데이터
역인덱스라고 하는 방식으로 데이터를 저장한다.
특정 term 이 어떤 doc에 포함되어 있는지 doc의 id를 가르키는 구조란 의미이다...
역인덱스는 책의 맨뒤에 있는 찾아보기라고 설명할 수가 있다.
역인덱스 === 찾아보기

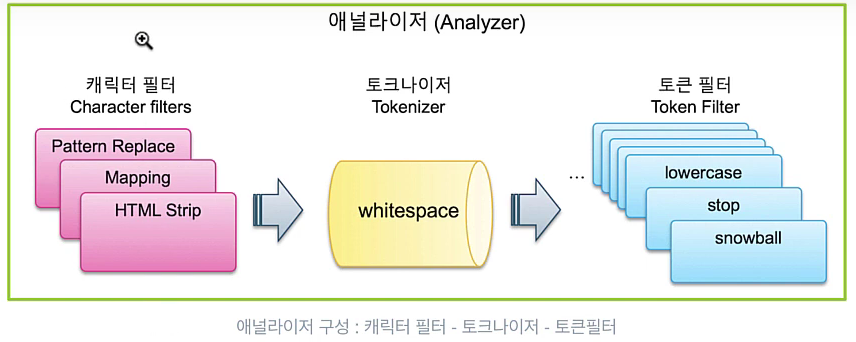
전체 문장에서 특정 문자를 대치하거나 제거
-> 캐릭터 필터
문장에 속한 단어들을 텀 단위로 분리해내는 처리과정
-> 토크나이저
whitespace 토크나이저를 이용해서 공백을 기준으로 텀들을
분리한 결과
분리된 텀들을 가공하는 과정
-> 토큰 필터
1. 대문자를 소문자로 바꾼다거나...
2. 텀들 중에서 가치가 없는 단어들을 제거. 불용어
3. snowball 토큰 필터를 사용해서 토큰을 기본 형태로 변환
jumps, jumping, jumped -> jump 로 변환
4. 동의어 추가. synonym 토큰필터를 사용한다.
GET _analyze
{
"text": "The quick brown fox jumps over the lazy dog",
"tokenizer": "whitespace",
"filter": [
"lowercase",
"stop",
"snowball"
]
}
캐릭터 필터:
1. pattern replace, mapping, html strip
토크나이저
1. standard, letter, whitespace
2. uax Url Email
3. pattern
4. path hierarchy
토큰 필터
1. lowercase, upeercase
2. stop
3. synonym
4. ngram, unique
일반적인 RDB 에서는
테이블 Row들이 있을 때 전체 Row 들 중 있으면 담고 없으면 넘어가고
이런 형식인데 그래서 Row를 모두 읽어야 하기 때문에 읽는 속도가 느리다.
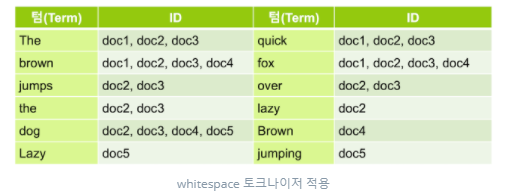
ES 는 역 인덱스(Inverted Index)라는 구조로 저장을 한다.
단어들을 다 쪼개서 저장을 한다. 그 후에 이 단어들을 어떤 장소에 있는지 인덱스를 매긴다. 추출한 단어들은 term 이라고 한다.
책의 맨 뒤에 있는 단어 찾아보기 기능과 비슷 하다고 할 수 있다.
Term ID
The doc1, doc4, doc31
brown doc21, doc6, doc7
jumps doc41, doc7, doc8
the doc21, doc8, doc9
dog doc31, doc41, doc55
....
토큰 필터의 역할은 lowercase, stop, snowball 등등이 존재하는데 lowercaswe 의 역할은 토큰(term)을 소문자로 모두 변환한다.
토큰에서 term 의로서 존재할 가치가 필요 없는 것들이 있다.
jumps, jumping
fast, quick ... 동의어 처리(synonym)
stop을 사용하면 the 이런 존재 가치가 업는 term 들을 제거한다.
snowball 가 형태소 분석을 하는 것들..
GET _analyze
{
"text": "The quick brown fox jumps over the lazy dog",
"tokenizer": "whitespace",
"filter": [
"lowercase",
"stop",
"snowball"
]
}snowball 옵션을 주었다.
my_index2 라는 인덱스를 생성하고 필드의 속성은 message 라는 필드를 생성하고 text 타입으로 snowball 이라는 아날라이저를 적용한다.
Term이 index에 저장 될 때 형태소 분리가 되어서 저장 될 것이다.
PUT my_index2
{
"mappings": {
"properties": {
"message": {
"type": "text",
"analyzer": "snowball"
}
}
}
}PUT my_index2/_doc/1
{
"message": "The quick brown fox jumps over the lazy dog"
}GET my_index2/_search
{
"query": {
"match": {
"message": "jump" // OK
"message": "jumpping" // OK
"message": "jumps" // OK
}
}
}근데 필드의 속성이 snowball 일 때 정확한 Term 으로 검색 하고 싶은 때 match 가 아니라 term 으로 검색을 하면 된다. term 옵션을 사용하면 es 에 term으로 저장되어 있는 텍스트로만 검색이 가능하다. 예를 들어 es에서 jumping 이라느 단어를 jump 라는 텍스트로 term으로 저장했다면 jump로만 검색이 가능하다는 의미이다.
lowercase 는 대문자를 소문자 저장
stop 은 설정된 stop 글자를 텀으로 저장 하지 않는다.
기본으로 생성되는 settings옵션은 아래 그림과 같다.
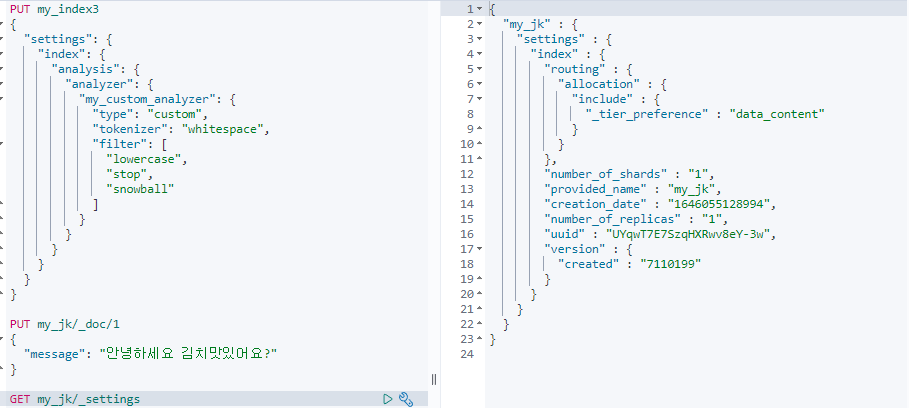
PUT my_index3
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": [
"lowercase",
"stop",
"snowball"
]
}
}
}
}
}
}내가 만든 analyze 를 사용 할 수 있다.
GET my_index3/_analyze
{
"analyzer": "my_custom_analyzer",
"text": [
"The quick brown fox jumps over the lazy dog"
]
}토크나이저, 토큰필터의 경우에도 옵션을 지정하는 경우에는 사용자 정의 토크나이저, 토큰필터로 만들어 추가한다. 다음은 stop 토큰필터에 "brown"을 불용어로 적용한 my_stop_filter 사용자 정의 토큰필터를 생성하고 이것을 my_custom_analyzer에서 사용하도록 설정 한 예제이다.
PUT my_index3
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": [
"lowercase",
"my_stop_filter",
"snowball"
]
}
},
"filter": {
"my_stop_filter": {
"type": "stop",
"stopwords": [
"brown"
]
}
}
}
}
}
}실제 필드에 해당 커스텀한 아날라이저를 적용을 해본다
PUT my_index3
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": [
"lowercase",
"my_stop_filter",
"snowball"
]
}
},
"filter": {
"my_stop_filter": {
"type": "stop",
"stopwords": [
"brown"
]
}
}
}
}
},
"mappings": {
"properties": {
"message": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
}
}GET _analyze
{
"tokenizer": "standard",
"text": "THE quick.brown_FOx jumped! @ 3.5 meters."
}
GET _analyze
{
"tokenizer": "letter",
"text": "THE quick.brown_FOx jumped! @ 3.5 meters."
}
GET _analyze
{
"tokenizer": "whitespace",
"text": "THE quick.brown_FOx jumped! @ 3.5 meters."
}
PUT pat_tokenizer
{
"settings": {
"analysis": {
"tokenizer": {
"my_pat_tokenizer": {
"type": "pattern",
"pattern": "/"
}
}
}
}
}GET pat_tokenizer/_analyze
{
"tokenizer": "my_pat_tokenizer",
"text": "/usr/share/elasticsearch/bin"
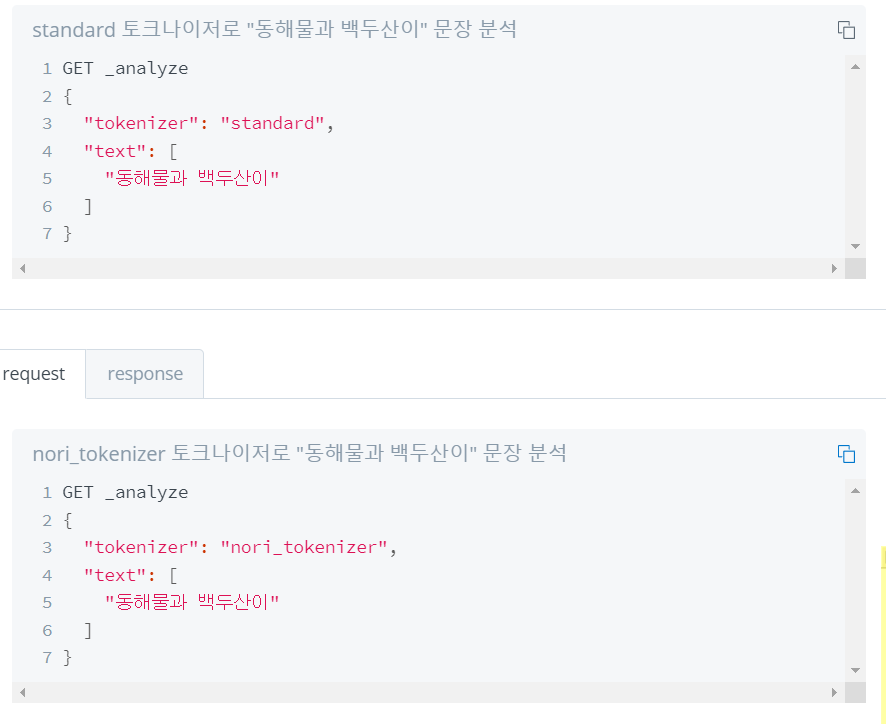
}참조 사이트 : https://esbook.kimjmin.net/06-text-analysis/6.7-stemming/6.7.2-nori
한글은 형태소 분석이 기본적으로 제공되지 않아 별도의 라이브러리를 설치해야 한다.
nori 설치
bin/elasticsearch-plugin install analysis-nori
es 서버를 재시작 해주어야 함. 다운로드 후
// 이대로 저장 한다고 했을 떄 어떤식으로 저장되는지 볼수 있음
GET _analyze
{
"analyzer": "nori",
"text": ["동해물과 백두산이"]
}
// 별도의 사전을 생성한다.
PUT my_nori
{
"settings": {
"analysis": {
"tokenizer": {
"my_nori_tokenizer": {
"type": "nori_tokenizer",
"user_dictionary_rules": [
"해물"
]
}
}
}
}
}

// my_nori 라는 인덱스를 생서하고 토크나이저로 my_nori_tokenizer 라는 토크나이저를 생성
// 타입은 nori_tokenizer 이고 사용자 정의 사전에 해물을 추가해보자.
PUT my_nori
{
"settings": {
"analysis": {
"tokenizer": {
"my_nori_tokenizer": {
"type": "nori_tokenizer",
"user_dictionary_rules": [
"해물"
]
}
}
}
}
}아래와 같은 방식으로 analyze 를 실행을 하면


다음과 같은 방식으로 텀을 저장하게 된다. 이런 방식은 브랜드나 유튜버 이름을 저장을 하게 될 때 유용하게 사용이 가능하다.
PUT my_nori
{
"settings": {
"analysis": {
"tokenizer": {
"nori_none": {
// 복합어를 그대로 저장을 하게 된다. [백두산, 이]
"type": "nori_tokenizer",
"decompound_mode": "none"
},
"nori_discard": {
// [백두, 산, 이] 따로따로 저장을 한다. (백두산으로 검색 시 검색이 안된다...)
"type": "nori_tokenizer",
"decompound_mode": "discard"
},
"nori_mixed": {
// [백두, 백두산, 산, 이] 로 저장을 한다.
"type": "nori_tokenizer",
"decompound_mode": "mixed"
}
}
}
}
}GET _analyze
{
"tokenizer": "nori_tokenizer",
"text": ["차라리 싫다고 말하지 그랬어?"],
"explain": true
}explain: true 로 주면 수사, 명사, 조사 이런 정보들을 볼 수가 있다.
어느 단어가 무엇이고.. 어떤 단어가 무엇이다.. 이런 정보들 말이다....
참조: https://esbook.kimjmin.net/06-text-analysis/6.3-analyzer-1/6.4-custom-analyzer
