이번에는 VGG16 모델을 활용한 이미지 분류 학습에 대하여 알아보자.
VGG16이란?
이미지 분류에 있어 가장 간단하고 널리 활용되는 방법이다. Convolutional Layer의 일부를 동결하고 부분 재학습을 통해 모델을 활용할 수 있다. 이번 모델 학습의 경우엔 block 5를 제외하고 동결한다.
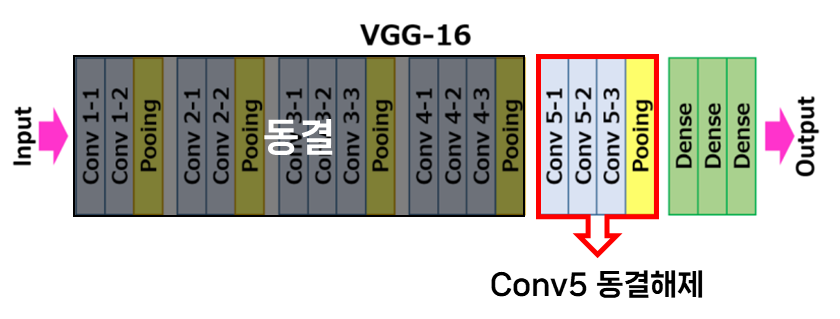
1. VGG16 모델 업로드하기
VGG16 = tf.keras.applications.vgg16.VGG16(weights="imagenet",
include_top=False,
input_shape=(128, 128, 3))
VGG16.trainable = True
for layer in VGG16.layers[:-4]:
layer.trainable = False #block5을 제외한 모든 층을 동결2. 모델 제작하기
from tensorflow.keras import models, layers
model = models.Sequential()
model.add(VGG16)
model.add(layers.Flatten())
model.add(layers.Dense(256, activation = 'relu'))
model.add(layers.Dropout(0.4))
model.add(layers.Dense(5, activation = 'softmax'))설정한 VGG16 모델에 Dense layer를 추가하여 학습에 활용할 모델 제작을 진행한다.
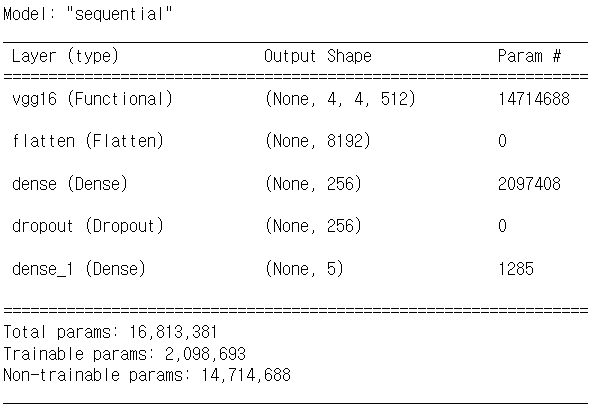
3. 모델 학습하기
from tensorflow.keras import optimizers
model.compile(loss = 'categorical_crossentropy',
optimizer = optimizers.Adam(learning_rate = 0.000005),
metrics = ['accuracy'])%%time
history = model.fit(train_generator,
steps_per_epoch = train_df.shape[0]//75,
epochs = 15,
validation_data = validation_generator,
validation_steps = test_df.shape[0]//75)Epoch 1/15
27/27 [============] - 218s 8s/step - loss: 2.0322 - accuracy: 0.2035 - val_loss: 1.7179 - val_accuracy: 0.2400
Epoch 2/15
27/27 [============] - 225s 8s/step - loss: 1.7929 - accuracy: 0.1916 - val_loss: 1.5342 - val_accuracy: 0.2311
Epoch 3/15
27/27 [============] - 220s 8s/step - loss: 1.6561 - accuracy: 0.2435 - val_loss: 1.4195 - val_accuracy: 0.5022
.
.
.
Epoch 15/15
27/27 [============] - 244s 9s/step - loss: 0.9565 - accuracy: 0.6933 - val_loss: 0.7037 - val_accuracy: 0.9422
CPU times: total: 3h 26min 18s
Wall time: 1h 17s4. 학습 결과 확인하기
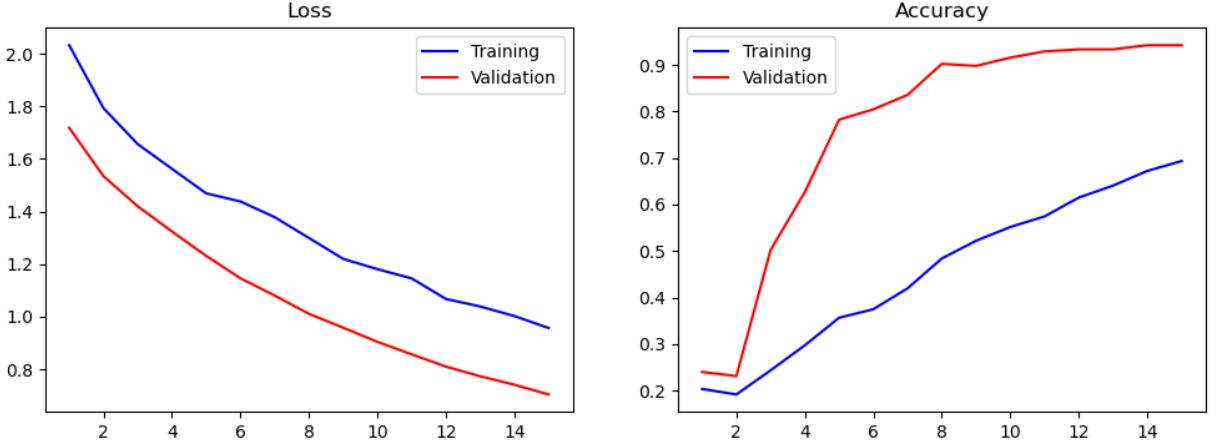
앞서 진행한 CNN, ResNet50을 활용한 모델 학습에 비해 정확도도 약간 떨어지고, 학습시간이 1시간을 넘는 모습을 보였다. 왜지...??
어쨌든 이번에도 마찬가지로 loss, accuracy에 대한 시각화 작업 및 test 데이터셋을 활용한 검증 과정을 거쳤다.
# Test 데이터셋으로 성능 확인하기
test_datagen = ImageDataGenerator(rescale = 1./255)
test_generator = test_datagen.flow_from_dataframe(test_df,
x_col='Filepath',
y_col='Label',
target_size=(128, 128),
batch_size=75)
loss, accuracy = model.evaluate(test_generator)
print('Loss = {:.5f}'.format(loss))
print('Accuracy = {:.5f}'.format(accuracy))Found 250 validated image filenames belonging to 5 classes.
4/4 [==============] - 30s 7s/step - loss: 0.6769 - accuracy: 0.9520
Loss = 0.67694
Accuracy = 0.95200확실히 앞선 CNN, ResNet 모델보다 loss가 높고, accuracy도 다소 떨어진다.
model.save('VGG16_test.h5')이렇게 모델 저장까지 모두 마쳤다. 다음 포스팅에는 학습된 모델을 불러와 이미지를 예측하는 실습에 대한 포스트를 업로드한다.
github 주소 : https://github.com/Kihoon-Kwon/multiclass_ImageClassification.git

꾸준하게 😊