리스트는 선형적인 자료구조로 데이터를 일렬로 늘여 놓은 형태를 가진 자료구조를 말합니다. 일렬로 늘어놓았기 때문에 데이터간의 순서가 있다는 점도 리스트의 특징입니다.
리스트에서 중요한 연산은 데이터 삽입, 삭제, 리스트 탐색이 중요합니다.
리스트는 크게 array list linked list로 나눌 수 있고 linked list는 데이터의 연결 방식에 따라 single linked list double linked list 로 나눌 수 있습니다.
배열
ArrayList는 배열 기반이기 때문에 배열과 동일한 방식으로 인덱스를 사용하게 됩니다. 그리고 인덱스를 통한 데이터 접근은 random access 방식이기 때문에 리스트의 크기에 관계 없이 항상 동일한 시간을 소요해서 데이터에 접근할 수 있습니다.
arrayList는 물리적인 컴퓨터의 메모리 공간에서도 연속적인 공간을 사용하기 때문에 컴퓨터가 연산하기 쉬운 구조를 사용하고 있습니다. 반면 LinkedList는 데이터를 논리적 구조로 연결 시켜서 마치 연속된 형태의 데이터처럼 쓸 수 있도록 되어 있지만 실제 물리적인 컴퓨터 메모리 공간에서는 비연속적 공간을 사용하기 때문에 실제 소요되는 시간이 더 길어집니다.
연결 리스트(Linked List)
linked리스트는 Node라는 객체로 구성되어있습니다. 이 Node는 데이터를 저장할 수 있는 필드와 다음 노드를 가르킬수있는 Nextpointer 필드를 가지게 되고 이 노드들이 모두 연결된 형태를 linked list 라고 합니다.
여기서 가장 앞에 위치한 노드를 Head 가장 끝에 위치한 노드를 Tail이라고 합니다. Tail은 다음에 가르킬 노드가 없기 때문에 tail의 next pointer는 null 값을 가집니다.
검색
linked list는 array와 다르게 인덱스를 통한 랜덤 액세스가 불가합니다. 자신을 가리키고 있는 넥스트 포인터만을 통해서 접근할 수 있기 때문에 N개의 노드를 가지고 있는 linkedlist의 시간복잡도는 O(N) 입니다. 왜냐면 우리가 찾아가고자 하는 위치를 Head에서부터 Tail까지 순회해서 데이터를 찾아야하기 떄문이죠.
추가
추가 기능은 디폴트로 Tail 노드 다음에 붙입니다. 마찬가지로 앞에서부터 하나씩 찾아가야하고 끝 노드에서 null을 가르키고 있는 포인터에 추가하고자하는 노드 데이터를 넣어주게 됩니다. 마찬가지로 O(N)의 시간복잡도를 가지게 됩니다.
삽입
삽입은 제일 끝이 아니라 중간에 넣는 과정입니다. Array와는 다르게 데이터를 다 밀어줄 필요는 없습니다. 포인터만 바꿔주면 바꿀 수 있겠지만 마찬가지로 찾아가는 과정에서 시간복잡도가 O(N)이 됩니다. 넣고자하는 데이터의 위치를 기준으로 이전 노드의 포인터가 데이터를 가리키게 하고 다음 노드를 현재 데이터가 가지게 해주면 삽입이 이루어집니다. 만약 삽입이 헤드에 이루어지도록 해야한다면 헤더의 포인터만 설정해주면 되기 때문에 어레이 데이터보다 간단하게 작업할 수 있습니다.
삭제
삭제를 위해 노드를 찾아가는 시간복잡도 또한 마찬가지로 O(N)입니다. 다만, 어레이리스트와는 다르게 모든 데이터를 끌어올 필요없이 삭제하고자 하는 노드의 이전 노드의 포인터를 다음 노드로 바꿔주기만 하면 데이터를 삭제해줄 수 있습니다.
LinkedList같은 경우는 배열의 복사나 재할당 없이 데이터 추가가 가능하며 공간이 유연합니다. 하지만 데이터 접근에 대한 시간이 늘어납니다.
↓ LinkedList vs ArrayList
| LinkdedList | Array | |
|---|---|---|
| 추가 | O(N) | O(1),O(N) |
| 삽입 | O(N) | O(N) |
| 삭제 | O(1) | O(N) |
| 검색 | O(N) | O(1) |
더미 노드
LinkedList가 존재할 때 헤드부터 데이터를 넣는 것이 아니라 빈 상태로 두는 것입니다. 리스트에 아무것도 넣지 않더라도 헤드노드는 이미 존재하며 이 헤드에는 데이터를 넣을 수 없습니다. 이렇게 하면 코드의 구현에 있어서 간결해지는 장점이 있습니다. (이렇게 하지 않으면 케이스별로 처리해줘야하기 때문에 코드가 길어지겠죠?)
이중 연결 리스트(Double Linked List)
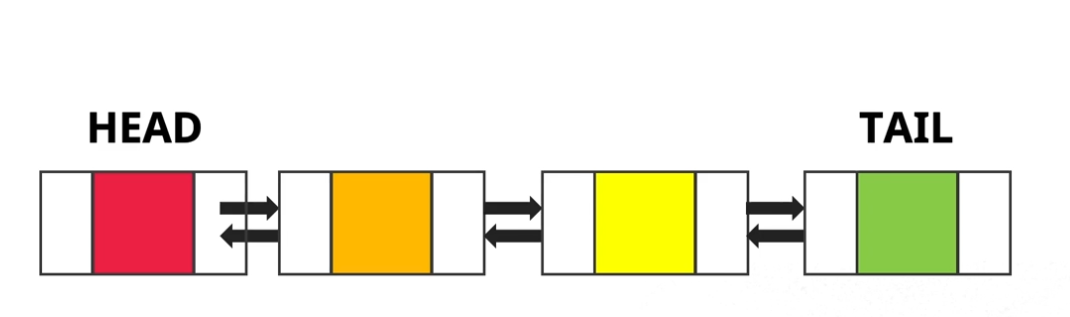
linked list에서는 HEAD 노드를 가지고 하나씩 찾아나가는 구조였습니다. 하지만 double linked list는 HEAD 노드와 TAIL 노드를 각각 따로 가지게 되며 next pointer와 prev pointer를 가지게 됩니다. prev 포인터를 하나 가진다는것은 그만큼의 공간을 가진다는 의미입니다. Double Linked List를 사용하는 것은 공간을 사용함에도 불구하고 장점이 있습니다. 어떤 장점이 있는지 알아보도록 하겠습니다.
우선 Double Linked List에서도 더미노드를 사용합니다. 그래서 리스트가 초기화가 되고 아무 데이터가 들어오지 않은 상태라면 헤드 더미와 테일 더미 노드를 각각 하나씩 가집니다. 이 때 HEAD의 next는 TAIL을, TAIL의 prev는 HEAD를 가리키게 됩니다.
리스트에 데이터가 들어오면 더미노드인 헤드와 테일 노드 사이에 데이터 노드가 들어오게 됩니다.
추가
테일 노드의 이전 노드가 가장 마지막 데이터 노드이기 때문에 테일 더미 노드의 바로 앞 노드에 삽입을 해주면 됩니다. 다시 말해서 데이터가 몇 개가 있든 테일 노드를 통해서 한 번에 찾아낼 수 있기 때문에 시간복잡도는 O(1)을 가집니다.
인덱스 검색
노드 연결을 타고 들어가는 방식으로 접근을 하게 되는데 LinkedList와는 다르게 TAIL을 이용해서 prev 노드로 접근해서 데이터를 가져올 수 있게 됩니다. 다시 말해서 N개의 데이터가 들어있다면 O(N)으로 시간 복잡도를 가지지만 실제 연산 소요시간은 절반 정도로 짧아집니다.
인덱스 삽입
인덱스를 통한 삽입은 먼저 삽입할 위치를 찾아가야합니다. 인덱스 검색은 헤드에서 가까우면 헤드에서부터, 테일에서 가까우면 테일에서 검색을 시작한다고 했습니다. 동일한 방식으로 인덱스의 위치를 찾아 들어가서 데이터를 삽입하고자 하는 위치에 new Node()로 노드를 생성하여 curr 노드를 next로 가지며 curr 노드는 new 노드를 prev로 가지면 삽입이 이루어집니다. 그 다음 현재 삽입할 위치의 노드 앞에 있는 노드, 즉 prev 노드의 next 노드로 현재 생성한 new 노드를 설정하고 new 노드의 prev는 prev 노드를 가리키게 해주면 됩니다.
인덱스 삭제
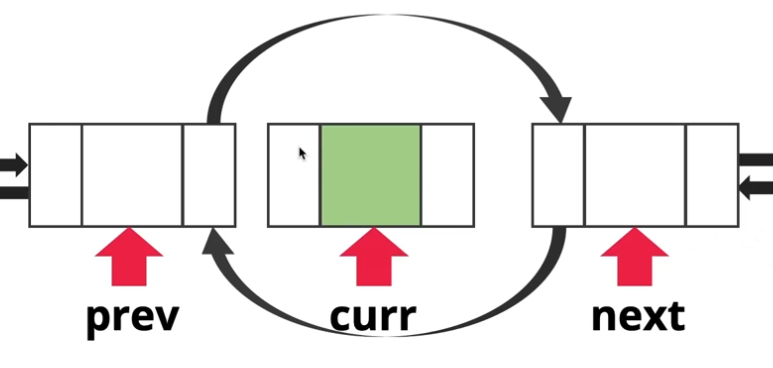
인덱스 검색 과정은 동일합니다. 이 떄 우리가 삭제할 cur 노드를 기준으로 prev 노드와 next 노드를 연결해주는 작업을 해주면 됩니다. prev 노드의 next를 next 노드에 연결을 해주고 next 노드의 prev를 prev 노드에 연결을 해준 후 curr 노드에 연결된 prev와 next를 모두 끊어주면 데이터가 삭제됩니다.
