
데이터 합치기
-
pandas에서 데이터 프레임을 병합하는 방법
pd.concat()
pd.merge()
pd.join() -
딕셔너리 안의 리스트 형태 -> key 값에 해당하는 열의 value가 리스트로 기입
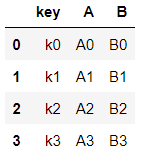
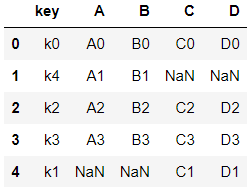
left = pd.DataFrame({
"key" : ["k0", "k4", "k2", "k3"],
"A" : ["A0", "A1", "A2", "A3"],
"B" : ["B0", "B1", "B2", "B3"]
})
left
- 리스트 안의 딕셔너리 형태 -> key 값에 해당하는 value가 열 순서대로 하나씩 기입
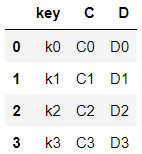
right = pd.DataFrame([
{"key":"k0", "C" : "C0", "D" : "D0"},
{"key":"k1", "C" : "C1", "D" : "D1"},
{"key":"k2", "C" : "C2", "D" : "D2"},
{"key":"k3", "C" : "C3", "D" : "D3"},
])
right
pd.merge()
-
두 데이터 프레임에서 컬럼이나 인덱스를 기준으로 잡고 병합하는 방법
-
기준이 되는 컬럼이나 인덱스를 키값이라고 함
-
기준이 되는 키값은 두 데이터 프레임에 모두 포함되어 있어야함.
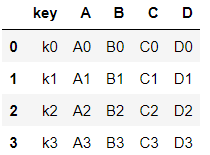
pd.merge(left, right, on="key")
두 데이터 프레임의 공통된 값(key값)을 기준으로 공통된 것만 병합
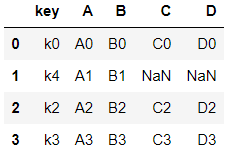
pd.merge(left, right, how="left", on="key")
두 데이터의 프레임을 공통된 key값 기준으로 합치되 left의 내용은 모두 출력
pd.merge(left, right, how="outer", on="key")
두 데이터 프레임을공통된 key값 기준으로 합치되 left와 right의 내용은 모두 출력
*inner는 교집합으로 default 값인덱스 변경
-
set_index()
-
선택한 컬럼을 데이터 프레임의 인덱스로 지정
data_result.set_index("구별", inplace=True)
data_result.head()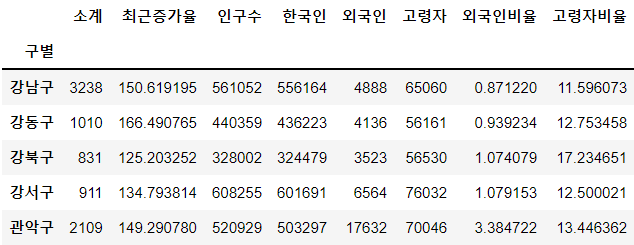
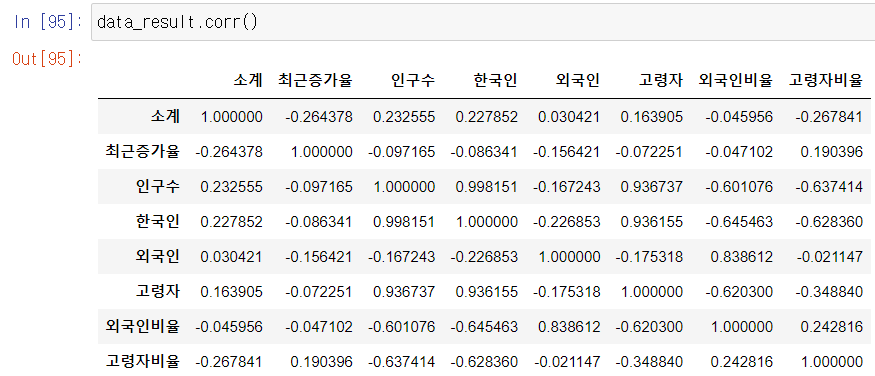
상관계수
- corr()
- correlation의 약자
- 상관계수가 0.2 이상인 데이터를 비교
- 모든 데이터 타입이 연산가능해야 사용가능

개발도상인 냄비짱