
Database에서 자주 primary key로 uuid와 auto increment integer를 사용하는데 이 둘의 장단점에 대해 알아보자.
UUID
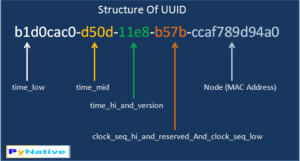
UUID는 128 bit, 32자리의 16진수로 이루어진 아래 그림과 같은 모습의 숫자이다. (종류가 몇 가지 있긴 하다) 랜덤한 숫자로 볼 수 있고 실질적으로 유일하기 때문에 primary key로 사용한다. 실질적으로 유일하다는 말은 매우 큰 수를 랜덤하게 발생시키기 때문에 중복할 확률이 극히 낮다는 뜻이다. (2^128)
Pros
- Globally unique.
- Stateless, it can be generated on the fly.
- Secure since malicious user can't guess the ID.
- Version 1 UUID stores timestamp info, could be useful sometimes.
Cons
Not readable.
For database like MySQL, Oracle, which uses clustered primary key, version 4 randomly generated UUID will hurt insertion performance if used as the primary key. This is because it requires reordering the rows in order to place the newly inserted row at the right position inside the clustered index. On the other hand, PostgreSQL uses heap instead of clustered primary key, thus using UUID as the PK won't impact PostgreSQL's insertion performance.
Auto Increment Integer/Sequence
Pros
- Readable. This is especially valuable if we would expose it externally. Thinking of issue id, obviously, issue-123 is much more readable than issue-b1e92c3b-a44a-4856-9fe3-925444ac4c23.
Cons
- It can't be used in the distirbuted system since it's quite likely that different hosts could produce exactly the same number.
- It can't be generated on the fly. Instead, we must consult the database to figure out the next available PK.
- Some business data can be exposed, since the latest ID could represent the total number of inventory. Attackers can also scan the integer range to -- explore leakage (though it shouldn't happen if ACL is implemented correctly).

내가 보려고 쓰는 글