
이 글의 Scope
Application level에서 DB선택과 modeling에 도움이 될만한 scope
What is cassandra
Cassandra는 Google의 Big table로부터 영향 받았으며 facebook에서 시작되어 apache 오픈소스가 된 NoSQL 분산 database이다. 대용량 데이터를 다루기 위한 scalability와 availability에 초점을 맞춰 디자인됐다.
- 대용량 데이터의 Write 성능에 최적화 되게 디자인 되었다.
- 분산 저장 된다.
- Data를 duplicate하게 저장한다.
- RDB와 유사하게 칼럼들을 미리 정하지만 로우마다 칼럼을 필수적으로 사용하지 않아도 된다는 점이 특징적이다.
- 대부분의 NoSQL이 그러하듯이 Join을 지원하지 않는다.
- SQL과 언뜻 보면 비슷해 보이는 CQL이라는 쿼리를 사용할 수 있다.
Architecture
Cassandra의 architecture는 기본적으로 데이터를 하나 이상의 노드에 분산해서 저장하는 distributed system이며 masterless architecture이다.
Masterless란 master-slave와 대척점에 있는 개념이며 시스템을 구성하는 모든 노드가 identical role을 갖는다.
참고) master-slave는 write가 가능한 Master instance와 Read replica의 역할이 나누어져 있는 것과 같은 시스템을 말한다.
Cassandra는 노드들로 이루어진 링 구조를 갖는다. 데이터는 링에 분산 저장된다.
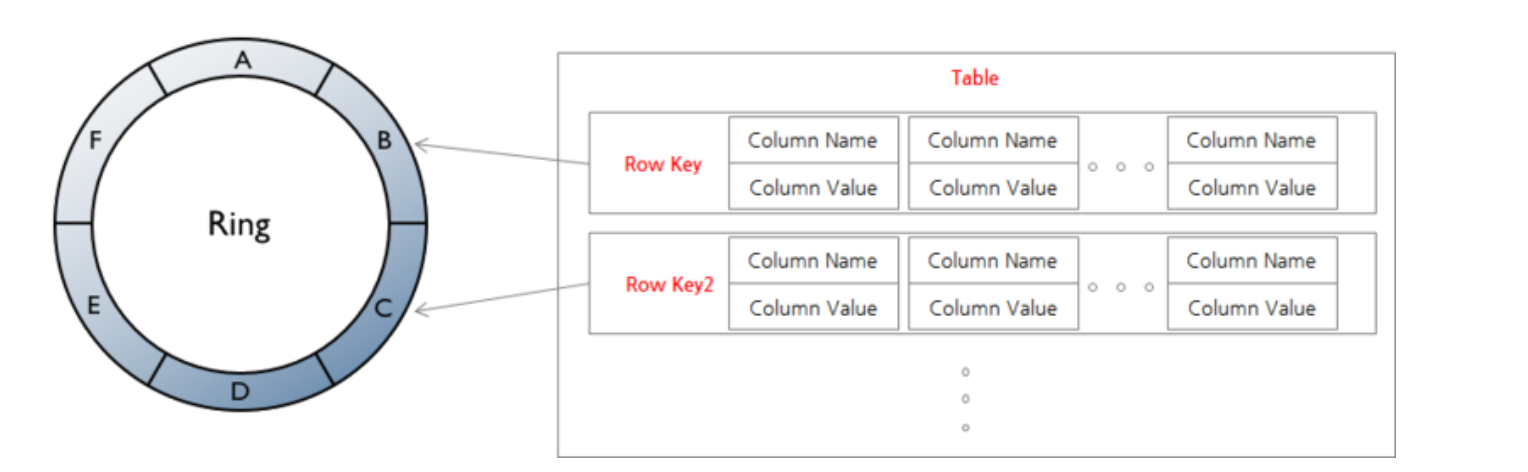
Cassandra는 로우들을 node에 분산해서 저장한다. 뿐만 아니라 availability를 위해 데이터를 복제해서 여러 번 저장한다.
데이터는 어떻게 저장될까?
Primary key
RDB에서도 primary key가 있다. RDB에서의 primary key는 row의 unique함을 보장하기 위한 key이다. cassandra에서는 그것보다 많은 역할을 한다. Primary key는 하나 이상의 column으로 이루어져 있고 첫번째 부분을 partition key과 나머지 부분인 clustering key로 이루어져 있다. 아래 예시에서 ((machine_id, log_date), log_time)이 primary key이다.
Partition key
partition key로 데이터를 어떤 노드에 저장할지를 결정한다. 이는 위 예시처럼 하나 이상의 column을 선택한다. partition key가 같으면 같은 노드에 저장한다. 아래의 예시에서 app_name, env가 partition key이다.
Clustering key
primary key의 나머지 부분이다. 노드 내에서 clustering key 기준으로 sorting 되어 저장된다. 아래의 예시에서 hostname, log_datetime이 cluster key이다. sorting 되어 있기 때문에 update pattern에는 적합하지 않다.

Data modeling
Cassandra는 데이터를 저장하는 방식이 RDB와 상당히 다르다. 따라서 모델링 할때는 cassandra의 저장 방식을 충분히 이해하고 고려해서 모델링해야한다.
그렇다면 필연적으로 Read query pattern에 따라 key를 설정해야 하게 된다. Cassandra는 쿼리 패턴을 미리 알고 데이터를 그 형태에 맞게 미리 저장하는 database이다.
기본적으로는 Partition key로는 EQ,IN 쿼리만 가능하고 Column Key로만 Range Query가 가능하다고 생각하고 디자인 해야한다.
ALLOW FILTERING이라는 옵션을 사용해서 위 경우가 아닌 경우에도 쿼리가 가능하지만 심각한 성능 저하를 야기하기 때문에 추천하지 않는다. 왜 성능 저하가 있는지가 이해가 가지 않는다면...잘 생각해보자
예를 들면 created_time같은 column을 partition key로 사용하는 것은 어떨까? created_time이 partition key라면 어떤 쓸모 있는 read query도 날릴 수 없게 된다.
또 다른 예시로, id를 부여하고 partition key에 넣는다면? 이것도 마찬가지로 어떤 쓸모 있는 read query도 날릴 수 없다.
이런 부분들을 고려하다 보면 두개 이상의 pattern이 빈번한 케이스의 경우에는 partition key를 정하기 어려운데 이런 경우에는 pattern에 따라 다른 테이블을 정의하면 된다. 그것이 NoSQL의 철학이기 때문이다.
Ideal cassandra use case
- Writes exceed reads by a large margin.
- Data is rarely updated and when updates are made they are idempotent.
- Read Access is by a known primary key.
- Data can be partitioned via a key that allows the - - database to be spread evenly across multiple nodes.
- There is no need for joins or aggregates.
Consistency level / Replication factor
Consinstency level과 replication factor을 설정하게 되는데 이에 관해서는 다음에 다루도록 하자. 궁금하면 이곳이 설명이 잘 되어 있는 것 같으니 참고~
