구별 데이터로 정리
- 데이터 불러오기
crime_anal_station = pd.read_csv(
'../data/02. crime_in_Seoul_raw.csv', index_col=0, encoding='utf=8') # index_col '구분'을 인덱스 컬럼으로 설정
crime_anal_station.head()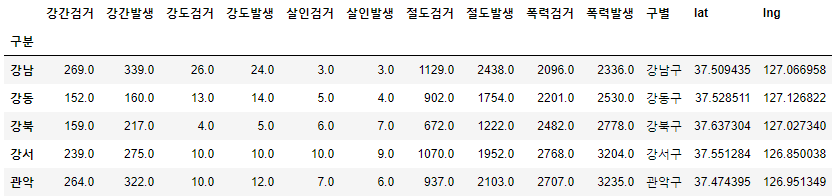
- 새로운 데이터 프레임을 만들면서, index는 구별로, value는 합계로, 위도와 경도는 삭제
crime_anal_gu = pd.pivot_table(crime_anal_station, index='구별', aggfunc=np.sum)
del crime_anal_gu['lat']
crime_anal_gu.drop('lng', axis=1,inplace=True) # 열을 삭제하는 두가지 방법 각각 이용
crime_anal_gu.head()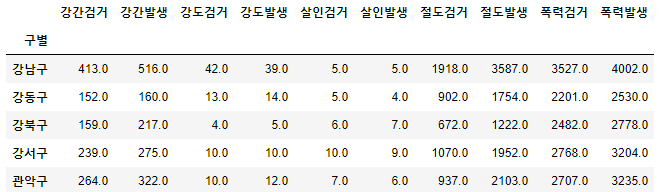
- 검거율 생성
- 하나의 컬럼을 다른 컬럼으로 나누기
crime_anal_gu['강도검거'] / crime_anal_gu['강도발생']
- 다수의 컬럼을 다른 컬럼으로 나누기
crime_anal_gu[['강도검거', '살인검거']].div(crime_anal_gu['강도발생'], axis=0).head()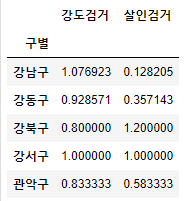
- 다수의 컬럼을 다수의 컬럼으로 각각 나누기
num = ['강간검거', '강도검거', '살인검거', '절도검거', '폭력검거']
den = ['강간발생', '강도발생', '살인발생', '절도발생', '폭력발생']
crime_anal_gu[num].div(crime_anal_gu[den].values).head() # values 꼭 넣기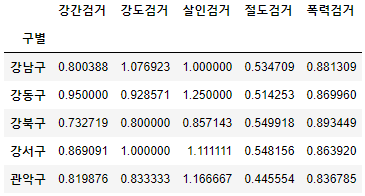
- 검거율 컬럼 생성
target = ['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']
num = ['강간검거', '강도검거', '살인검거', '절도검거', '폭력검거']
den = ['강간발생', '강도발생', '살인발생', '절도발생', '폭력발생']
crime_anal_gu[target] = crime_anal_gu[num].div(crime_anal_gu[den].values)*100
crime_anal_gu.head()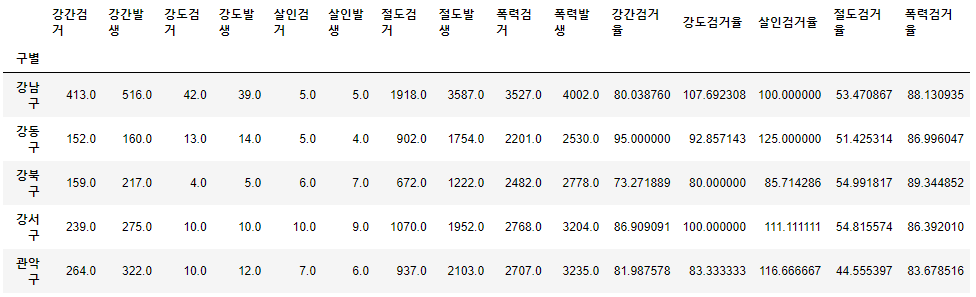
- 컬럼에서 범죄검거량 제거
del crime_anal_gu['강간검거']
del crime_anal_gu['강도검거']
crime_anal_gu.drop(['살인검거', '절도검거', '폭력검거'], axis = 1, inplace = True)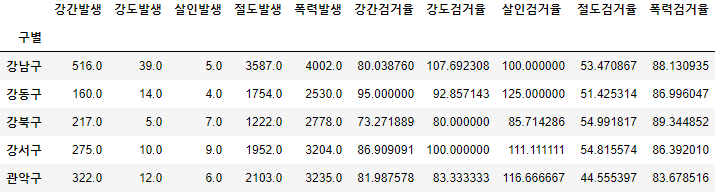
- 100보다 큰 숫자 찾아서 바꾸기
crime_anal_gu[crime_anal_gu[target] > 100] = 100
crime_anal_gu.head()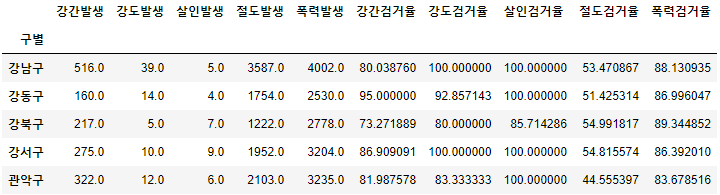
- 컬럼 이름 변경(두가지)
#col = ['강간', '강도', '살인', '절도', '폭력', '강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']
#crime_anal_gu.columns=col
crime_anal_gu.rename(columns={'강간발생':'강간', '강도발생' : '강도', '살인발생' : '살인', '절도발생' : '절도', '폭력발생':'폭력'}
, inplace = True)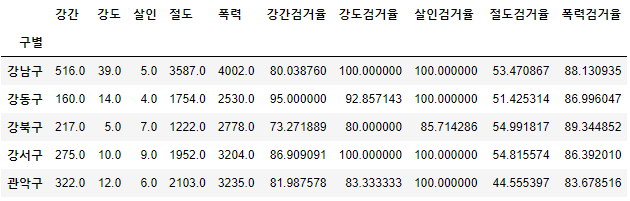
범죄 데이터 정렬을 위한 데이터 정리
- 범죄의 경중에 따라서 수치 차이가 존재
- 범죄에 따라서 스케일 차이를 둘 필요가 있음
- 정규화 : 최대값은 1, 최소값은 0
crime_anal_gu['강도'] / crime_anal_gu['강도'].max()
col = ['살인', '강도', '강간', '절도', '폭력']
crime_anal_norms = crime_anal_gu[col] / crime_anal_gu[col].max()
crime_anal_norms.head()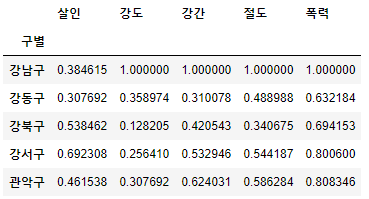
- 검거율 추가
col2 = ['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']
crime_anal_norms[col2] = crime_anal_gu[col2]
crime_anal_norms.head()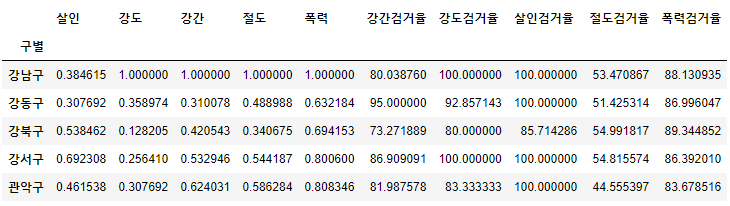
- 구별 CCTV 자료에서 인구수와 CCTV수 추가
result_CCTV = pd.read_csv('../data/01. CCTV_result.csv', index_col='구별', encoding='utf-8')
result_CCTV.head(1)
crime_anal_norms[['인구수', 'CCTV']] = result_CCTV[['인구수', '소계']]
crime_anal_norms.head()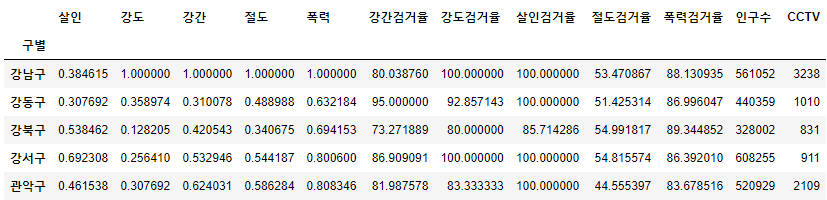
- 정규화된 범죄발생 건수 전체의 평균을 구해서 범죄 컬럼 대표값으로 사용
col = ['강간', '강도', '살인', '절도', '폭력']
crime_anal_norms['범죄'] = np.mean(crime_anal_norms[col], axis=1)
crime_anal_norms.head()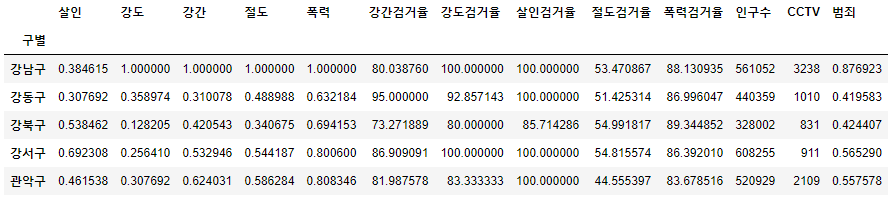
np.means()
numpy 에선 axis가 행이 1 열이 0
pandas 에선 axis가 행이 0, 열이 1
- 검거율의 평균을 구해서 검거 칼럼의 대표값으로 사용
col = ['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']
crime_anal_norms['검거'] = np.mean(crime_anal_norms[col], axis=1) # axis=1 행을 따라서 연산하는 옵션
crime_anal_norms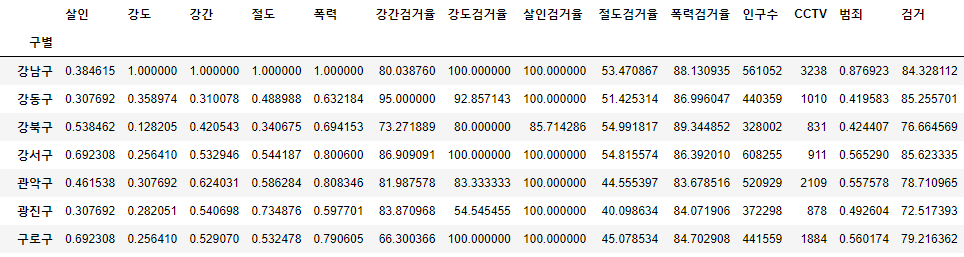

개발도상인 냄비짱