일론 머스크가 트위터 인수 공약으로 약속한 트위터 추천알고리즘을 오픈소스로 GitHub 공개했습니다.
이 알고리즘은 위의 사진과 같이 트위터 For You 타임라인이 어떤 방식으로 사용자에게 트윗을 추천해주는지에 대한 내용입니다.
아래 내용은 트위터 블로그를 정리한 글입니다.
How do twitter choose tweets
트윗 추천알고리즘은 하루 5억 개의 트윗 중 사용자 맞춤의 트윗만 추출해서 보여줍니다.
이 추천알고리즘은 사용자의 트윗, 사용자, 참여 데이터에서 잠재정보를 추출하는 핵심 모델입니다.
이러한 모델은 미래에 다른 사용자와 상호 작용할 확률은 얼마입니까? 또는 Twitter의 커뮤니티는 무엇이며 커뮤니티 내에서 유행하는 트윗은 무엇입니까? 같은 질문에 답하며 사용자에게 더 관련성 높은 추천을 제공합니다.
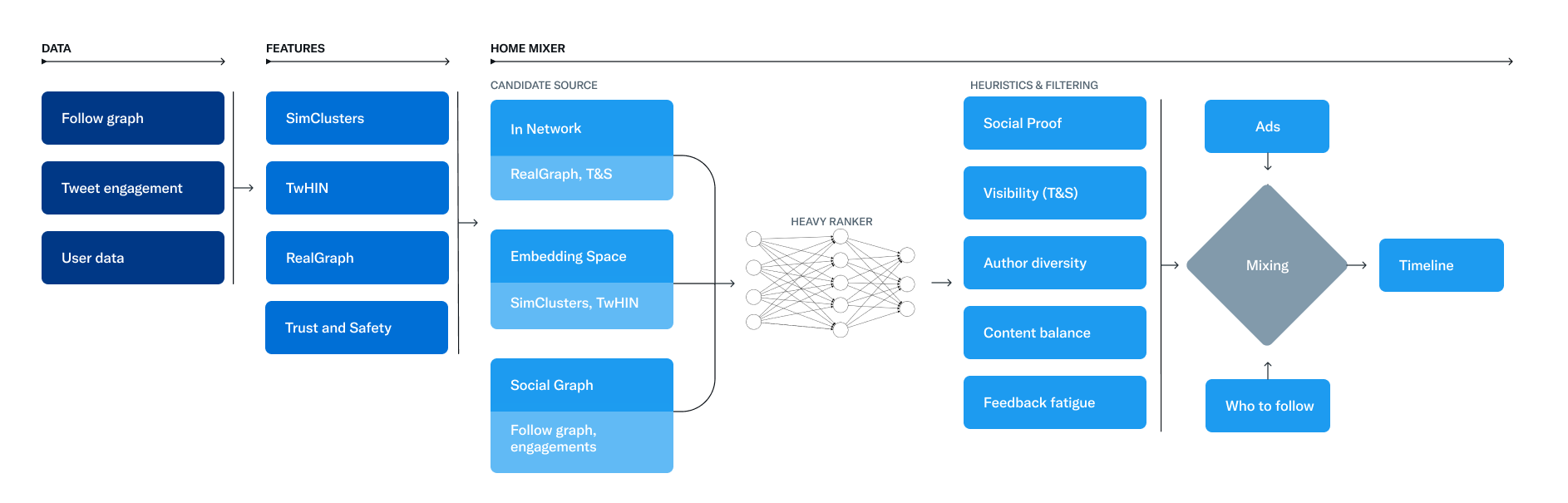
추천 알고리즘의 동작 흐름은 3가지 파이프라인으로 candidate sourcing -> Rank -> Heuristics and filter 순으로 진행됩니다.
-
candidate sourcing
다양한 추천 소스에서 최고의 트윗을 가져온다. -
Rank
머신러닝 모델을 사용해 각 트윗에 순위를 매깁니다. -
Heuristics and filters
차단한 사용자의 트윗, NSFW 콘텐츠, 이미 본 트윗을 필터링
Candidate Sourcing (트윗 후보 추출)
수억 개의 트윗 중에서 가장 적합한 1,500개의 트윗을 추출합니다. 사용자가 팔로우한 사람들(In-Network)과 사용자가 팔로우하지 않은 사람들(Out-of-Network)에서 후보를 찾는데 평균 50:50 비율로 구성하지만 사용자 마다 다를 수 있습니다.
In-Network Source(팔로우한 소스)
In-Network source는 가장 큰 후보 소스이며 팔로우하는 사용자의 트윗 중 가장 사용자와 관련성이 높은 트윗을 전달하는 걸 목표로 합니다. 로지스틱 회귀 모델(두 데이터의 관련성을 찾는 모델)을 이용해 가장 관련성이 높은 트윗의 순위를 효율적으로 지정한 다음 상위 트윗들을 다음 단계로 전송합니다.
In-Network source에서 가장 중요한 요소는 Real Graph 입니다.
Real Graph는 두 사용자 간의 참여 가능성을 예측하는 모델인데 사용자와 트윗의 작성자의 Real Graph 점수가 높을수록 더 많은 트윗이 포함됩니다.
Out-of-Network Source(팔로우하지 않은 소스)
사용자의 네트워크 외부에서 관련 트윗을 찾기는 까다로운 문제입니다. 작성자를 팔로우 하지 않은 경우 특정 트윗이 사용자와 관련이 있는지 어떻게 알 수 있습니까 트위터는 이 문제를 해결하기 위해 두 가지 접근 방식을 사용합니다.
Social Graph
첫 번쨰 접근 방식인 Social Graph는 팔로우한 사람이나 비슷한 관심사를 가진 사람들을 분석해 관련성을 있다고 판단하게 되는 트윗을 추정하는 겁니다.
참여 그래프는 다음 질문에 답합니다.
- 내가 팔로우하는 사람들이 최근에 어떤 트윗에 접근했습니까?
- 나와 비슷한 트윗을 좋아하는 사람은 누구이며 최근에 어떤 트윗에 '좋아요'를 눌렀나요?
이러한 질문에 대한 답변을 기반으로 후보 트윗을 생성하고 로지스틱 회귀 모델을 사용해 결과 트윗의 순위를 매깁니다.
이러한 유형의 그래프 순회는 out-of network source에 필수적이며 트위터는 이러한 순회를 실행하기 위해 사용자와 트윗간의 실시간 상호 작용 그래프를 유지하는 그래프 처리 엔진인 GraphJet을 개발했습니다.
Embedding Spaces
임베딩 공간 접근법은 콘텐츠의 유사성보단 어떤 트윗과 사용자가 내 관심사와 비슷합니까? 에 대한 질문에 답을 합니다.
임베딩은 사용자의 관심사와 트윗 콘텐츠를 숫자로 표현하는 방식을 사용합니다. 그 후에 임베딩 공간에서 사용자-사용자,사용자-트윗,트윗-트윗쌍 간의 유사성을 계산할 수 있습니다. 정확한 임베딩을 생성하면 이 유사성을 관련성의 기준으로 사용할 수 있습니다.
트위터의 가장 효과적인 임베딩 공간 중 하나는 SimClusters입니다. custom matrix factorization algorism을 사용해 영향력 있는 사용자 클러스터에 기반한 커뮤니티를 발견합니다. 3주마다 업데이트되는 145,000개의 커뮤니티가 있고 사용자와 트윗은 여러 커뮤니티 공간에 속할 수 있습니다.
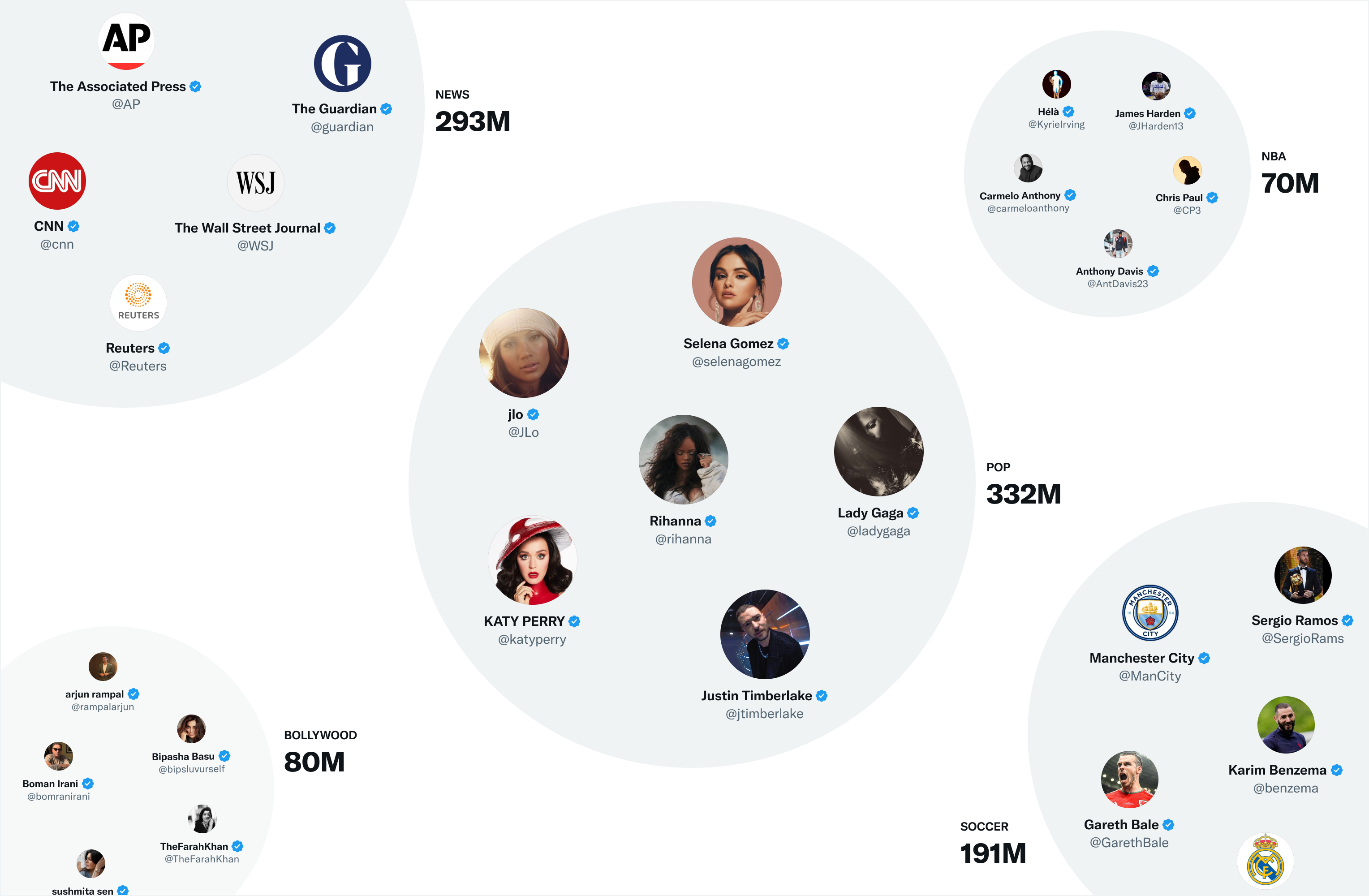
각 커뮤니티에서 인기도를 확인하고 임베딩 공간에 트윗을 삽입합니다. 트윗을 좋아하는 커뮤니티의 사용자가 많을수록 해당 트윗이 해당 커뮤니티와 더 많이 연결됩니다.
Ranking
For you 타임라인의 목표는 사용자와 관련 트윗을 제공하는 것입니다. 이 파이프라인 시접에서 1500개의 후보를 보유하고 후보들의 관련성을 직접 예측합니다.
Ranking 약 4800만개의 feature를 가진 신경망 딥러닝 모델로 트윗 상호작용을 학습후 긍정적인 참여(좋아요, 리트윗 및 답글)를 최적화한다.
수천 개의 feature를 고려해 10개의 output label을 출력하고 각 트윗에 점수를 부여해 트윗의 순위를 매깁니다.
Hueristics & Filters
Ranking 단계 이후 Hueristics와 filters를 적용해 다양한 제품 기능을 구현합니다. 이러한 기능을 작동해 균형 있고 다양한 피드를 생성합니다.
- Visibility Filtering
차단하거나 뮤트한 사용자의 트윗을 필터링 - Author Diversity
단일 사용자의 피드가 너무 연속적일 경우 필터링 - Content Balance
In-NetWork-Source와 Out-Network-Source의 적절한 비율을 유지한다. - Feedback-based Fatigue
사용자가 부정적인 피드백을 제공한 경우 Ranking 점수를 낮춘다.
Mixing
이 지점에서 HomeMixer 파이프라인은 사용자의 For you 타임라인에 트윗을 보낼 준비가 되었습니다.
파이프라인의 마지막 단계로 광고, 팔로우 권장 사항, 온보딩 프롬프트와 같은 트윗이 아닌 콘텐츠와 트윗을 혼합하여 사용자의 For you 타임라인으로 보냅니다.
위 파이프라인은 하루에 약 50억 회 실행되며 평균 1.5초 이내에 완료되고 단일 파이프라인 실행에는 220초의 CPU 시간이 필요하며 앱에서 인식하는 대기 시간의 거의 150배 입니다.
정리
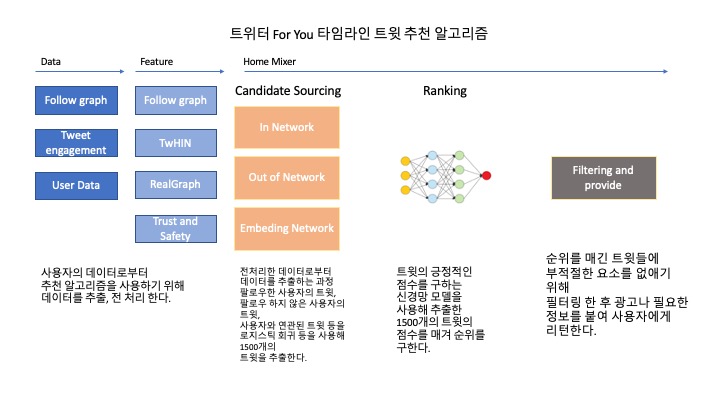
매우 복잡한 구조와 과정을 거치지만 데이터를 추출 후 전처리하고 머신러닝과 딥러닝 모델을 적용, 필터링 후 사용자에게 추천해주는 구조입니다.
졸업 프로젝트 과제로 구독 서비스를 사용자에게 추천해주는 기능 구현을 해야 할 상황이 있었습니다. 추천 알고리즘이 생각보다 구현이 어려워 단순히 임의로로 변수를 설정하고 가중치를 주는 방식으로 구현했는데 구독서비스는 객관적 요소보단 감성적 요소이므로 사람이 판단해 알고리즘을 만들 보단 신경망 모델을 만들어 판단하면 좋겠다는 생각까지는 했는데 실제로 구현까지는 못 했습니다.
트위터 추천 알고리즘을 뜯어보면서 물론 트위터 알고리즘처럼 추천을 위해 사용자에게 할 질문을 잘 설정하고 데이터를 전처리 한후 신경망 모델을 사용하면 추천 알고리즘을 구현할 수 있겠다는 답을 얻었습니다.
Reference.
