Summation
cumsum
numpy.cumsum(a, axis=None, dtype=None, out=None)
ndarray.cumsum(axis=None, dtype=None, out=None)
np.sum은 ndarray의 해당 차원의 모든 원소를 더하여 스칼라를 return하지만 np.cumsum은 input ndarray와 같은 shape의 ndarray가 return된다.
- 활용 : cumsum을 이용하여 전체 data 중 각각의 원소가 차지하는 비율을 시각화할 때 사용할 수 있다.
import numpy as np
a = np.arange(5) [0 1 2 3 4]
cumsum = np.cumsum(a) [0 1 3 6 10]import numpy as np
a = np.arange(3*3).reshape((3,3)) [[0 1 2], [3 4 5], [6 7 8]]
cumsum = np.cumsum(a) [0 1 2 3 4 5 6 7 8]cumsum은 대상 array를 먼저 flatten 시킨 후에 sum을 구한다라고 생각하면 된다. axis를 설정하지 않거나 reshape을 다시 시켜주지 않으면 vector 형태로 출력된다.
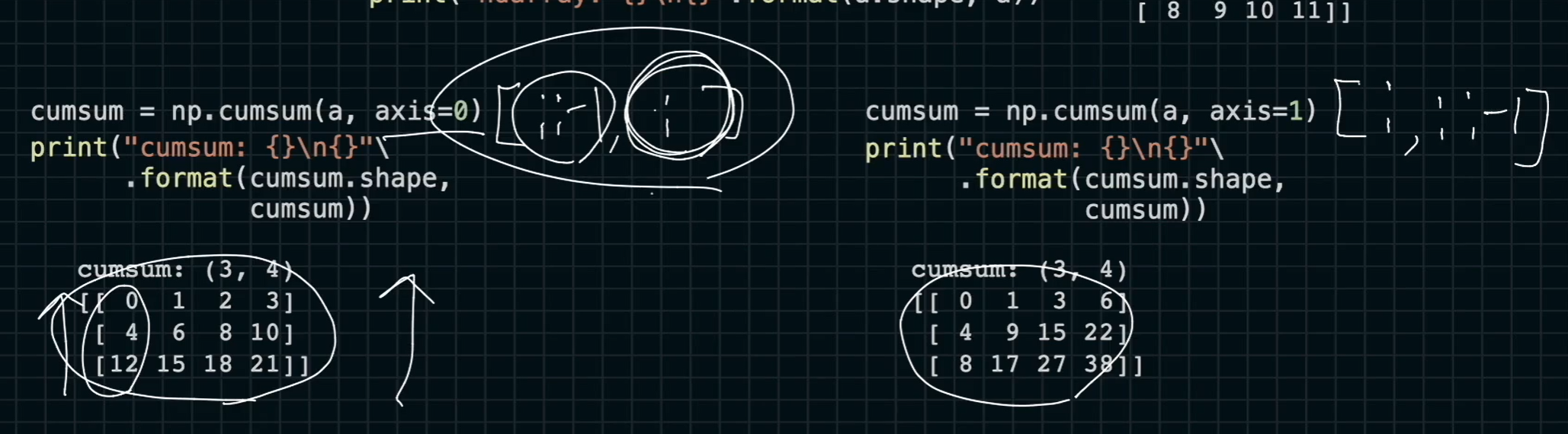
np.cumsum(a, axis=0)
차원과 모양이 유지가 되고 0번째 axis를 따라 합이 구해진다. 또한 슬라이싱을 통해 합을 구하는 방향을 바꿀수도 있다.
Difference
numpy.diff(a, n=1, axis=1, pretend=<no value>, append=<no value>)
원소와 원소간의 차이를 구해주는 API
import numpy as np
a = np.random.randint(0, 10,(5,)) [2 5 4 8 1]
diff = np.diff(a) (4,) [3 -1 4 -7]
미분을 구하기 위해 사용될 수 있다.
Statistics
Mean
데이터의 무게중심을 구하는 api라고 생각하면 된다.
import numpy as np
np.random.seed(0)
x = np.random.randint(1,10,(5,))
w = np.array([1 2 3 4 5])
np.average(x, weight = w) 5.0666
np.sum(w*x)/np.sum(w) 5.0666Median
numpy.median(a)
median은 중앙값을 의미한다. 짝수개의 원소일 때 중간 2개의 원소의 평균값을 출력한다.
import numpy as np
x = np.arange(9)
median = np.median(x)
[0 1 2 3 4 5 6 7 8]
4.0
x = np.arange(10)
median = np.median(x)
[0 1 2 3 4 5 6 7 8 9]
4.5중앙값은 outlier 데이터에 대해 평균이 왜곡되는 일을 방지할 수 있다. 이러한 특성을 outlier에 대해 robust하다라고 표현할 수 있다.
Variance and Standard Deviation
numpy.var(a, axis=None) & numpy.std(a, axis=None)
ndarray.var(axis=None) & ndarray.var(axis=None)
import numpy as np
scores = np.random.normal(loc=10, scale=5, size=(100,))
var = scores.var()
std = scores.std()Standardization
import numpy as np
means = [50, 60, 70]
stds = [3, 5, 10]
n_students, n_class = 100, 3
scores = np.random.normal(loc=means, scale=stds , size= (n_student, n_class))
scores = scores.astype(np.float32)
means = scores.mean(axis=0)
stds = scores.std(axis=0)
score_stdz = (scores - means)/stds #standardizationMax/Min values and Indices
numpy.amax(a, axis=None, out=none, keepdims=<no value>)
ndarray.max(axis=None, out=none, keepdims=<no value>)
Max 값을 return해준다.
numpy.argmax(a, axis=None, out=none)
ndarray.argmax(axis=None, out=none)
Max 값의 index를 return 해준다.
과목별 최고 점수와 최고점을 맞은 학생의 index를 구하기 위한 코드
import numpy as np
means = [50, 60, 70]
stds = [3, 5, 10]
n_students, n_class = 100, 3
scores = np.random.normal(loc=means, scale=stds , size= (n_student, n_class))
scores = scores.astype(np.float32)
scores_max = np.max(scores, axis=0)
scores_max_idx = np.argmax(scores, axis=0)Min Max Normalization
import numpy as np
means = [50, 60, 70]
stds = [3, 5, 10]
n_students, n_class = 100, 3
scores = np.random.normal(loc=means, scale=stds , size= (n_student, n_class))
scores = scores.astype(np.float32)
scores_max = np.amax(scores, axis=0)
scores_min = np.amin(scores, axis=0)
scores_mM_norm = (scores - scores_min)/(scores_max - scores_min)
scores_max = np.amax(scores_mM_norm, axis=0)
scores_min = np.amin(scores_mM_norm, axis=0)최대값과 최소값이
Maximum and Minimum
Maximum & Minimum은 두 array간의 최대값,최소값을 구해준다
import numpy as np
u = np.random.randint(0,10,(10,)) [3 2 6 9 3 8 5 4 5 0]
v = np.random.randint(0,10,(10,)) [4 6 4 4 8 6 5 1 8 5]
maximum = np.maximum(u, v) [4 6 6 9 8 8 5 4 8 5]
minimum = np.minimum(u, v) [3 2 4 4 3 6 5 1 5 0]활용 방법
import numpy as np
u = np.random.randint(0,10,(10,))
v = np.random.randint(0, 10, (10,))
maximum = np.zeros_like(u)
maximum[u >= v] = u[u >= v]
maximum[u < v] = v[u < v]
--> np.maximum(u, v)와 같다u가 v보다 큰 index와 value를 모두 한꺼번에 받아와서 u로 채우겠다
import numpy as np
u = np.random.randint(0,10,(10,))
v = np.random.randint(0,10,(10,))
up_val = np.full_like(u, fill_value = 100)
down_val = np.full_like(u, fill_value = -100)
np.where(u > v, up_val, down_val)u가 큰 곳에는 up_val로 채우고 v가 큰 곳에는 down_val로 채운다.
import numpy as np
u = np.random.randint(0,10,(10,))
v = np.random.randint(0,10,(10,))
maximum = np.maximum(u,v)
maximum_where = np.where(u > v, u, v)
minimum = np.minimum(u,v)
minimum_where = np.where(u > v, v, u)where를 사용하여 np.maximum/ np.minimum을 구현해낼 수 있다.
