들어가면서
다익스트라 알고리즘 문제 해결 과정과,
처음으로 주석을 적극적으로 사용해서 문제를 해결해보는 과정에서 미숙했던
부분을 기록해보고, 어떻게 개선해나갈지 생각해본다.
주석을 이용한 문제 해결 과정
주석을 적극적으로 사용해서 문제 풀이를 시도해봤다.
그런데, 너무 적극적이었던게 문제였을까? 코드 작성 & 문제 해결 < 주석 작성이 되어버렸다.
즉, 주객 전도되어 버렸다..
아래는 주석을 사용하여 문제 풀이한 과정의 일부분을 캡처한 것이다.
흠...🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔 ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ 이게 맞나..?
주석으로 내 생각의 흐름을 적어가면서 문제를 풀이하려 했는데 너무 무분별하게 주석을 사용해버린 것 같다.
물론 문제를 모두 풀고 나면 주석을 제거할 생각이었는데,
주석이 너무 길어서 코드들이 안보였고, 가독성을 많이 떨어트리고 있었다.
주석을 사용하는건 좋은데 최대한 짱구를 굴려가면서 써야할 것 같다.
머릿속에서 어느정도 정리하고 간략하게 주석을 적어가야지 할 것 같다.
다익스트라 문제 해결 과정
각 정점과, 간선 정보가 주어지면
1번 정점에서 각 정점으로 이동하는 최소 거리 비용을 구해야 한다.
일단 간선 정보를 담아줘야할 객체가 필요하다고 생각했고,
2차원 ArrayList를 사용하면 되겠다는 생각을 했다.
2차원 ArrayList는 간선 정보를 담기 좋은 객체 구조를 가지고 있다.
6 9
1 2 12
1 3 4
2 1 2
2 3 5
2 5 5
3 4 5
4 2 2
4 5 5
6 4 5
위와 같이 정점 정보와 간선 정보를 입력했을 때 2차원 ArrayList는 아래와 같다.
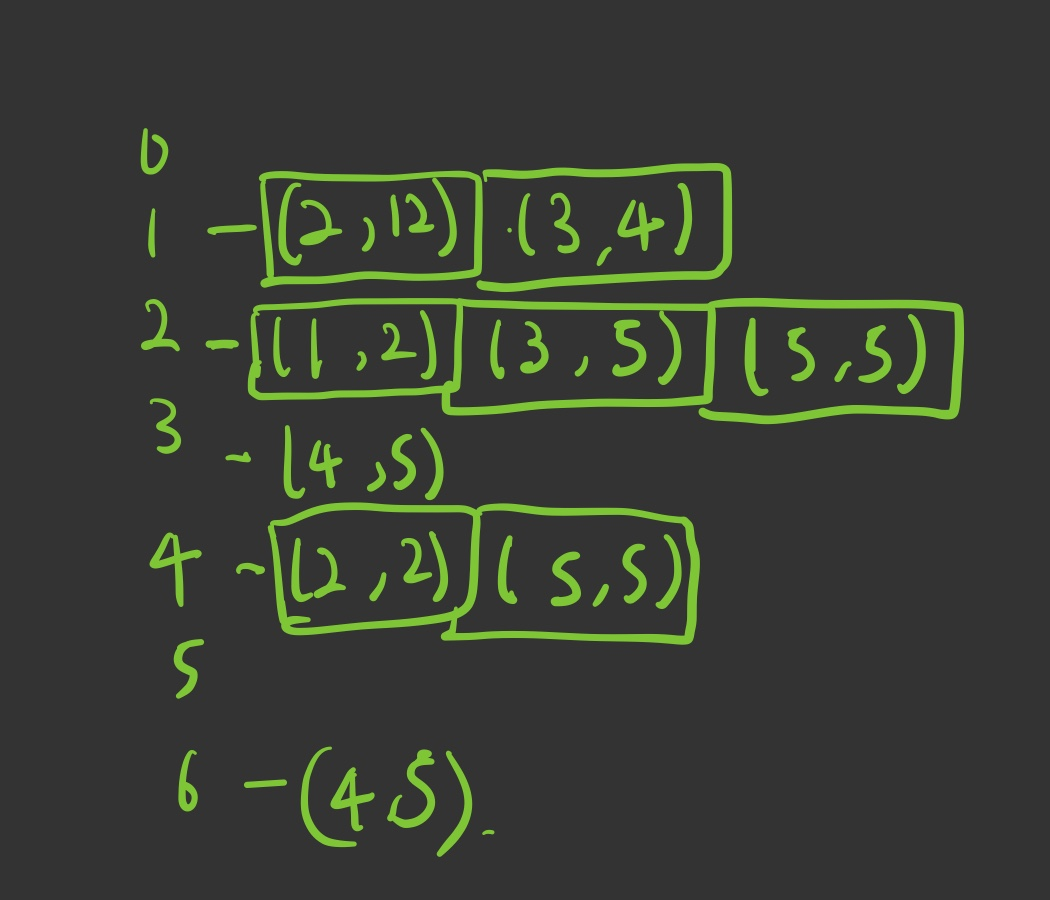
왼쪽 0 1 2 3 4 5 6은 각 정점들이고,
1번 정점에서 (2,12), (3,4)는 간선 정보를 의미한다.
2차원 ArrayList를 초기화하는 과정에서 어려웠던 사항들이 몇가지 있었는데 해당 개념을 공부하고 이해해서 블로그에 기재해놨다.
아래는 내가 2차원 ArrayList를 정리한 블로그 주소이다.
링크(2차원 ArrayList 정리) : https://velog.io/@ni0307/2%EC%B0%A8%EC%9B%90-ArrayList%EB%A5%BC-%EC%95%8C%EC%95%84%EB%B3%B4%EC%9E%90
우여곡절 끝에 2차원 ArrayList는 초기화하고 디버깅을 통해 내가 원하는대로 값이 잘 담기는걸 확인했다.
ArrayList<ArrayList<EdgeTwo>> graph = new ArrayList<ArrayList<EdgeTwo>>();
// graph의 크기를 초기화 해준다.
// ArrayList 인덱스에 접근할 수 있도록 공간을 확보해준다.
for(int i = 0; i <= n; i++){
graph.add(new ArrayList<EdgeTwo>());
}
// j는 간선의 수 = 9
for(int j = 0; j < m; j++){
int a = in.nextInt(); // 첫번 째 정점
int b = in.nextInt(); // 두번 째 정점
int c = in.nextInt(); // 첫번째 정점 -> 두번째 정점 거리 비용
graph.get(a).add(new EdgeTwo(b, c));
}이제 solution 로직만 짜면 된다... 후...
처음에는 이중 for문으로 접근했다.
for(int i = 1; i <= n; i++){
for(EdgeTwo ob : graph.get(i)){
.... // solution이 들어갈 곳..
}
}solution이 들어갈 곳에 graph.get(i)에 담겨있는 간선 정보들을 하나씩 출력해서
다음으로 이동해야 하는 정점의 길이를 pQ(PriorityQueue)에 담아주고, 만약 다음에 이동하는 정점이 내가 의도한 정점이 아니라면 또 아래와 같이 선언해주고... 그 다음에 이동하는 정점이 내가 의도한 정점이 아니라면 또 .... 계속 반복... 엥?🤔 for문을 내가 직접 선언해줘야 하는 문제가 발생했다..!
for(EdgeTwo x : graph.get(ob.dot)){
.... // solution이 들어갈 곳..
}
잘못 접근하고 있다는걸 직감적으로 알 수 있었다.
고민하다가, 문제 풀이에 2시간 이상 고민하게 되어서 풀이 강의를 보기로 했다.
일단 PriorityQueue 타입 pQ가 반환하는 객체 타입이 EdgeTwo인데,
EdgeTwo.len 값이 오름차순으로 정렬되게 한 뒤에 가장 상위에 있는 값이 poll()될 수 있도록 설정해줘야 했다.
즉, pQ에서 최솟값이 먼저 반환되도록 설정해줘야 했다.
그 코드는 아래와 같다.
class EdgeTwo implements Comparable<EdgeTwo>{
public int dot;
public int len;
public EdgeTwo(int dot, int len){
this.dot = dot;
this.len = len;
}
//pQ에서 최소가 되는 len 값을 꺼낸다
@Override
public int compareTo(EdgeTwo o){
return this.len - o.len;
}
}그 이유는 첫번째로 PriorityQueue의 특성 때문이다.
PriorityQueue는 객체 타입을 반환할 때 우선순위가 주어져야 실행할 수 있다.
만약 우선순위가 주어지지 않는다면
아래와 같은 에러가 발생한다.
java.lang.ClassCastException
두번째로 다익스트라의 알고리즘 특성 때문이다.
다익스트라는 첫번째 노드 위치부터 각 노드로 향하는 거리 비용을 구하는 문제인데,
현재 정점 위치에서 다음 인접한 다음 정점으로 향하는 거리 비용이 최솟값일 때 가장 적은 거리 비용이 발생할 수 있어야 한다.
pQ에서 거리 비용이 최솟값인 간선 정보를 poll() 해서 tmp 변수에 담아주기 때문에
현재 정점에서 다음 정점으로 가는 최소 거리 비용을 구할 수 있게 되는 것이다.
이제 대망의 solution 로직이다.
solution 로직에 들어가기에 앞서서
현재 정점에서 다음으로 이동하는 거리 비용이 최소로 설정되게 하려면 어떻게 해야할까?
어떤 자료구조를 써야할까?
1번에서 2번 정점으로 가는 최소 거리 비용,
1번에서 3번 정점으로 가는 최소 거리 비용,
1번에서 4번 정점으로 가는 최소 거리 비용,
...
1번에서 6번 정점으로 가는 최소 거리 비용,
총 n+1개의 최소 거리 비용 정보를 담고 있는 배열이 필요하다.
(n번 정점 거리 비용 정보도 담아야 하므로 n+1로 설정한다.)
따라서 아래와 같이 코드를 작성한다.
int[] dis = new int[n+1];
// dis의 모든 인덱스에 최댓값 삽입
Arrays.fill(dis, Integer.MAX_VALUE);왜 dis 배열의 모든 인덱스에 MAX 값을 넣을까?
그 이유는 solution 로직에서 loop문을 돌면서 dis 배열에 최솟값을 채워넣어가기 때문이다.
아래 로직을 보자.
public void solution(ArrayList<ArrayList<EdgeTwo>> graph, int n, int k){
// 최소 거리 비용을 구하자.
PriorityQueue<EdgeTwo> pQ = new PriorityQueue<>();
//1번 정점 최솟값을 0으로 초기화 시켜준다.
pQ.offer(new EdgeTwo(k, 0));
dis[k] = 0;
while(!pQ.isEmpty()){
//pQ에서 최솟값을 꺼낸다.
EdgeTwo tmp = pQ.poll();
//now = 1
int now = tmp.dot;
//nowLen = 0
int nowLen = tmp.len;
// now 정점의 len 값이 최솟값이 아니면 continue
if(nowLen > dis[now]) continue;;
//
for(EdgeTwo ob : graph.get(now)){
// ob 객체는 now 정점에서 갈 수 있는 모든 정점의 정보이다.
// 그 값들 중에서 거리 비용이 더 작을 때 dis에 값을 담아주고
// 해당 간선 정보를 pQ에 담아준다.
if(dis[ob.dot] > nowLen + ob.len){
dis[ob.dot] = nowLen+ ob.len;
pQ.offer(new EdgeTwo(ob.dot, nowLen + ob.len));
}
}
}
}
위 코드는 loop문이 맨 처음 돌 때라고 가정한다.
처음에 1번 인덱스부터 다른 정점으로 뻗어나가야 하기 때문에
pQ.offer(new EdgeTwo(1, 0));로 선언해줬다.
따라서 now = 1, nowLen = 0이 된다.
dis[now]는 현재 MAX 값을 가지고 있다. 따라서, continue 하지 않는다.
그런데, 만약에 dis[now] 값 보다 nowLen 값이 더 크다고 가정해보자.
nowLen이 더 크다는 것은 1번 정점에서 now 정점까지 가는 거리 비용이 더 크다는 소리이므로 더 알아볼 필요도 없다.
더 자세히 설명해보자면
1번 정점에서 각 정점으로 향할 때 반드시 양수의 값이 더해지게 되는데 nowLen 값이
dis[now]보다 높다는 것은 앞으로 최솟값을 구하게 될 가능성이 전혀 없다는 의미이므로
loop문을 continue하게 되는 것이다.
for(EdgeTwo ob : graph.get(now)){
// ob 객체는 now 정점에서 갈 수 있는 모든 간선 정보이다.
// 해당 간선 정보를 pQ에 담아준다.
if(dis[ob.dot] > nowLen + ob.len){
dis[ob.dot] = nowLen+ ob.len;
pQ.offer(new EdgeTwo(ob.dot, nowLen + ob.len));
}
}위 코드를 살펴보자
graph.get(now)는 현재 정점에서 다음 정점으로 가는 간선 정보를 담고 있다.
예를 들어 now = 1일 때
graph.get(1)은
(2,12), (3,4) 간선 정보를 담고 있다.
dis[ob.dot]은 이전에 등록된 최소 간선 정보를 의미한다.
dis[ob.dot]이 현재 정점 -> 다음 정점으로 이동했을 때의 거리 비용보다 높다면
최솟값이 아니라고 볼 수 있으므로 해당하는 정점 값을 바꿔주고,
그 정점에서 또 다른 정점으로 뻗어나갈 수 있도록 pQ.offer() 해주는 것이다.
이렇게 되면 pQ에는 (2,12)와 (3,4)가 담길텐데 len 값을 기준으로 최솟값이 먼저 poll()되기 때문에 (3,4)가 먼저 반환된다.
(이 이유는 위에서 설명함.)
그러면 현재 정점 (3,4) -> (4, 5) 정점으로 뻗어나갈 수 있고 dis[4] = 9라는 값이 담기게 되고
(4,5) 간선 정보가 pQ.offer() 될 것이다. 또 (4,5)가 먼저 반환되어
(4, 5) -> (2,2) or (5,5)가 있는데 4 -> 2로 갔을 때 거리 비용이 2이다.
그러면 1 -> 3 -> 4 -> 2로 향했을 때 거리 비용이 가장 최소 이므로
dis[2] = 11로 변환된다.
이런 방식으로 계속 loop 문을 돌면서 첫번째 정점에서 각 정점으로 향하는 최소 비용을 구하게 된다.
알게된 점
2차원 ArrayList
2차원 ArrayList와 1차원 ArrayList의 차이점,
2차원 ArrayList 초기화 방법,
2차원 ArrayList가 인덱스 공간을 초기화해줘야 하는 이유
.. 등을 배웠다.
PriorityQueue 정렬 방식 설정
PriorityQueue가 임의의 객체 타입을 반환할 때 compareTo 메서드로 정렬 방식을 설정해줘야 한다는 사실을 알았다.
PrioirityQUeue를 사용할 때 Integer, String, Double과 같은 객체들을 사용하면 정렬 방식을 따로 설정하지 않아도 됐었는데
그건 Java에서 제공하는 객체들은 이미 정렬 방식이 설정되어 있기 때문이었다.
다익스트라 알고리즘에 대한 이해
다익스트라 알고리즘을 명확하게 이해할 수 있게 되었다.
