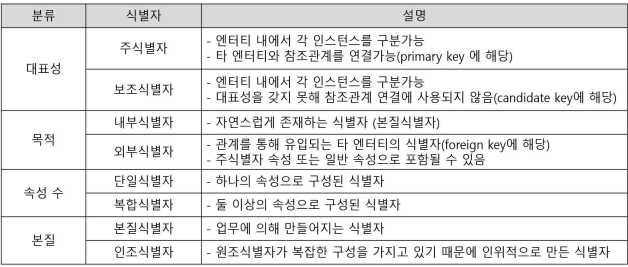
3. 식별자의 특징
- 유일성 : 주식별자에 의해 엔티티 내의 모든 인스턴스들을 유일하게 구분함
- 최소성 : 주식별자를 구성하는 속성의 수는 유일성을 만족하는 치ㅗ소의 수가 되야 함
- 불변성 : 주식별자가 지정되면 그 식별자의 값은 변하지 않아야 함
- 존재성 : 주식별자가 지정되면 반드시 데이터 값이 존재해야 함 (Null X)
4. 주식별자 도출 기준
- 유일성을 갖는 속성 중 해당 업무에서 자주 이용되는 속성을 지정
- 명칭, 내역 등과 같이 이름으로 기술되는 것들은 가능하면 주식별자로 지정 x
- 복합식별자를 구성할 경우 너무 많은 속성이 포함되지 않아야 함
5. 식별자 관계와 비식별자 관계
1) 식별자 관계 (실선)
- 자식이 부모의 기본키를 상속받아 기본키로 사용하는 경우
- 강한 연결관계, 부모에 종속, Null X, 1:1 or 1:N 관계
- 문제정 : 자식의 주식별자 속성이 지속적으로 증가할 수 있음 -> 복잡, 오류 가능성
2) 비실별자 관계 (점선)
- 부모로부터 속성을 받아 일반 속성으로 사용하는 경우
- 문제점 : 부모까지 조인, 불필요 현상 발생 -> SQL 구문 길어져 성능 저하
2장 데이터 모델과 성능
제1절 성능 데이터 모델링의 개요
- 성능 데이터 모델링의 정의
- 데이터베이스 성능을 고려하여 데이터 모델링을 수행하는 것
- 정규화, 반정규화, 테이블 통합 및 분할, 조인 구조, pk/fk 설정 등
- 수행 시점
- 빠를수록 좋음
- 분석/설계 단계에서 성능 모델링 수행 best -> 재업무 비용 최소화
- 성능 데이터 모델링 고려사항
- 정규화를 정확하게 수행 : 주요 관심사별로 테이블을 분산시킴
- 데이터베이스 용량산정 수향 : 각 엔티티에 어느 정도의 트랜잭션이 들어오는지 파악
- 데이터베이스에 발생되는 트랜잭션의 유형 파악 : CRUD 매트릭스 활용
- 용량과 트랜잭션의 유형에 따라 반정규화 수행 : 테이블, 속성, 관계 변경
- 이력모델의 조정, 인덱스를 고려한 PK/fk의 순서 조정, 슈퍼/ 서브타입 조정 등 수행
- 성능관점에서 데이터 모델 검증
제2절 정규화와 성능
- 정규화
- 정의 : 데이터 분해 과정, 이상현상 제거
- 목적 : 삽입/삭제/갱신 이상현상 방지
- 함수적 종속성에 기반한 정규화 수행 필요
- 함수적 종속성
- 데이터들이 어떤 기준값에 의해 종속되는 현상을 지칭, 결정자와 종속자의 관계, 결정자의 값으로 종속자의 값을 알 수 있음
- 결정자 (학번, 주민등록번호)
- 종속자 (이름, 혈액형, 출생지, 주소)
- 종류
- 정규형 : 정규화로 도출된 데이터 모델이 갖춰야 할 특성
1) 1NF : 모든 값이 원자값을 가짐
2) 2NF : 부분함수종속 제거
3) 3NF : 이행함수종속 제거 (식병자가 아닌 속성이 결정자 역할하는 함수 종속 제거)
- 정규화의 효과
- 성능 = 조회, 입력/수정/삭제 2가지로 분류
- 데이터 중복 감소 -> 성능 향상
- 데이터가 관심사별로 묶임 -> 성능 향상
- 조회 질의에서 조인이 많이 발생 -> 성능 저하
-> 입력/수정/삭제의 경우 성능 향상
but 조회의 경우 처리조건에 따라 향성 or 저하
제3절 반정규화와 성능
- 반정규화
- 정의 : 정규화된 엔티티, 속성, 관계에 대해 성능 향상을 목적으로 중복, 통합, 분리를 수행하는 데이터 모델링 기법
- 특징
- 테이블, 칼럼, 관계의 반정규화를 종합적으로 고려
- 과도한 반정규화는 데이터 무결성을 침해
- 반정규화 사전절차
1) 반정규화 대상 조사 : 데이터 처리 범위 및 통계성 등 조사
2) 다른 방법 검토 : 뷰, 클러스터링, 인덱스, 애플리케이션
3) 반정규화 적용 : 정규화 수행 후 반정규화 수행 - 반정규화 기법
1) 테이블 반정규화
- 테이블 병합 : 관계 병합, 슈퍼/서브타입 병합
- 테이블 분할 : 수직, 수평 분할
- 테이블 추가 : 중복 테이블 / 통계 / 이력 테이블 / 부분 테이블 추가
2) 칼럼 반정규화
- 중복칼럼 추가 : 조인 횟수를 감소시키기 위해 다른 테이블의 칼럼 중복 칼럼 저장
- 파생칼럼 추가 : 값의 계산으로 인한 성능 저하 예방, 예상값을 미리 계산해서 중복 칼럼 저장
- 이력테이블 칼럼 추가 : 기능성 칼럼, 대얄 이력 데이터 처리의 성능 향상을 위해 종료 여부, 최근값 여부 들의 칼럼 추가로 저장
- pk의 의미적 분리를 위한 칼럼 추가 : pk가 복합 의미를 가즌 경우 단일 속성을 구성시 발생, 구성 요소 값의 조회 성능 향상을 위해 일반 속성을 추가
- 데이터 복구를 위한 칼럼 추가 : 잘못 처리된 경우 원래 값으로 복구 위해 이전 데이터를 임시로 중복 저장
3) 관계 반정규화
- 중복관계 추가 : 조인으로 정보 조회가 가능 하지만 조인 경로 단축을 위해 중복관계 추가
* 테이블과 칼럼의 반정규화는 데이터 무결성에 영향을 미침
* 관계의 반정규화는 데이터 무결성 보장 가능, 데이터 처릴 성능 향상
제4절 대량 데이터에 따른 성능
- 성능 저하 원인
- 하나의 테이블에 데이터 대량 집중
- 하나의 테이블에 여러개의 칼럼 존재
- 대량의 데이터가 처리되는 테이블
- 대량의 데이터가 하나의 테이블에 존재
- 컬럼이 많아 지는 경우
- 해결방안
- 한 테이블에 많은 칼럼 -> 수직분할
- 대량 데이터 저장 문제 -> 파티셔닝, pk에 의한 테이블을 분할
* 대량 데이터 발생에 따른 테이블 분할
- 수직분할 : 컬럼 단위로 분할
- 수평분할 : 로우 단위로 분할
- 대량 데이터 발생으로 인한 현상
-
블록: 테이블의 데이터 저장 단위
-
블록 I/O 횟수 증가, 이스크 I/O 가능성 상승, 디스크 I/O 성능 저하
-
로우 체이닝 : 행 길이가 길어 데이터 블록 하나에 데이터를 모두 저장하지 않고 두 대 이상의 블로게 걸쳐 하나의 로우를 저장하는 형태
-
로우 마이그레이션 : 수정된 데이터가 해다 블록에 저장하지 못하고 다른 블록의 빈 공간에 저장되는 현상
- 파티셔닝
-
테이블 수평 분할 기법, 논리적으로는 하나의 테이블이지만 물리적으로 여러 데이터 파일에 분산 저장, 데이터 조회 범위를 줄여 성능 향상
- Range Partition: 범위로 분할 - List Partition: 특정한 겂을 기준으로 분할 - Hash Partition : 여러 함수를 적용하여 분할
* 해시함수 : 임의 길이의 데이터를 짧은 길리의 데이터로 매핑하는 함수
- Composite Partition: 여러 파티션 기법을 복합적으로 사용하여 분할
제5절 데이터베이스 구조와 성능
- 수퍼/서브타입 데이터 모델
- 논리적 데이터 모델에서 주로 이용
- 물리적 데이터 모델로 설계 시 문제 발생
- 슈퍼타입 : 공통부분을 슈퍼타입으로 모델링
- 서브타입 : 공통으로부터 상속받아 다른 엔티티와 차이가 있는 속성만 모델링
- 데이터베이스 성능 저하 원인 3가지
1) Union 연산에 의해 성능 저하
- 트랜잭션 : 전체를 일괄처리, 테이블 : 개별로 유지
2) 조인에 의해 성능 저하
- 트랜잭션 : 슈퍼 + 서브타입 공통 처리, 테이블 : 개별로 유지
3) 불필요하게 많은 데이터 집적
- 트랜잭션 : 서브타입만 개별로 처리, 테이블 : 하나로 통합
- 슈퍼/서브타입 데이터 모델 변환 통한 성능 향성
- 변환기준 : 데이터 양, 트랜잭션 유형
- 데이터 소량 : 데이터 처리 유연성 고려하여 가급적 1:1 관계 유지
- 데이터 대량 : 3가지 변환 방법 (개별 테이블, 슈퍼 + 서브타입 테이블, 하나의 테이블)
1) 1:1 타입 : 개별로 처리하는 트랜잭션에 대해 개별 테이블 구성하여 1:1 관계 가짐
2) 슈퍼/서브 타입 : 슈퍼+서브 공통으로 처리하는 트랜잭션에 대해 슈퍼/서브 각각 테이블 구성
3) All in One 타입 : 전체를 하나로 묶어 트랜잭션이 발생, 단일 테이블 구성
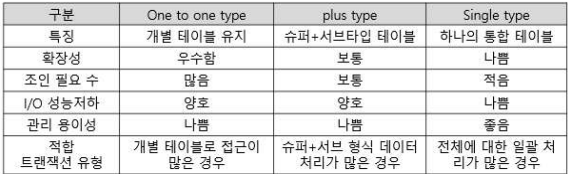
-> 쪼개질수록 확장성 올라감 / Disk, I/O 성능 올라감 / 조인 성능 내려감 / 관리 용이성 내려감
- pk/fk 칼럼 순서 및 성능
- 일반적인 프로젝트에선 pk/fk 칼럼 순서의 중요성을 인지하지 못해 데이터 모델링 되어있는 상태로 DDL을 생성하여 성능이 저하되는 경우가 빈번
1) 인덱스 중요성 : 데이터 조작 시 가장 ㅛ과적으로 처리될 수 있는 접근 경로 제공
* 인덱스의 특징 : 여러개의 속성이 하나의 인덱스로 구성되어 있을 때, 앞쪽에 위치한 속성의 값이 비교자로 있어야 인덱스가 좋은 효율을 나타낼 수 있다. 앞쪽에 위치한 속성값이 가급적 '=' 아니면 최소한의 범위인 'between'이 들어와야 함
2) pk/fk 설계 중요성 : 데이터 접근 시 접근경로 제공, 설계단계 마지막에 칼럼 순서 조정
3) pk 순서의 중요성 : 물리적 모델링 단계에서 스스로 생성된 pk 외에 상속되는 pk 순서도 중요
4) fk 순서의 중요성 : 조인을 할 수 있는 수단이 됨, 조회 조건 고려해서 반드시 인덱스 생성
- pk 순서를 조정하지 않으면 성능 저하 되는 이유
- 조회 조건(where)에 따라 인덱스를 처리하는 범위가 달라짐
- pk의 순서를 인덱스 특징에 맞게 생성하지 않고 자동으로 생성하면, 테이블에 접근하는 트랜잭션이 인덱스 범위를 넓게 하거나 풀 스캔을 유발
- 물리적 테이블에 fk 제약이 걸려있지 않은 경우 인덱스 미생성으로 생긴 성능 저하
- 물리적으로 두 테이블 사이 fk 참조 무결성 관계를 걸어 상석받은 fk에 인덱스 생성
- 인덱스 엑세스 범위 좁히는 가장 좋은 방법
- pk가 여러 개일 때, where절에 사용하는 조건용 칼럼들이 우선순위가 되어야 함
- '=', EQUAL 조건,동등 조건에 있는 칼럼이 제일 앞으로
- between, in 범위 조건에 있는 칼럼이 그 다음 순위
- 나머지 pk는 그 뒤에 아무렇게나
제6절 분산 데이터베이스와 성능
- 분산 데이터베이스의 개념
- 물리적으로 분산된 데이터베이스를 하나의 논리적 시스템으로 사용
- 빠른 네트워크 환경을 이용하여 데이터베이스를 여러 지역에서 노드로 위치시켜 사용성과 성능을 극대화하는 데이터베이스

- 분산 데이터베이스 설계 방식
- 상향식 : 지역 스키마 작성 후 전역 스키마 작성
- 하향식 : 전역 스키마 작성 후 지역사상 스키마 작성
-
분산 데이터베이스의 장단점
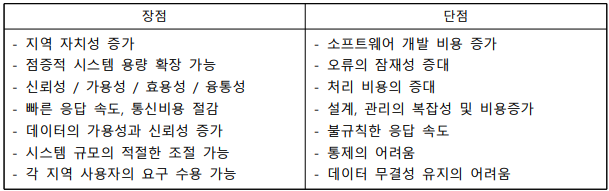
-
분산 DB의 투명성
- 분할 투명성 : 하나의 논리적 관계가 분할되어 각 단편의 사본이 여러 사이트에 저장
- 위치 투명성 : 사용하려는 데이터 저장 장소가 명시되지 않아도 됨
- 지역사상 투명성 : DB 객체 중복 여부를 몰라도 됨
- 장애 투명성 : 구성 요소의 장애에 무관하게 트랜잭션의 원자성이 유지됨
- 병행 투명성 : 다수의 트랜잭션을 동시 수행했을 때 결과의 일관성이 유지됨
- 분산 데이터베이스의 적용기법
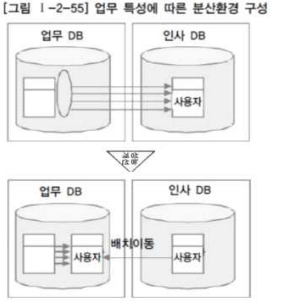
1) 테이블 위치 분산 : 설계된 테이블의 위치를 분산
- 테이블 구조 변경 x
- 테이블이 다른 데이터베이스에 중복으로 생성 x
- 정보를 이용하는 형태가 각 위치별로 차이가 있을 경우 사용
- 테이블 위치를 파악할 수 있는 도식화된 위치별 데이터베이스 문서 필요
2) 테이블 분할 분산 : 테이블을 수평이나 수직으로 분할하여 분산
- 수평 분할 : 특정 칼럼의 값 기준으로 로우 단위 분리, 칼럼 분리 x
- 수직 분할 : 칼럼을 기준으로 칼럼 단위로 분리, 로우 분리 x
3) 테이블 복제 분산
- 동일한 테이블을 다른 지역이나 서버에서 동시 생성, 원격지 조인을 내부조인으로 변경하여 성능 향상, 프로젝트에서 많이 사용되는 데이터베이스 분산 기법
4) 테이블 요약 분산\* 부분복제 - 마스터 데이터베이스에서 테이블의 일부 내용만 다른 지역이나 서버에 위치 - 본사는 통합 테이블 관리, 각 지사에서는 지사에 해당하는 로우만 관리 - 실제로는 지사에서 먼저 데이터 발생 ->본사에서 전체 통합 \* 광역복제 - 통합된 테이블을 본사에 가지고 있으며 각 지사에 본사와 동일한 데이터 분배 - 동일한 테이블을 여러 곳에 복제하여 관리 - 본사에서 데이터의 입력, 수정, 삭제 발생 -> 지사에서 이를 반영-
유사한 내용의 데이터를 서로 다른 관점/수준에서 요약하여 분산 관리
* 분석요약
- 각 지사별 동일한 주제의 정보를 본사에서 통합하여 전체 요약 정보 산출
* 통합요약
- 각 지사별로 존재하는 다른 내용 정보를 본사에 통합, 다시 전체의 요약 산출
-
