Intro
우리는 왜 문장 구조를 알아야할까?
인간은 복잡한 의미를 전달하기 위해 단어들을 조합하여 큰 단위의 단어 뭉치를 만든다. 청자는 문장 구조를 통해 의미를 파악하는데 도움을 받고 기계 또한 그 도움을 받기를 원한다.
NLP에서 문장의 구조를 파악하기 위해 parsing tree를 사용한다. 문법적인 구조(Syntactic Structure)에는 2가지가 있다. Constituency structure와 Dependency Structure가 있다. Constituency structure는 context-free grammers(CFGs)라고도 불린다. 이 방식은 절(phrase) 단위로 nested constituent를 만들어 문장 속 단어들을 분류한다. 단어들간의 문맥은 신경 쓰지 않는다. 오직 문법 규칙을 이용하여 구조를 파악하는 것이다
Noun Phrase 와 Verb Phrase의 예시
- A handsome guy(noun phrase)
- The blue umbrella(noun phrase)
- ... is writing(verb phrase)
- ... can't eat(verb phrase)
Noun Phrase : 단어들의 집합으로 하나의 명사처럼 문장 내에서 기능한다.
Verb Phrase : 단어들의 집합으로 하나의 동사처럼 문장 내에서 기능한다.
Dependency Parsing
CGFs는 단어의 순서에 신경을 많이 쓰는데 언어별로 문장의 순서가 다르고 특정한 순서로 단어가 배열되어야 한다는 Golden rule은 없다. 그렇기에 기계번역과 같은 작업을 수행할 때 문법 규칙을 사용하는 것에 문제가 생긴다. 앞서 말한 CFGs와는 다른 종류의 구조로 문장 속 단어를 분류하는 parsing 방식이 필요하다. Dependency structure는 문장 속 단어들의 종속/꾸밈 관계를 표현하여 문장 구조를 tree 형태로 분석해낸다. Dependency 관계는 head에서 dependent로의 화살표를 통해 나타낸다. 그리고 화살표 옆에는 문법적인 관계를 표시한다. 또한 가짜 Root를 하나 사용하여 모든 단어가 정확히 하나의 단어에 종속되어 있는 구조를 의도적으로 만든다. Dependency path를 통해 semantic interpretation(의미론적인 해석)을 찾을 수 있다.
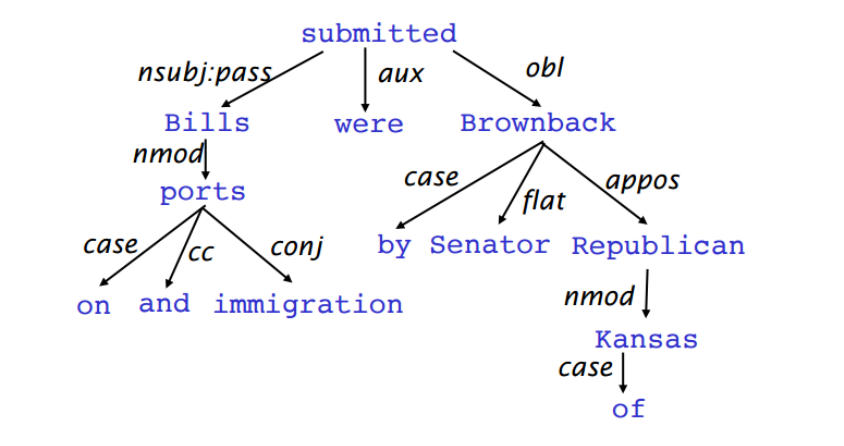
다음은 Dependency parsing에 사용되는 약어들에 관한 설명이다.
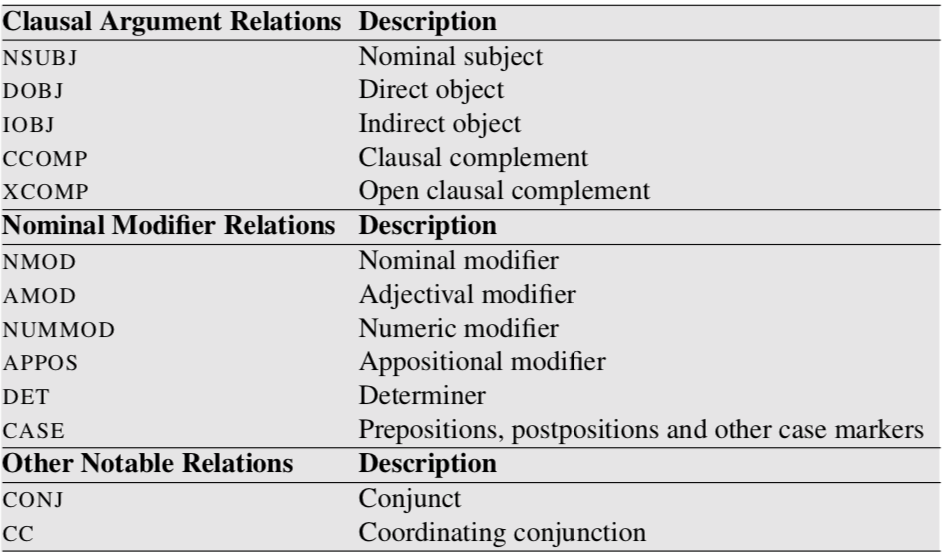

Projectivity
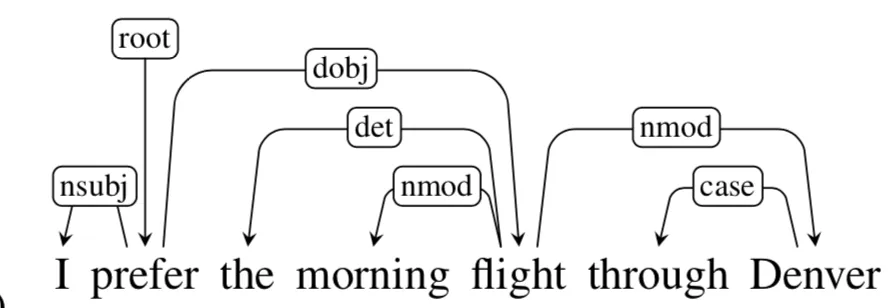
Projectivity는 모든 HEAD와 Dependent 사이의 단어에 대해 HEAD에서 접근하는 경로가 존재하는 것을 의미한다. 예를 들어 the 와 flight 사이에 끼어있는 morning은 flight의 dependent이므로 접근이 가능하며 prefer의 dependent인 flight에 dependent인 the 혹은 morning에 접근이 가능하다. 위 문장에는 화살표(Arc라고 부름)가 교차되는 것이 없다. 모든 단어가 projective한 tree를 Projective Parse Tree라고 부른다.
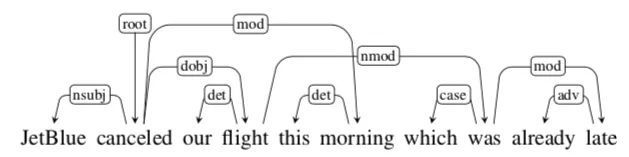
Non-projective parse tree는 위와 같이 arc가 교차하는 지점이 있어 Flight 와 was 사이에 morning에는 접근을 할 수 없는 tree를 말한다.
Dependency Parsing은 크게 2가지의 Problem/ Task가 있다.
- Learning : Dependency graph가 주어진 트레이닝 문장 데이터 D가 주어졌을 때 새로운 문장을 parsing하여 graph를 만들어낼 수 있도록 모델 M을 학습시키는것이다.
- Parsing : 모델 M과 문장 S가 주어졌을 때 문장 S를 위한 최적의 그래프 G를 모델 M을 통해 도출해내는 것이다.
Transition-Based Dependency Parsing
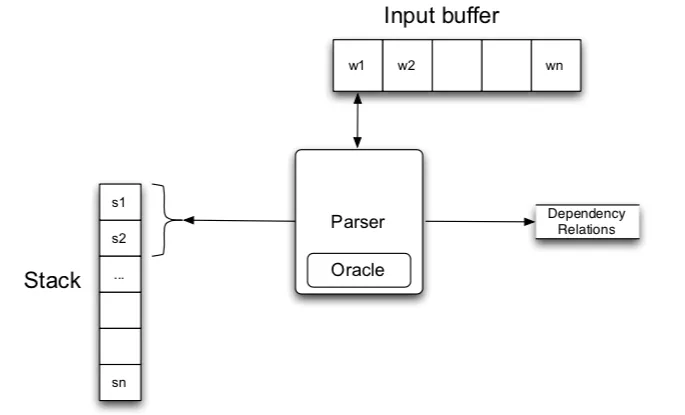
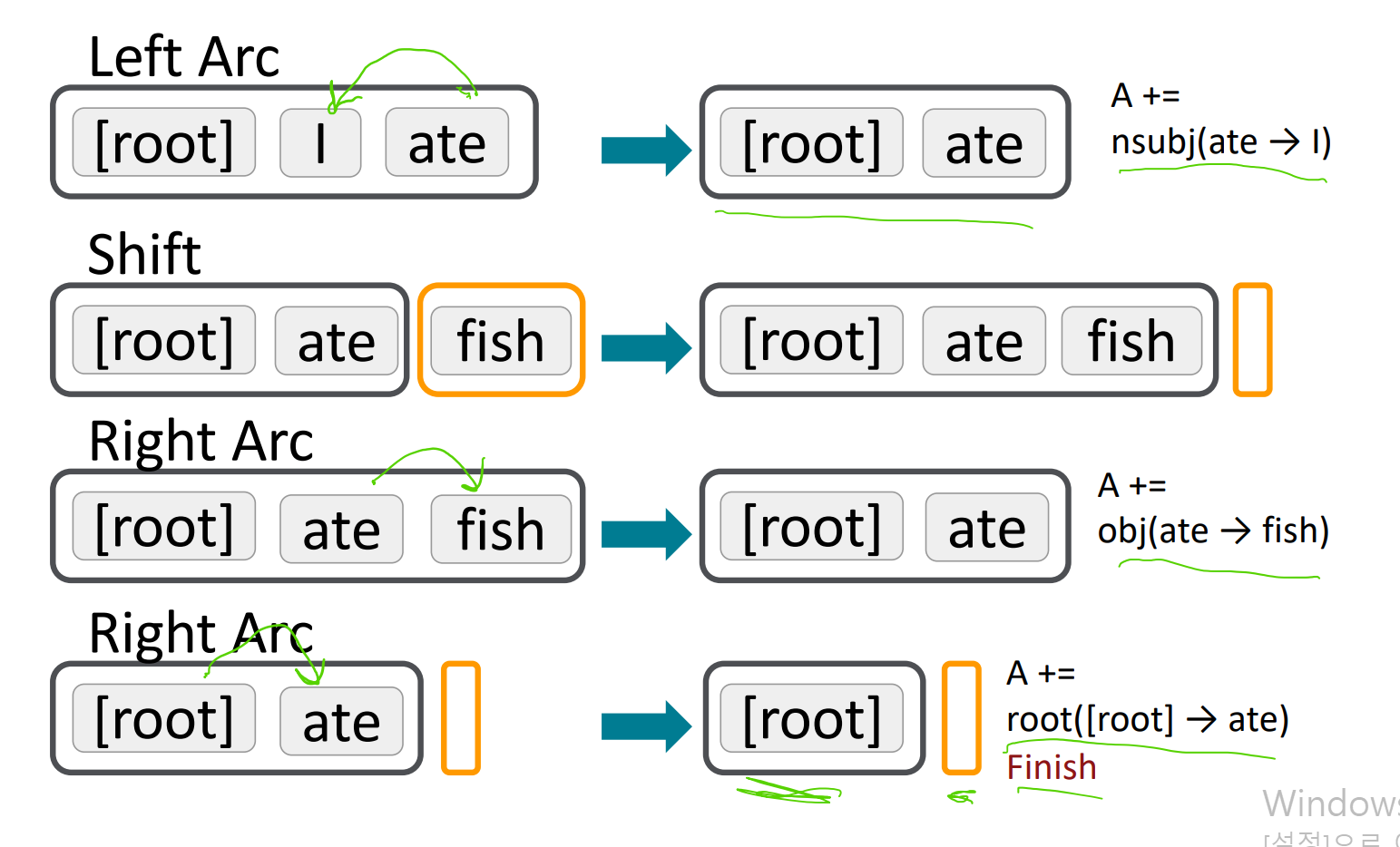
Parse tree를 도출해내기 위한 알고리즘 중 하나에 대해 설명할 것이다. 우선 3가지가 필요한데
- Stack
- Input word 를 담을 Buffer
- Parser와 Dependency relations
초기에 stack에는 fake ROOT만 들어있고 문장 단어들은 Buffer에 들어있다. Buffer에서 하나의 단어씩 Stack에 push되고 stack의 가장 위쪽 단어 2개를 비교하여 다음의 3가지 transition(하나의 상태에서 다른 상태로 전이하는 것) 중 하나를 수행한다.
- Left arc function
stack top word가 HEAD이고 두번째 단어가 Dependent라고 판단하여 dependent 단어(두번째 단어)를 stack에서 제거한다. - Right arc function
stack top word가 Dependent이고 두번째 단어가 HEAD라고 판단하여 dependent 단어(Stack top word)를 stack에서 제거한다. - Shift
Buffer front에서 단어를 제거하고 Stack에 Push한다.