
- 반드시 해당 지식들이 있어야 WebFlux를 사용할 수 있는 것은 아닙니다.
- 하지만, 결국 Java의 thread 관련 기술들을 알아야 깊은 WebFlux의 필요성과 이해를 할 수 있다고 생각해서 추가하게되었습니다.
Java의 Concurrent ?
- Java에서 지원하는 Concurrent 프로그래밍
- 멀티 프로세싱(
process) =>ProcessBuilder- 멀티 쓰레딩(
thread) =>Thread,Runnable,Callable,Executor등
- 본 글에서는 Java의
멀티 쓰레딩 관련 개념들을 살펴본다
Executor와 구현체들
[ Executor ]
[ 개념 ]
- Java 5부터 Java Concurrency api를 뒷받침하기 위해 제공된 인터페이스(interface)
- 비동기적으로 호출을 실행하는 메서드를 제공
- 하위 구현체와 인터페이스들을 통해 실제 사용
[ 구조 ]
- 수행할 작업인 Runnable 을 받아서 실행
package java.util.concurrent.Executor; public interface Executor { void excute(Runnable command); }
[ Executor 인터페이스와 하위 관계 ]
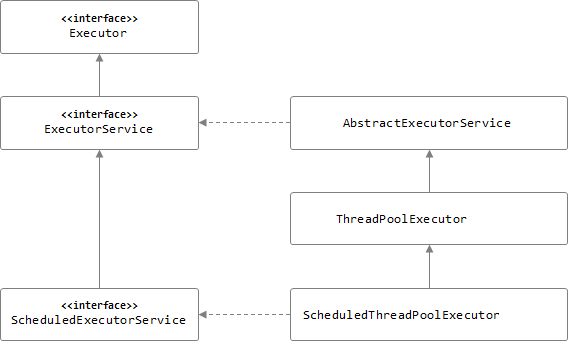
[ ExecutorService ]
[ 개념 ]
- Executor 인터페이스를 확장해서 라이프 사이클(시작 / 중지 / 종료)을 관리할 수 있는 기능을 정의한 인터페이스(interface)
- Thread의 라이프사이클이나 발생할 수 있는 low level의 고려사항을 개발자가 신경쓰지 않게 해준다
- ExecutorService에 Task(작업)을 지정해주면, 가진 ThreadPool을 이용해서 Task를 실행
- 만약, Thread Poool의 Thread 수 보다 Task가 많다면, Task는 큐(Queue)에서 대기하게 된다
[ 구성 ]
/* 시작 관련 메소드 */ /* 결과값을 리턴하는 작업을 추가한다 */ < T > Future< T >submit(Callable< T > task) /* 결과값이 없는 작업을 추가한다 */ Future<?> submit(Runnable task) /* 새로운 작업을 추가한다. result는 작업이 성공적으로 수행될 때 사용될 리턴 값을 의미한다. */ < T > Future< T > submit(Runnable task, T result) /* 주어진 작업을 모두 실행한다. 각 실행 결과값을 구할 수 있는 Future의 list 를 리턴한다. */ < T > List<Future< T > > invokeAll(Collections<? extends Callable< T > > tasks) /* 위의 invokeAll() 과 동일하다. 지정한 시간 동안 완료되지 못한 작업은 취소되는 차이점이 있다. */ < T > List<Future< T > > invokeAll(Collections<? extends Callable< T > > tasks , long timeout, TimeUnit unit) /* 작업을 수행하고, 작업 결과 중 성공적으로 완료된 것의 결과를 리턴한다. 정상적으로 수행된 결과가 발생하거나 예외가 발생하는 경우 나머지 완료되지 않은 작업은 취소된다. */ < T > invokeAny(Collection<? extends Callable< T > > tasks) /* invokeAny() 와 동일하다. 지정한 시간 동안만 대기한다는 차이점이 있다. */ T invokeAny(Collections<? extends Callable< T > > tasks, long timeout, TimeUnit unit) /* 종료 관련 메소드 */ /* 이미 Executor 에 전달된 작업은 실행되지만, 새로운 작업은 받지 않습니다 */ void shutdown() /* 현재 실행되고 있는 작업을 모두 중지 시키고, 현재 대기 하고 있는 작업을 멈추게 합니다. 그리고 현재 실행되기 위해 대기중인 작업 목록 리스트를 반환합니다 */ List< Runnable > shutdownNow() /* 확인 관련 메소드 */ /* Executor 가 셧다운 되었는지의 여부를 반환합니다. */ boolean isShutdown() /* shutdown() 실행 후, 모든 작업이 종료되었는지 여부를 확인한다. */ boolean isTerminated() /* 대기 관련 메소드*/ /* 셧다운을 실행한 뒤, 지정한 시간 동안 모든 작업이 종료될 때 까지 대기한다. 지정한 시간 이내에서 실행중인 모든 작업이 종료되면 true를 리턴하고, 여전히 실행중인 작업이 남아 있다면 false를 리턴한다. */ boolean awaitTermination(long timeout, TimeUnit unit)
[ ThreadPoolExecutor ]
[ 개념 ]
- ExecutorService 인터페이스의 구현체
- 스레드 풀의 종류와 다양한 설정을 적용하는 객체
- 직접 값을 바인딩 할 수 있지만, 일반적으로
Executors라는 클래스를 통해팩토리 메소드 패턴으로 구현해서 많이 사용한다고 한다
(ref: https://docs.oracle.com/javase/7/docs/api/java/util/concurrent/ThreadPoolExecutor.html)
- Spring에서는
ThreadPoolExecutor를상속받은ThreadPoolTaskExecutor를 제공해서 더 편리하게 사용 가능
[ 핵심 파라미터 ]
- corePoolSize
최초 생성되는 쓰레드 사이즈corePoolSize가 될 때 까지는 계속 쓰레드를 유지- 계속 유지가 되기 때문에, 적절한 값을 찾아서 적용하는 것이 중요
- maximumPoolSize
- 해당 풀에
최대로 유지할 수 있는 개수corePoolSize = maximumPoolsize이면fixed-size thread pool과 동일
- keepAliveTime
corePoolSize를 넘어maximumPoolSize까지 증가하는 과정에서KeepAliveTime동안idle상태에 있으면 다시corePoolSize로 개수를 줄인다- unit
KeepAliveTime의 시간 단위
- workQueue
corePoolSize보다 많아졌을 경우,Task가 쌓이며 기다리는BlockingQueue의work방식을 설정- 종류
SynchronousQueue: task를 큐에 유지하지 않고, 바로 스레드로 넘기는 방식의 큐LinkedBlockingQueue: 크기 제한이 없는 큐ArrayBlockingQueue: 크기 제한이 있는 큐
[ 생성 ]
/* 직접 생성 */ final int corePoolSize = 3; final int maximumPoolSize = 5; final int queueCapacity = 3; final ThreadPoolExecutor executor = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, 1L, TimeUnit.MINUTES, new ArrayBlockingQueue<>(queueCapacity)); /* Executors를 이용한 생성 */ ExecutorService executorService = Executors.newSingleThreadExecutor() ExecutorService executorService = Executors.newFixedThreadPool(4) ExecutorService executorService = Executors.newCachedThreadPool() ExecutorService executorService = Executors.newWorkStealingPool(10) ...
[ Executors ]
Executors.newSingleThreadExecutor()
- 단일 쓰레드를 가지는 풀을 생성
Executors.newFixedThreadPool(int Threads)
Threads갯수 만큼 고정된 쓰레드 풀을 생성
Executors.newCachedThreadPool()
- 필요할 때, 필요한 만큼의 쓰레드 풀을 생성 (계속 증가 가능 => 위험성 존재)
- 이미 생성된 쓰레드를 재활용할 수 있기 때문에 성능상의 이점이 있을 수 있음
Executors.newWorkStealingPool(int)
- 시스템에 가용 가능한 만큼 쓰레드를 활용하는 풀을 생성
Executors.newWorkStealingPool(int parallelism)
- Java8 에서 도입된 Thread Pool
- 지정된
parallelism을 지원할 만큼 충분한 Thread를 유지하고, 여러 Queue를 사용하여 경합을 줄임- Thread를 동적으로 늘리고 줄인다
- 작업이 실행되는 순서를 보장하지 않음
[ 그 외 ]
ScheduledExecutorService
- 지정한 스케쥴에 따라 작업을 수행할 수 있는 기능이 추가된
ExecutorService인터페이스
ScheduledThreadPoolExecutor
ScheduledExecutorService인터페이스를 구현한 구현체(클래스)ThreadPoolExecutor처럼스레드 풀을 구성- 자세한 내용 참조 : http://java.sun.com/javase/6/docs/api/java/util/concurrent/ScheduledThreadPoolExecutor.html
Runnable / Callable
[ Runnable ]
[ 개념 ]
- 다중 스레드 작업을 나타내기 위해 제공되는 핵심 인터페이스
void반환 타입을 가진다
=> 실행 후 결과를 받지 X
[ 구성 ]
public interface Runnable { public void run(); }
[ Callable ]
[ 개념 ]
- Runnable과 동일하게, 다중 스레드 작업을 나타내기 위해 제공되는 핵심 인터페이스
<V>반환 타입 (특정 객체 리턴)
=> 실행 후 결과를 객체로 받음
=> 기존 Runnable에서는 실행 결과를 받기 위해공용 메모리나파이프와 같은 것들이 필요했다
[ 구성 ]
public Interface Callable<V> { V call() throws Exception }
[ 특징 ]
- 최상단 인터페이스인 Executor에는 Runnable만 매개변수로 가진다
- 하지만, Executor를 상속받은 ExecutorService에 Callable을 변수로 가지는 메소드들이 정의
=>submit()/invokeAll()/invokeAny()등
Future 타입
[ Future ]
[ 설명 ]
- 비동기적인 Task의 현재 상태를 조회하거나 결과를 가져오기 위한 객체
- Runnable / Callable의 상태를 조회하거나 결과를 확인하기 위해 사용
- FutureTask라는 구현체를 가진다
- 시간이 걸릴 수 있는 작업을 Future 내부에 작성하고,
호출자 스레드가 결과를 기다리는 동안 다른 유용한 작업을 할 수 있음
=> 실행을 맞기고 미래 시점에 결과를 얻는 것으로 이해 가능
[ 구성 ]
public interface Future<V> { /* Blocking Call을 통해 작업의 처리 결과를 기다리는 작업 */ V get() throws InterruptedException, ExecutionException; V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException; /* 작업의 cancel 여부를 true / false로 반환 */ boolean isCancelled(); /* 작업의 완료 여부를 true / false로 반환 */ boolean isDone(); /* 파라미터 : true => 작업 interupt 후 종료 파라미터 : false => 작업이 끝날 때 까지 대기 후 종료 */ boolean cancel(boolean mayInterruptIfRunning) }
[ 한계 ]
- 복잡한 로직 구현 불가
- isDone() / isCanceled처럼 기본 사항들만 체크할 수 있기 때문에 복잡한 로직 구현에 한계가 존재
- get() 뒤에만 콜백을 지정할 수 있었다
- get()을 통한 강제 Blocking 발생
- 결과가 보장되지 않는 상태라서 콜백을 Future를 정의하며 등록할 수 없었다
- 여러 Future 조합 불가능
- 예외 처리용 API를 제공하지 않음
[ CompletableFuture ]
[ 설명 ]
- ListenableFuture와 차이점
- 작업이 완료될 때 콜백을 등록하면서, 동시에 완료를 원하는 스레드에서 할 수 있다는 것이 차이점이라고 한다
(ref : https://stackoverflow.com/questions/38744943/listenablefuture-vs-completablefuture)
[ 비동기 작업 실행 ]
- 특징
- 직접 쓰레드를 생성하지 않는다
--> 내부적으로ForkJoinPool.commonPool()의 쓰레드를 수행해서비동기 작업 수행
- runAsync(
Runnable)
반환(return)값이없는 경우
- supplyAsync(
Supplier)
반환(return)값이있는 경우
[ 콜백 제공 ]
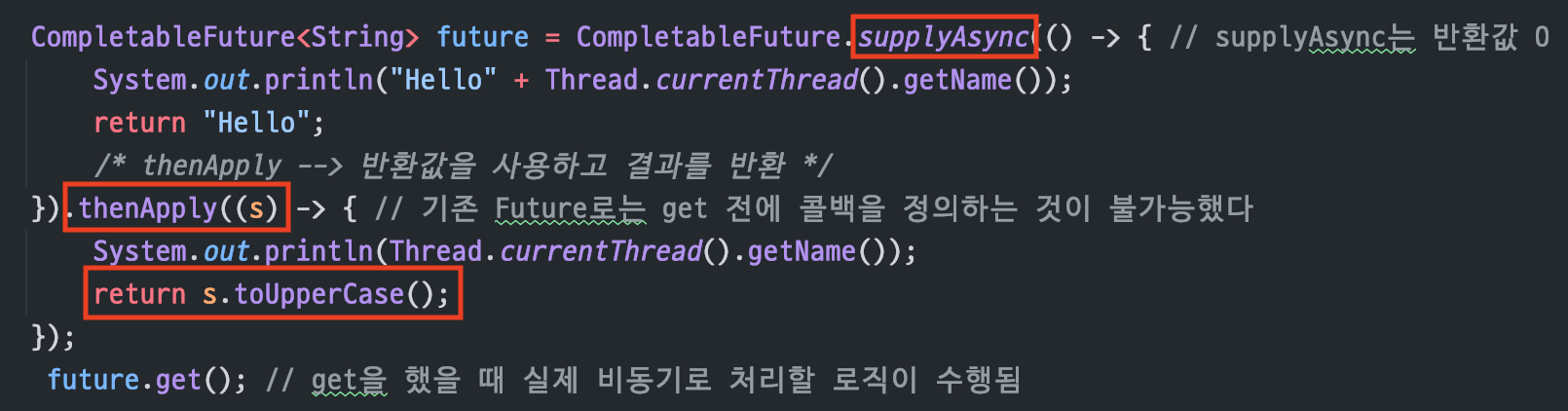
thenApply(
Function)
비동기 로직이 수행된 후결과값을 받고,값을 반환(return)한다Function이니까입력값 1개/출력값 1개
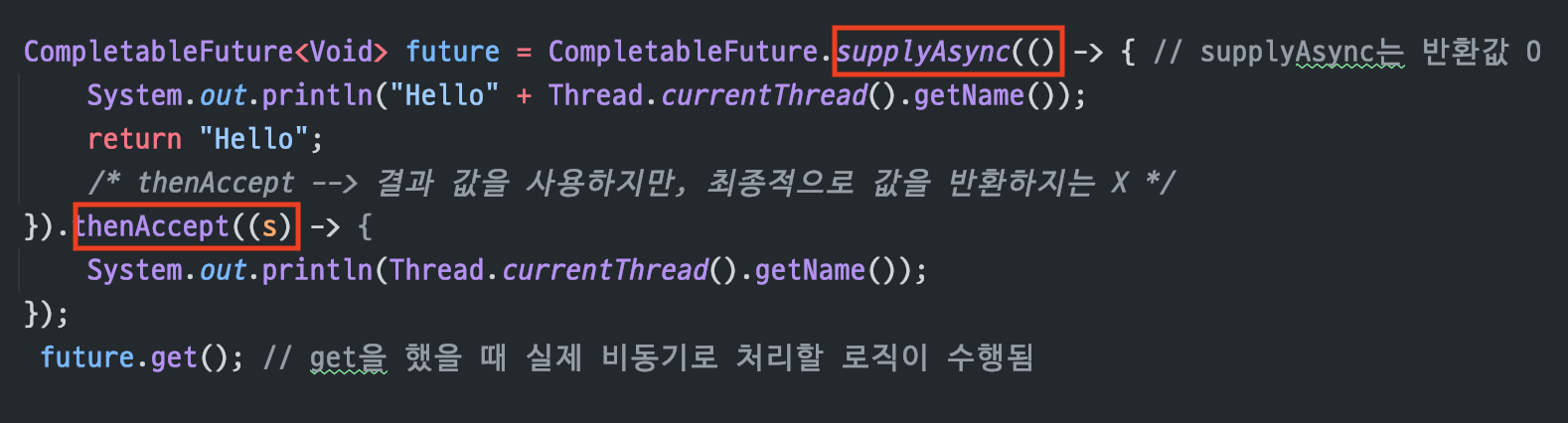
thenAccept(
Consumer)
비동기 로직이 수행된 후결과값을 받고,값을 반환(return)하지 않는다Consumer니까입력값 1개/출력값 0개
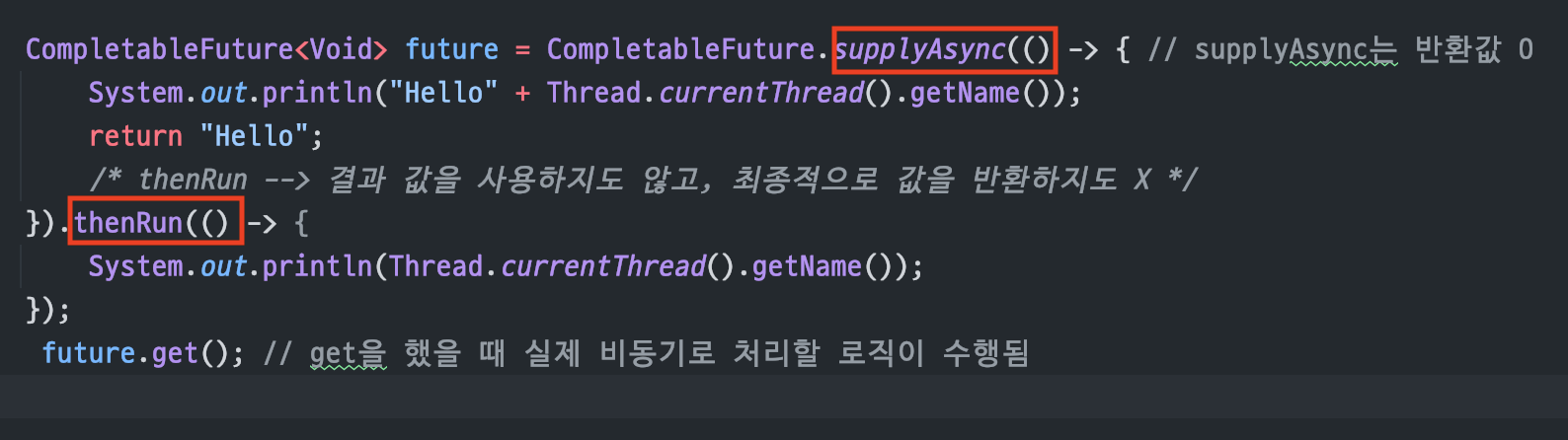
thenRun(
Runnable)
비동기 로직이 수행된 후결과값을 받지 않고,값을 반환(return)하지도 않는다Runnable이니까입력값 0개/출력값 0개
[ 조합하기 ]
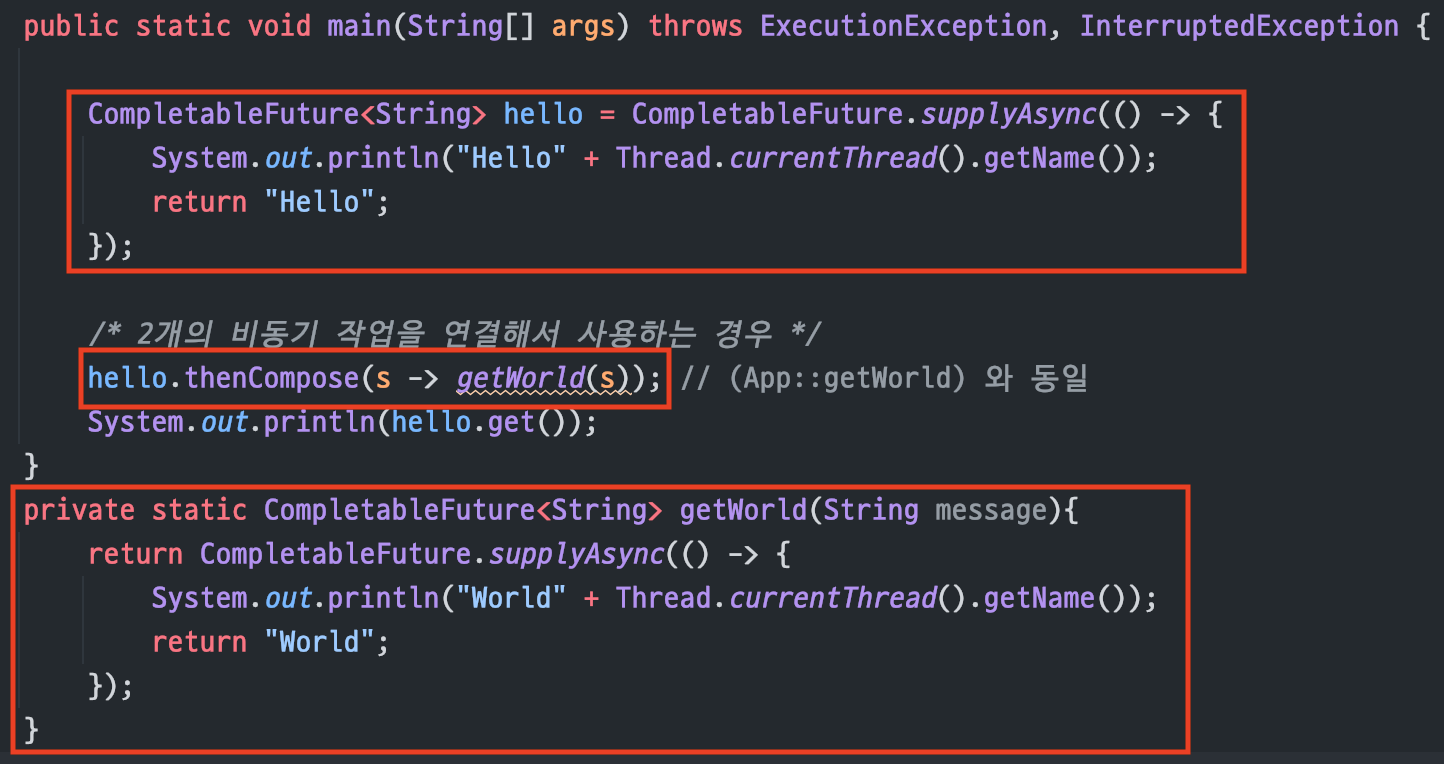
thenCompose()
연관성이 있는 2개의 작업을처리할 때 사용해당 작업을 처리한 후결과를 받아서다음 비동기 작업을 처리할 때 사용
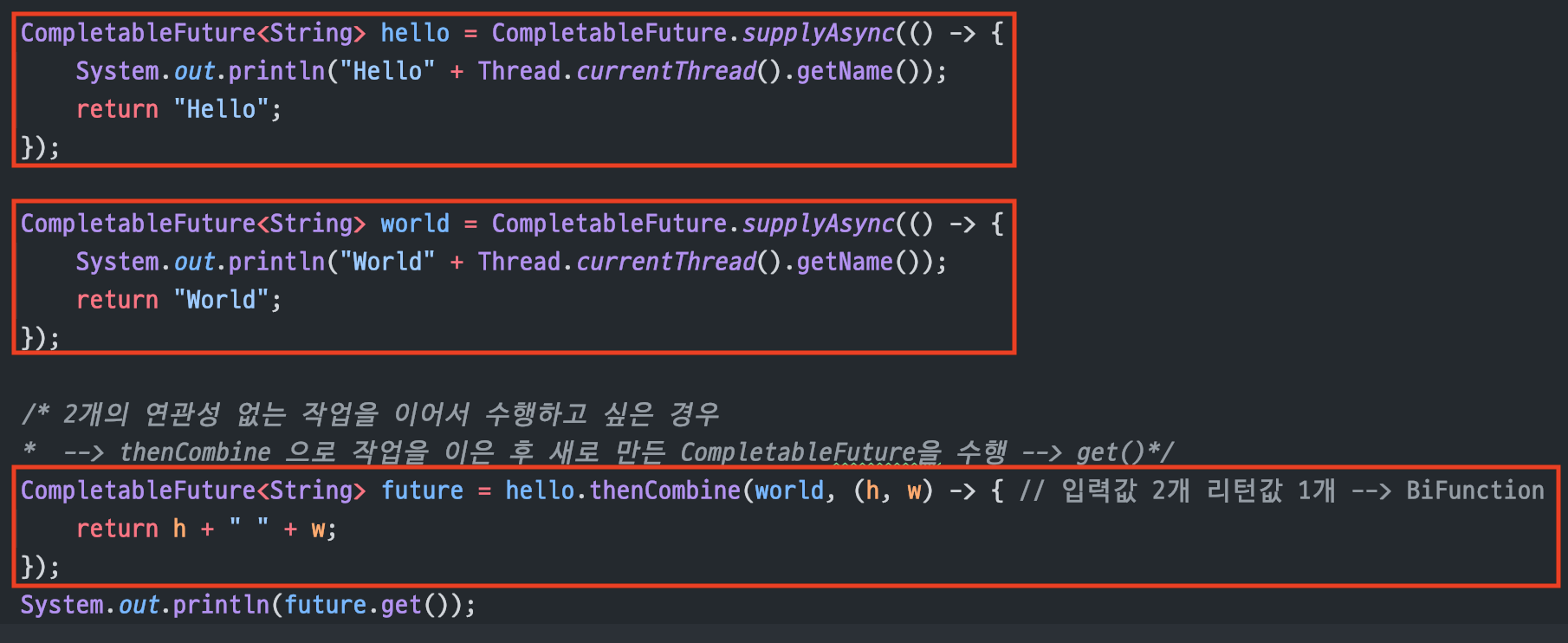
thenCombine()
연관성이 없는 2개의 작업을처리할 때 사용
allOf()
연관성이 없는 다수의 작업을수행할 때 사용각 작업의 반환(return)값이같다고 보장할 수 없기 때문에반환값을 가지지 않는다만약 모든 작업의 결과를ArrayList로 저장하려면 아래처럼결과 값에 접근해서 만들어야 한다
(에러처리의 복잡함때문에get()대신join()사용)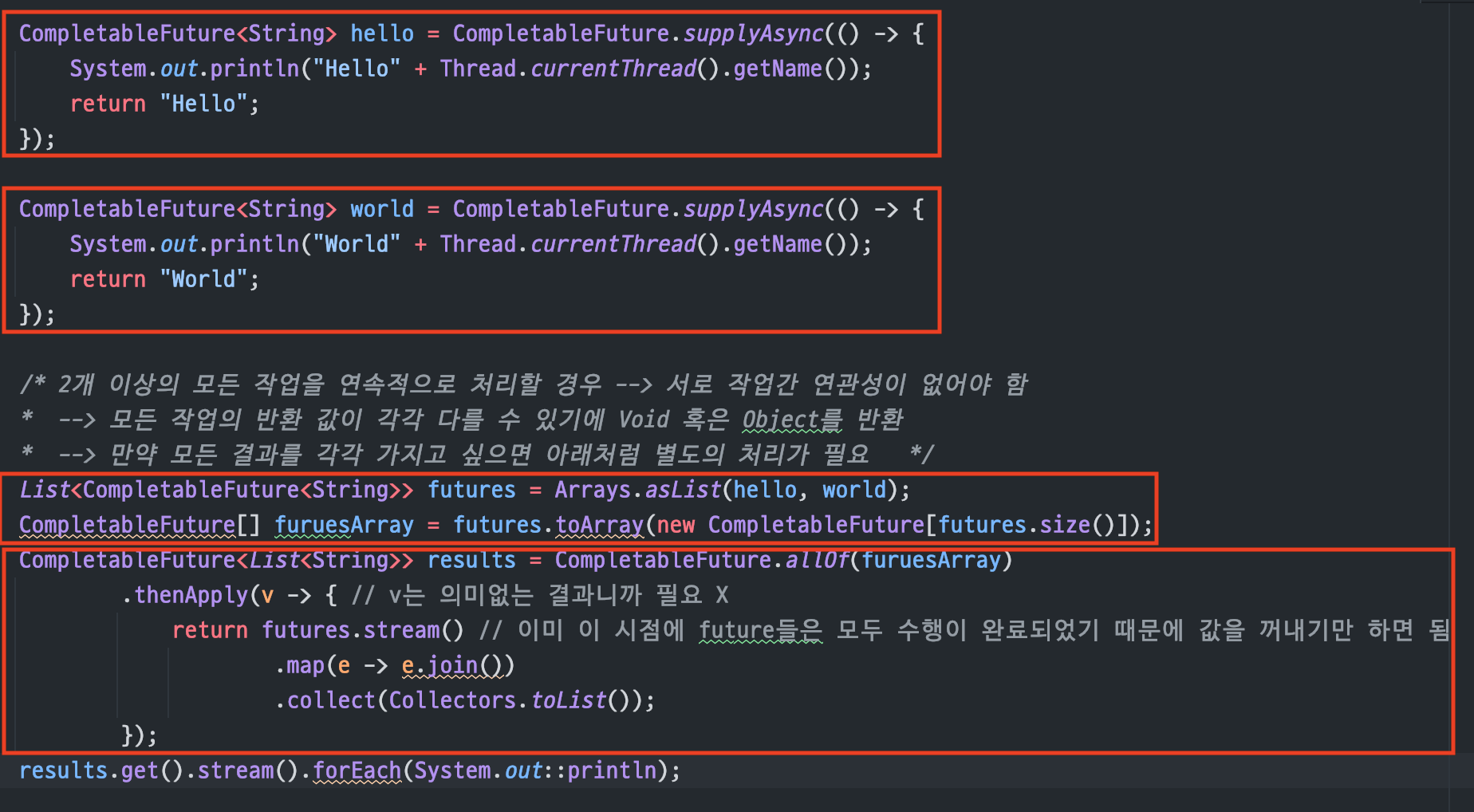
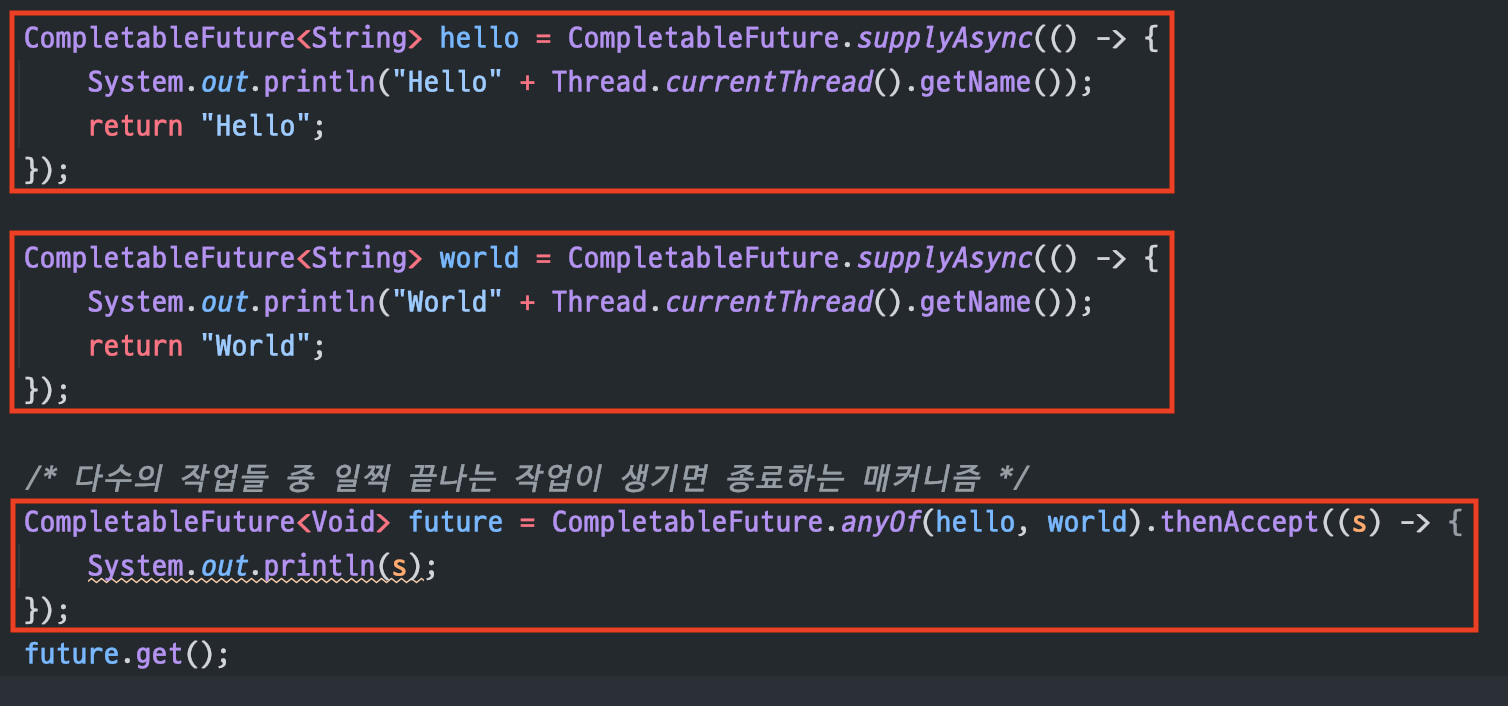
anyOf()
연관성이 없는 다수의 작업들 중먼저 끝나는 하나가 있으면 종료하는 방식
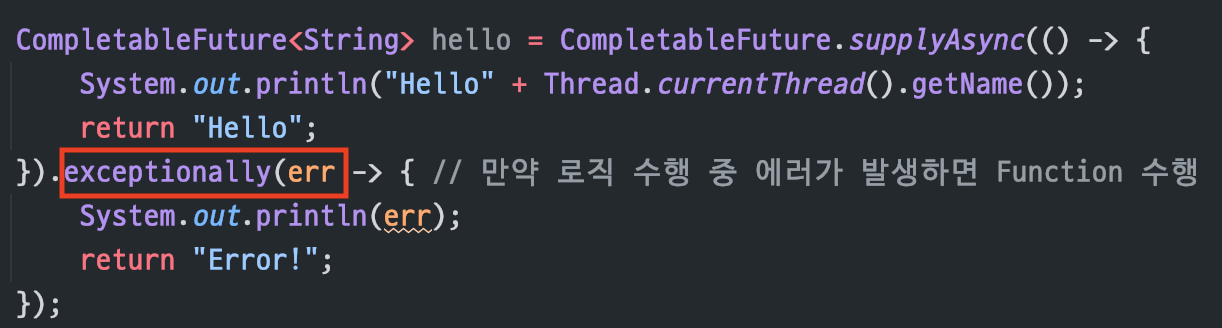
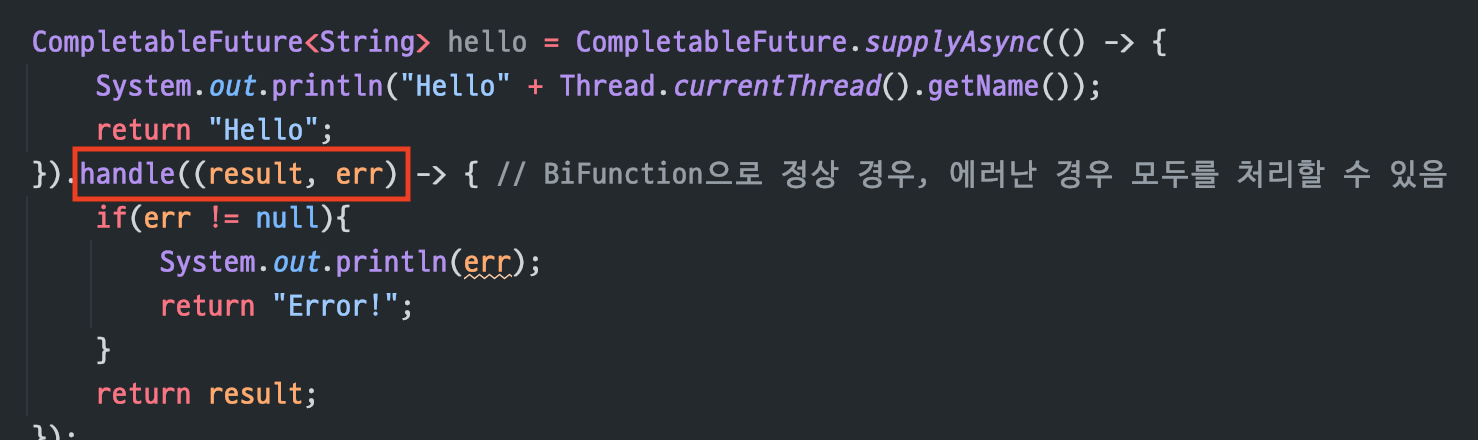
[ 예외처리 ]
exceptionally(Function)
비동기 작업을 하는 중에에러가 발생했을 때,에러를 처리하기 위한 용도
handle(BiFunction)
비동기 작업을 하는 중에에러가 발생했을 때,결과 값과에러모두를 처리하기 위한 용도
[ ListenableFuture ]
[ 설명 ]
- Spring에서 제공하는 클래스로 콜백 메소드를 추가할 수 있도록 Future를 확장한 인터페이스
- Future가 이미 완료된 상태에서 콜백이 추가된다면 콜백은 즉시 호출
[ 구성 ]
public interface ListenableFuture<T> extends Future<T> { /* ListenableFutureCallback을 등록 */ void addCallback(ListenableFutureCallback<? super T> callback); /* Java8의 람다를 사용할 수 있고, success와 fail에 대한 콜백을 각각 등록 */ void addCallback(SuccessCallback<? super T> successCallback, FailureCallback failureCallback); /* ListenableFuture 객체를 CompletableFuture로 변환해서 리턴 */ default CompletableFuture<T> completable() { CompletableFuture<T> completable = new DelegatingCompletableFuture(this); this.addCallback(completable::complete, completable::completeExceptionally); return completable; } }
ref

Developer & PhotoGrapher