DP
다이나믹 프로그래밍은 기본적인 아이디어로 하나의 큰 문제를 여러개의 작은 문제로 나누고, 그 결과를 저장하여 다시 큰 문제를 해결할 때 사용하는 것이다. 큰 문제를 작은 문제로 쪼개서 답을 저장해두고 재활용한다는 점에서 '기억하며 풀기'라고도 부른다.
DP를 사용하는 이유?
일반적인 재귀를 단순히 사용하면 동일한 작은 문제들이 여러번 반복되어 비효율적인 계산을 할 수도 있다.
ex.피보나치 수열
1, 1, 2, 3, 5, 8, 13, 21, 34 , 55, 89, ...
- 재귀함수를 사용하는 경우
return f(n) = f(n-1) + f(n-2)
이 과정에서 f(n-1), f(n-2)에서 각 함수를 1번씩 호출하면 동일한 값을 2번씩 구하게 되고, 만약 100번째 피보나치 수를 구하고 싶다면, 호출해야 하는 함수의 수는 급격히 증가한다.
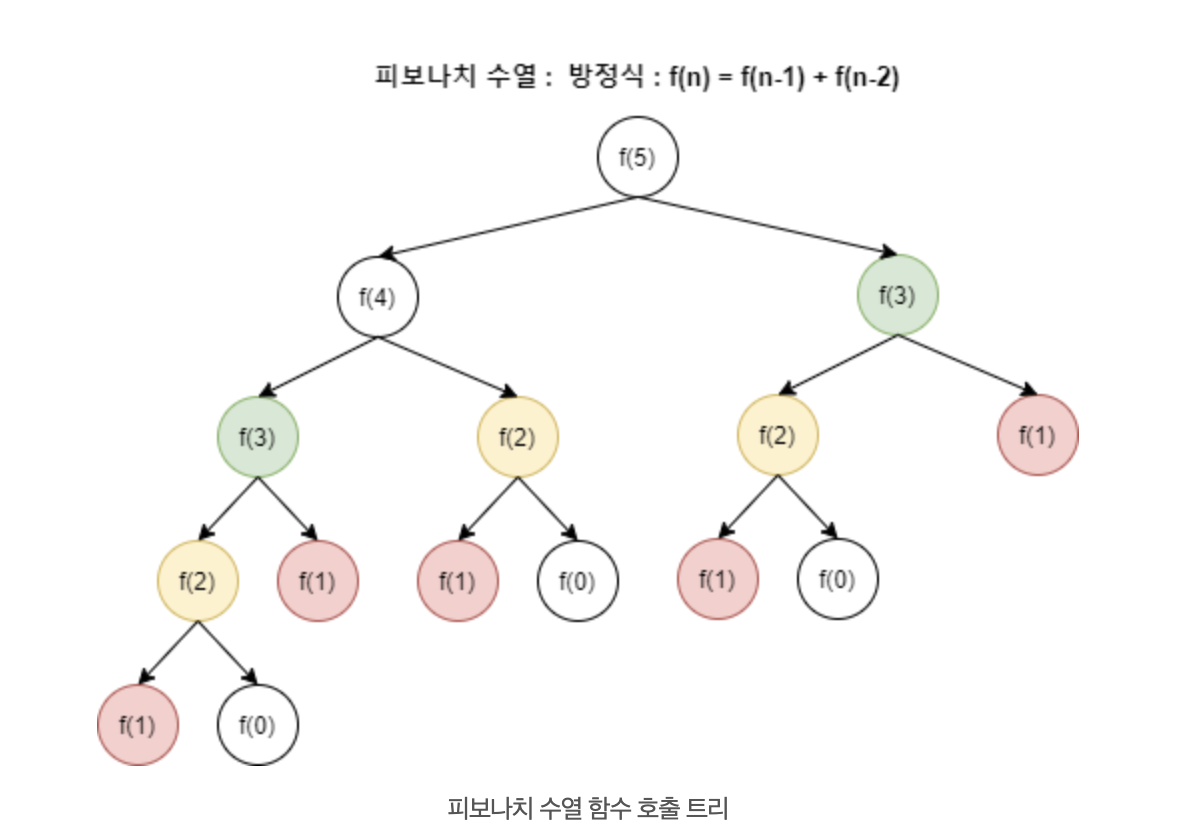
바로 이럴 때, 한 번 구한 값을 저장해두고 다시 사용한다면 앞에서 한 계산을 반복할 필요가 없이 계산이 가능해진다. 매우 효율적으로 문제를 해결할 수 있게 되는데, 시간 복잡도를 기준으로 O(n2) > O(f(n))으로 개선된다.
DP 사용하기
▼ DP를 사용하기 좋은 문제의 조건
1. Overlapping Subproblems (겹치는 부분 문제)
2. Optimal Substructure(최적 부분 구조)▼ DP 풀이 순서
1. DP로 풀 수 있는 문제인지 조건을 따져 확인한다.
2. 문제의 변수를 파악한다.
3. 변수간의 관계식을 만든다. (점화식)
4. 메모하기
5. 기저 상태 파악하기
6. 구현하기
1. DP로 풀 수 있는 문제인지 확인
현재 직면한 문제가 작은 문제들로 이루어진 하나의 함수로 표현될 수 있는지를 판단해야 한다.
보통 특정 데이터 내 최대화 / 최소화 계산을 하거나, 특정 조건 내 데이터를 세야 한다거나 확률 등의 계산의 경우 DP로 풀 수 있는 경우가 많다.
2. 문제의 변수 파악
DP는 현재 변수에 따라 그 결과 값을 찾고 그것을 전달하여 재사용 하는 것을 거친다
예를들어, 피보나치 수열에서는 n번째 숫자를 구하는 것이므로 n이 변수가 된다.
문자열 간의 차이를 구하는 경우 문자열의 길이, Edit거리 등 2가지 변수를 사용한다.
유명한 Knapsack 문제의 경우 index, 무게로 2가지의 변수를 사용한다.
3. 변수 간 관계식 만들기
변수들에 의해 결과 값이 달라지지만, 동일한 변수값인 경우 결과는 동일하다. 또한 우리는 그 결과값을 그대로 이용해야하므로 그 관계식을 만들어 낼 수 있어야 한다. = 점화식
예를 들어 피보나치 수열에서는 f(n) = f(n-1) + f(n-2)
4. 메모하기
점화식이 정상적으로 만들어졌따면, 변수의 값에 따른 결과를 저장해야한다.
변수값에 따른 결과를 저장할 배열 등을 미리 만들고 그 결과를 나올 때마다 배열 내에 저장하고 그 저장된 값을 재사용하는 방식으로 문제를 해결해나간다. 결과 값을 저장할 때는 보통 배열을 사용하며 변수의 개수에 따라 1~3차원의 배열을 사용한다.
5. 기저 상태 파악
가장 작은 문제의 상태를 알아야한다. 보통 몇 가지 예시를 손으로 테스트하여 구성하는 경우가 많다.
피보나치 수열을 예로 들면 f(0) = 0, f(1) = 1, 같은 방식이다.
6. 구현하기
DP는 2가지 방식으로 구현할 수 있다.
1. Bottom-Up(Tabulation 방식) - 반복문 사용
2. Top-Down (Memorization 방식) = 재귀 사용
Bottom-Up 방식
아래에서 부터 계산을 수행하고 누적시켜서 전체 큰 문제를 해결하는 방식
메모를 위해서 dp라는 배열을 만들었고, 이것이 1차원이라 가정했을 때 dp[0]이 기저 상태이고 dp[n]을 목표상태라 하면, Bottom-Up은 dp[0]에서부터 시작하여 반복문을 통해 점화식으로 결과를 내서 dp[n]까지 그 값을 전이시켜서 재활용하는 방식이다.
subproblem을 작은 것부터 순서대로 해결하여 최적의 solution을 찾아낸다.
public static int bottomUp(int n){
//기저 상태의 경우 사전에 미리 저장
bottomUp_memo[0] = 0;
bottomUp_memo[1] = 1;
for(int i =2; i<=n; i++){
bottomUp_memo[i] = bottomUp_memo[i-1] + bottomUp_memo[i-2];
}
return bottomUp_memo[n];
}Top-Down 방식
dp[0]의 기저 상태에서 출발하는 대신 dp[n]의 값을 찾기 위해서 위에서부터 바로 호출을 시작하여 dp[0]의 상태까지 내려간 다음 해당 결과값을 재귀를 통해 전이시켜 재활용하는 방식
피보나치의 예시처럼, f(n) = f(n-1) + f(n-2)의 과정에서 함수 호출 트리의 과정에서 보이듯, n=5일 때, f(3),f(2)의 동일한 계산이 반복적으로 나옴
이미 계산이 완료 된 경우 단순히 메모리에 저장되어 있던 내역을 꺼내서 활용하면 된다. 그래서 가장 최근의 상태 값을 매모해두었다고 표현하여 Memorization이라고 부른다.
private static int topDown(int n) {
//기저 상태 도달시, 0,1로 초기화
if (n < 2) return topDown_memo[n] = n;
//메모에 계산된 값이 있으면 바로 반환
if (topDown_memo[n] > 0) return topDown_memo[n];
//재귀를 사용하고 있음
topDown_memo[n] = topDown(n - 1) + topDown(n - 2);
return topDown_memo[n];
}Cf. 일반 재귀 함수를 사용한 경우
//동일한 계산을 반복하여 비효율적으로 처리가 수행됨
private static int navieRecursion(int n) {
if (n <= 1) {
return n;
}
return navieRecursion(n - 1) + navieRecursion(n - 2);
}결과
832040
일반 재귀 소요 시간 : 7
832040
Top-down 소요 시간 : 0
832040
Bottom-Up 소요 시간 : 0cf. 분할정복과의 차이점
분할정복과 동적프로그래밍은 주어진 문제를 작게 쪼개서 하위 문제로 해결하고 연계적으로 큰 문제를 해결한다는 공통점을 갖고 있다.
차이점은 '중복'이 일어나는지의 여부인데, 분할 정복은 분할 된 하위 문제가 동일하게 중복이 일어나지 않는 경우에 쓰며, 동일한 중복이 일어나는 경우 동적 프로그래밍을 쓴다.
