iloc으로 똑같이 컬럼을 분리한다고 생각하지만, shape가 다른 경우가 있다
잘 알려진 붓꽃 데이터를 준비함
import os
import pandas as pd
import numpy as np
s = os.path.join('https://archive.ics.uci.edu',
'ml',
'machine-learning-databases',
'iris',
'iris.data')
df = pd.read_csv(s, header=None, encoding='utf-8')
df.tail()
df.head()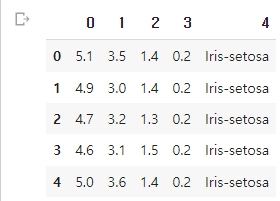
4번째 컬럼을 따로 떼어서 처리하고 싶은데, 다음 코드의 차이는?
a = df.iloc[:5, 4]
b = df.iloc[:5, [4]]| df.iloc[:5, 4] | df.iloc[:5, [4]] | 설명 | |
|---|---|---|---|
| pandas 출력 | 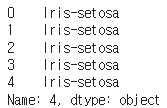 |  | 오른쪽에는 컬럼이 있다 |
| type | <class 'pandas.core.series.Series'> | <class 'pandas.core.frame.DataFrame'> | series vs dataframe |
| shape | (5,) | (5, 1) | 5 열이지만 행이 없는 vs 5행 1열 |
이번에는 .values를 사용해서 numpy로 변환해서 확인해보자
| df.iloc[:5, 4].values | df.iloc[:5, [4]].values | 설명 | |
|---|---|---|---|
| numpy 출력 | 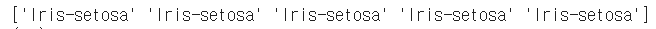 |  | 익숙한 배열 vs 1개짜리 배열이 5개 있는 모양 |
| type | <class 'numpy.ndarray'> | <class 'numpy.ndarray'> | 모두 numpy array |
| shape | (5,) | (5, 1) | 원소가 늘어선 배열의 표현법 vs 5 행의 공간마다 1열씩 배열이 채워진 표현 |
정리
- [4]를 붙이면 진짜 column 별로 떼어서 dataframe을 만든다

newbieski