🔹 0. INTRO
- INTRO
-
MySQL, PostgreSQL, Oracle 등 데이터베이스에 저장되어있는 데이터를 Python으로 다루는 것에는 다양한 방법들이 존재합니다.
첫 번째로는
pymysql,psycopg2,oracledb등 각 RDBMS에 맞는 파이썬 라이브러리를 활용하는 방법이 있으며 가장 직관적이기도 하죠.두 번째는 하나의 라이브러리로 여러가지 RDBMS에 대한 연결을 생성하면서 ORM 매핑까지 가능하게 해주는
sqlalchemy같은 라이브러리를 활용하는 것입니다.데이터베이스에 저장된 데이터를 Python으로 다루기 위해서는 Connection 생성이 반드시 필요한데 위의 두 가지 방법을 대부분 많이 사용하실거라 생각합니다.
-
이번 글에서는 아마도 잘 알려지지 않은
dataset이라는 Python 라이브러리를 활용하여 데이터베이스 내부에 저장된 데이터를 다루어보는 과정을 정리해 볼 것입니다.
🔹 1. dataset 라이브러리란?
→ dataset 라이브러리 공식 문서
→ dataset pypi 문서
dataset라이브러리는sqlalchemy의 기능들을 베이스에 활용하고 있으며, SQL 언어에 대한 지식이 많이 없더라도 쉽게 데이터베이스와 상호작용할 수 있도록 설계되었습니다. 특히, 테이블들을 dictionary 형태로 다룰 수 있도록 설계되어 복잡한 SQL 쿼리 없이도 데이터에 대한 CRUD 작업을 간단히 수행할 수 있습니다.sqlalchemy는 ORM 작업을 위해 테이블을 일일히 매핑해주어야 했지만,dataset은 그 과정 없이도 테이블을 python 메소드로 다룰 수 있어 상당히 편리했으며, 핵심적인 기능들은 대부분 구현이 되어있었습니다.- 아직 지원하는 RDBMS가
MySQL,PostgreSQL,SQLite이렇게 세 개 밖에 없다는 한계점을 가지고 있긴 하지만 기능적으로 상당히 매력적인 라이브러리라는 느낌이 들었습니다.
라이브러리 설치
pip install dataset
🔹 2. 데이터베이스 Connection 생성
- 가장 먼저 선행되어야 할 코드인 데이터베이스와 Connection을 생성하는 부분입니다.
sqlalchemy방식을 활용하고 있기 때문에 형식이 비슷합니다. - 아래 실습에서는
MySQL에 Connection을 생성하여 코드를 작성해보도록 할 것 입니다.
user = "root"
password = "123456"
host = 'localhost'
port = 3306
database = 'velog'
db = dataset.connect(f'mysql://{user}:{password}@{host}:{port}/{database}')
"""
PostgreSQL 연결 코드
dataset.connect(f'postgresql://{user}:{password}@{host}:{port}/{database}')
"""🔹 3. 테이블 단위 조회
velog데이터베이스 안에 저장되어 있는 테이블 목록은 아래와 같으며 해당 테이블들을 대상으로 코드를 구성해 볼 것이다.- pizzas
- pizza_types
- orders
- order_details
📍 1. 테이블 목록 조회
db.tables
---
['order_details', 'orders', 'pizza_types', 'pizzas']📍 2. 테이블 유무 확인
db['pizzas'].exists
---
True📍 3. 개별 테이블 불러오기
# 1
tbl = db['pizzas']
# 2
tbl = db.load_table('pizzas')
# 3
tbl = db.get_table('pizzas')📍 4. 테이블 컬럼 조회
db['pizzas'].columns
---
['pizza_id', 'pizza_type_id', 'size', 'price']📍 5. 테이블 row count
db['pizzas'].count()
---
96📍 6. 테이블 데이터 조회
result = db['pizzas']
for row in result:
print(row)
---
OrderedDict([('pizza_id', 'bbq_ckn_s'), ('pizza_type_id', 'bbq_ckn'), ('size', 'S'), ('price', Decimal('12.7500000000'))])
OrderedDict([('pizza_id', 'bbq_ckn_m'), ('pizza_type_id', 'bbq_ckn'), ('size', 'M'), ('price', Decimal('16.7500000000'))])
OrderedDict([('pizza_id', 'bbq_ckn_l'), ('pizza_type_id', 'bbq_ckn'), ('size', 'L'), ('price', Decimal('20.7500000000'))])
...📍 7. 특정 컬럼의 distinct 값 조회
result = db['pizzas'].distinct('size')
for row in result:
print(row)
---
OrderedDict([('size', 'L')])
OrderedDict([('size', 'M')])
OrderedDict([('size', 'S')])
OrderedDict([('size', 'XL')])
OrderedDict([('size', 'XXL')])📍 8. 필터링하여 데이터 조회
-
dataset라이브러리에서 사용할 수 있는 필터링 즉, WHERE 조건 관련되어서는 아래 표에 나열된 내용들을 적용할 수 있으며 해당 글에서는 이 중 일부에 대해서만 예시 코드를 작성해보았다.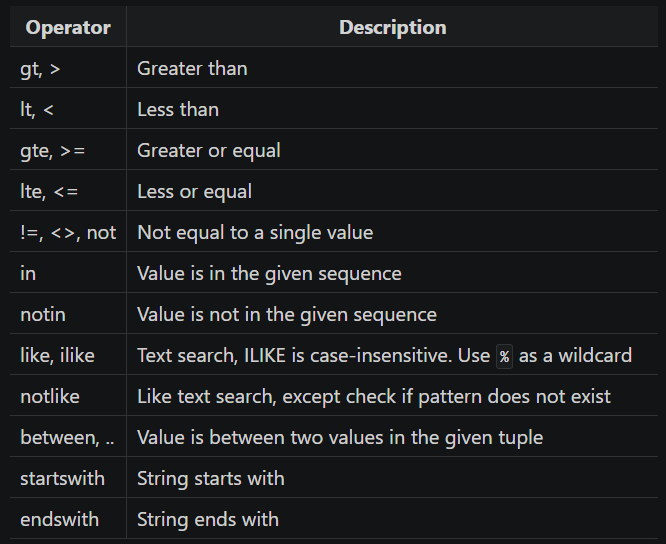
1) 특정 컬럼 값으로 필터링
result = db['orders'].find(order_id = [10,20,30])
for row in result:
print(row)
---
OrderedDict([('order_id', 10), ('date', '2015-01-01'), ('time', '13:00:15')])
OrderedDict([('order_id', 20), ('date', '2015-01-01'), ('time', '14:03:08')])
OrderedDict([('order_id', 30), ('date', '2015-01-01'), ('time', '15:41:25')])2) 대소 비교
# order_id가 5 이하인 row 출력
result = db['orders'].find(order_id={'<=' : 5})
for row in result:
print(row)
---
OrderedDict([('order_id', 1), ('date', '2015-01-01'), ('time', '11:38:36')])
OrderedDict([('order_id', 2), ('date', '2015-01-01'), ('time', '11:57:40')])
OrderedDict([('order_id', 3), ('date', '2015-01-01'), ('time', '12:12:28')])
OrderedDict([('order_id', 4), ('date', '2015-01-01'), ('time', '12:16:31')])
OrderedDict([('order_id', 5), ('date', '2015-01-01'), ('time', '12:21:30')])
3) IN 연산자 사용
# pizzas 테이블 size 컬럼에서 'L', 'XL' 인 row만 출력
result = db['pizzas'].find(size={'in' : ['L', 'XL']})
for row in result:
print(row)
---
OrderedDict([('pizza_id', 'bbq_ckn_l'), ('pizza_type_id', 'bbq_ckn'), ('size', 'L'), ('price', Decimal('20.7500000000'))])
OrderedDict([('pizza_id', 'cali_ckn_l'), ('pizza_type_id', 'cali_ckn'), ('size', 'L'), ('price', Decimal('20.7500000000'))])
OrderedDict([('pizza_id', 'ckn_alfredo_l'), ('pizza_type_id', 'ckn_alfredo'), ('size', 'L'), ('price', Decimal('20.7500000000'))])
...4) BETWEEN 연산자 사용
# order_id가 15 ~ 20 사이인 row 출력
result = db['orders'].find(order_id={'between' : [15, 20]})
for row in result:
print(row)
---
OrderedDict([('order_id', 15), ('date', '2015-01-01'), ('time', '13:33:00')])
OrderedDict([('order_id', 16), ('date', '2015-01-01'), ('time', '13:34:07')])
OrderedDict([('order_id', 17), ('date', '2015-01-01'), ('time', '13:53:00')])
OrderedDict([('order_id', 18), ('date', '2015-01-01'), ('time', '13:57:08')])
OrderedDict([('order_id', 19), ('date', '2015-01-01'), ('time', '13:59:09')])
OrderedDict([('order_id', 20), ('date', '2015-01-01'), ('time', '14:03:08')])
📍 9. SQL 쿼리로 조회하기
sql_query = """
SELECT
size,
COUNT(size) AS cnt
FROM pizzas
GROUP BY size
"""
result = db.query(sql_query)
for row in result:
print(row)
---
OrderedDict([('size', 'S'), ('cnt', 32)])
OrderedDict([('size', 'M'), ('cnt', 31)])
OrderedDict([('size', 'L'), ('cnt', 31)])
OrderedDict([('size', 'XL'), ('cnt', 1)])
OrderedDict([('size', 'XXL'), ('cnt', 1)])
📍 10. 데이터 삽입
- 데이터 삽입 및 업데이트 관련해서는
'id', 'name', 'year', 'gender', 'count'이렇게 5개의 컬럼이 있는names테이블을 대상으로 작업을 해 볼 것이다.
1) Row 1개 삽입
data = dict(name="Prime", year=2000, gender='F', count=2000)
db['names'].insert(data)2) Row 여러개 삽입
# 삽입 할 데이터를 dictionary list 형태로 만들어준다.
data = [dict(name="Prime", year=2000, gender='F', count=2000)]*5
db['names'].insert_many(data)📍 11. 데이터 업데이트
--- 1
# id가 1인 row의 count를 1000으로 변경
data = dict(id=1, count=1000)
# update(데이터, 기준 컬럼)
db['names'].update(data, ['id'])
--- 2
# name이 'Prime'인 row의 count를 1000으로 변경
data = dict(name="Prime", count=1000)
# update(데이터, 기준 컬럼)
db['names'].update(data, ['name'])📍 12. 데이터 삭제
--- 1
# id가 10인 row 삭제
mysql['names'].delete(id=10)
--- 2
# name이 'Prime'인 row 삭제
mysql['names'].delete(name='Prime')🔹 4. 컬럼 단위 조회
📍 1. 컬럼 유무 확인
db['pizzas'].has_column('size')
---
True📍 2. 컬럼 추가
1) 사용 가능한 데이터 타입 확인
[i for i in dir(db.types) if '_' not in i]
---
['bigint','boolean','date','datetime','float','guess','integer','json','string','text']2) 데이터 타입 명시하여 새로운 컬럼 추가
db['pizzas'].create_column('create_date', mysql.types.datetime)3) 예시 데이터 타입으로 새로운 컬럼 추가
# 'Delicious' 라는 예시 데이터의 타입으로 'message' 컬럼 추가
db['pizzas'].create_column_by_example('message', 'Delicious')📍 4. 컬럼 삭제
db['tips'].drop_column('message')📍 5. 컬럼에 인덱스 생성 및 확인
1) 인덱스 확인
# pizzas 테이블의 pizza_id 컬럼에 인덱스 적용이 되어있는지 확인
db['pizzas'].has_index('pizza_id')2) 인덱스 생성
# pizzas 테이블의 pizza_id 컬럼에 인덱스 생성
db['pizzas'].create_index('pizza_id')🔹 5. 심화 기능
📍 1. 테이블 생성
-
테이블 생성의 경우
create_table()메소드를 활용하면 되지만, 해당 메소드에 생성하려는 모든 컬럼을 다 명시할 수 없고, 테이블과 그 테이블의 PK가 되는 하나의 컬럼만 생성이 가능하다. 따라서 그 이후create_column()메소드를 통해 원하는 타입의 컬럼을 해당 테이블에 추가해주는 방식으로 테이블 생성이 가능하다. -
id(PK), region, create_date세 가지 컬럼을 가진 테이블 생성 코드table_name = "population" mysql.create_table( table_name=table_name, primary_id='id', # 최초 컬럼 이름 primary_type=mysql.types.bigint, # 컬럼 타입 primary_increment=True # Auto Increment 옵션 ) # 필요한 컬럼 추가 mysql[table_name].create_column('region', mysql.types.string(20)) mysql[table_name].create_column('cre_date', mysql.types.datetime)
📍 2. 테이블 삭제
# names 테이블 삭제
db['names'].drop()📍 3. View 목록 출력
# 해당 데이터베이스에 View가 생성되어 있다면 View 목록 출력
db.views
---
['pizzas_view']📍 4. Pandas와 연결하여 활용
- pandas의
read_sql()메소드 connector로 사용하게 되면 쿼리로 불러온 테이블 데이터를 바로 dataframe 형태로 다룰 수 있어 데이터 분석시 아주 편리하다.
import pandas as pd
db_engine = db.engine
pd.read_sql(
sql='SELECT * FROM pizzas',
con=db_engine
)
---
pizza_id pizza_type_id size price
0 bbq_ckn_s bbq_ckn S 12.75
1 bbq_ckn_m bbq_ckn M 16.75
2 bbq_ckn_l bbq_ckn L 20.75
3 cali_ckn_s cali_ckn S 12.75
4 cali_ckn_m cali_ckn M 16.75🔹 6. OUTRO
- 데이터베이스 데이터를 Python으로 다루는 작업을 자주 진행하는 입장에서, 최근에 알게 된
dataset라이브러리는 큰 흥미를 끄는 대상이었습니다. 사용해 볼수록 기존에 활용하던 라이브러리들에 비해 간결하고 직관적인 기능 구현이 인상적으로 다가왔습니다. 물론, 연결할 수 있는 데이터베이스의 수가 제한적이고, ORM 메소드의 다양성 면에서sqlalchemy에 비해 부족하다는 단점이 있긴 하지만, 제가 주로 사용하는 주요 기능들은 대부분 구현되어 있어 실용적으로 활용하기에 충분했습니다. 앞으로도 이 라이브러리를 자주 활용하게 될 것 같다는 생각이 듭니다.
