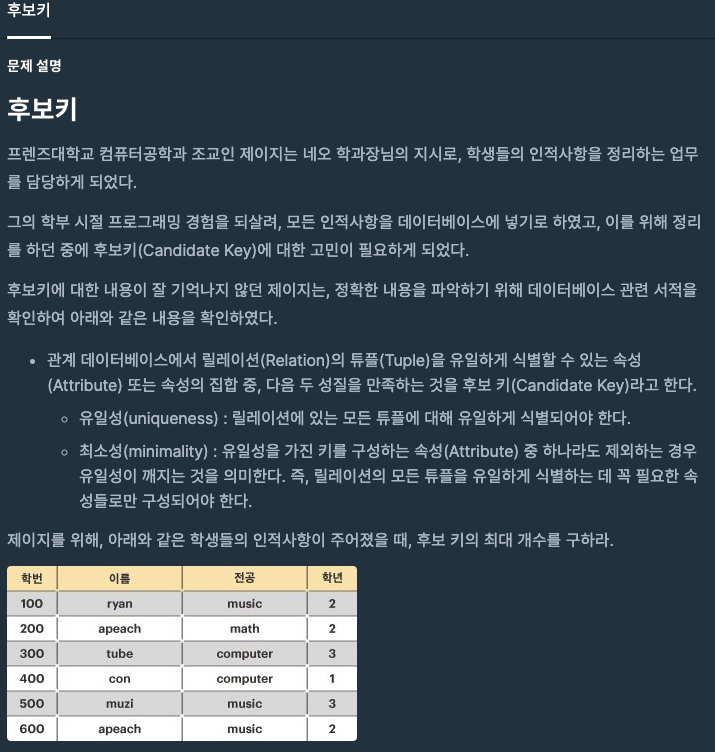
후보키
코드
[ 나의 풀이 ]
#include <string> #include <vector> #include <map> #include <iostream> #include <algorithm> using namespace std; int solution(vector<vector<string>> relation) { int answer = 0; int m = relation.size(); int n = relation[0].size(); vector<int> candidate; vector<vector<int>> all((1<<n)); /* 가능한 모든 경우의 수 구하기 */ for(int i=1;i<(1<<n);i++){ for(int j=0;j<n;j++){ // 이렇게 하면 4번동안 각 자리수의 비트를 추출 가능 int t = 1 & (i >> j); if(t == 1) all[i].push_back(j); } } /* 모든경우의수 반복문 돌리기 */ for(int i=0;i<all.size();i++){ map<string,int> temp; int flag=0; vector<int> del; for(int k=0;k<m;k++){ string str = ""; for(int j=0;j<all[i].size();j++) { int idx = all[i][j]; auto it = find(del.begin(), del.end(), idx); if(it == del.end()) del.push_back(idx); str += " " + relation[k][idx]; } str.erase(0,1); if(temp[str]) { flag = 1; break; }else temp[str]++; } if(flag == 0) { /* 최소성 검사 */ bool check = true; for(int q=0;q<candidate.size();q++){ if((candidate[q] & i) == candidate[q]){ check=false; break; } } if(check) candidate.push_back(i); } } return candidate.size(); }
- 모든 경우의수를 처리하는 방법을 못찾아서 힌트를 참조함
- key point!
1) 모든 cloumn의 경우의수를 구해서 정해놓아야 한다
:1 << Col의 수로 모든 경우의 수의 개수가 나온다
ex) column이 4개일 때1<<4=10000이므로,
0000 ~ 1111까지!!
2) 현재 후보키로 선정된 column이 모두 포함된 다른 경우의수를 배제해야함
--> 최소성을 만족시키기 위해서!
3) 유일성을 만족시키기 위해 Map을 사용함
[ 최적 풀이 ]
#include <bits/stdc++.h> using namespace std; bool possi(vector<int> &vec,int now){ for(int i=0;i<vec.size();i++) /* 여기가 핵심 ! - 앞에 후보키로 나온 값들과 & 연산 했을 때 후보키가 나온다는 것은 후보키로 나온 비트가 모두 포함되어 있다는 뜻이니까 return false! */ if((vec[i]&now)==vec[i])return false; return true; } int solution(vector<vector<string>> relation) { int n=relation.size(); int m=relation[0].size(); vector<int> ans; /* 모든 경우의수에 대해 */ for(int i=1;i<(1<<m);i++){ set<string> s; for(int j=0;j<n;j++){ string now=""; for(int k=0;k<m;k++){ /* 해당 비트가 1인 경우에만 문자열 추가 */ if(i&(1<<k))now+=relation[j][k]; } /* 빈 값이면 값이 들어가지 않는다 --> 사이즈가 커지지 않는다. 0000처럼 모두 0이 아닌 경우를 빼고는 항상 값이 들어갈 것임 */ s.insert(now); } /* 유일성을 처리하는 코드는 따로 없는데, 값이 증가하며 비트가 순서대로 커지기 때문에 해당 column이 포함된 경우가 차례로 등장하기에 안해줘도 되는것으로 보임 */ /* s.size()가 n이라는 것 모두 0일 경우를 제외한 것, possi는 미리 나온 후보키가 포함된 경우인지 아닌지 검사해서 최소성을 만족시키는 것! */ if(s.size()==n && possi(ans,i)) ans.push_back(i); } return ans.size(); }
- 유일성 검사를 따로 해주지 않음
--> 값이 증가하며 비트가 순서대로 커지기 때문에 해당 column이 포함된 경우가 차례로 등장해서 안해줘도 되는것으로 보임
- 최소성 검사
(후보키)A & (현재 검사하는 후보키)B = (후보키)A
: 앞서 나온 후보키 A의 비트와 현재 검사하는 키 B를 &연산 했을 때 A가 나오면
적어도 A의 비트는 포함되어 있는 것이기 때문에 후보키가 될수 없음을 알 수 있음!

Developer & PhotoGrapher