
1. 데이터엔지니어링 정의
데이터 엔지니어링의 인기가 높아졌지만 데이터 엔지니어링이 실제로 무엇을 의미하는지, 데이터 엔지니어가 무엇을 하는지에 관해서는 여전히 많은 사람이 혼란스러워 한다.
데이터 엔지니어링이라는 용어에는 수많은 정의가 존재한다. 다음은 데이터엔지니어링에 관해 이 분야의 일부 전문가들이 정의하는 몇가지 예문이다.
- 데이터를 사용할 수 있도록 하는 일련의 작업
- 조직의 데이터 인프라를 구축하고 운영해 데이터 분석가와 데이터 과학자가 추가 분석을 수행할 수 있도록 준비한다.
- SQL 기반 언어로 ETL 도구를 사용해 데이터 처리를 수행한다.
하둡, 카산드라, HBase와 같은 스토리지맵리듀스, 스파크,플링크같은 빅데이터 프레임워크등의 기술들을 가지고 데이터 작업을 수행한다.- 기존 소프트웨어 엔지니어링에서 더 많은 요소를 가져오는 비즈니스 인텔리전스와 데이터 웨어하우징의 상위집합으로 생각할 수 있다. 확장된 하둡 생태계, 스트림 처리, 규모에 따른 컴퓨팅에 대한 개념과 함께 소위
빅데이터 분산 시스템 운영에 관한 전문화를 통합한다. - 데이터 이동,조각, 관리에 관한 모든것
다양한 전문가들이 데이터 엔지니어링을 어떻게 정의하는가에 관한 공통된 맥락을 풀어보면 데이터를 가져오고 DA나 DS가 사용할 수있도록 준비한다. 라는 공통된 패턴이 있다.
데이터 엔지니어링은 원시 데이터(raw_data)를 가져와 분석 및 머신러닝과 같은 다운스트림 사용 사례를 지원하는, 고품질의 일관된 정보를 생성하는 시스템과 프로세스의 개발, 구현 및 유지 관리이다. 데이터엔지니어링은 보안, 데이터 관리, 데이터 운영, 데이터 아키텍처, 오케스트레이션, 소프트웨어 엔지니어링의 교차점이다.
데이터 엔지니어링은 데이터를 가져와 분석 또는 머신러닝과 같은 사용 사례에 데이터를 제공하는 것으로 끝나는 데이터 엔지니어링 수명주기를 관리한다.
데이터 엔지니어링 수명 주기
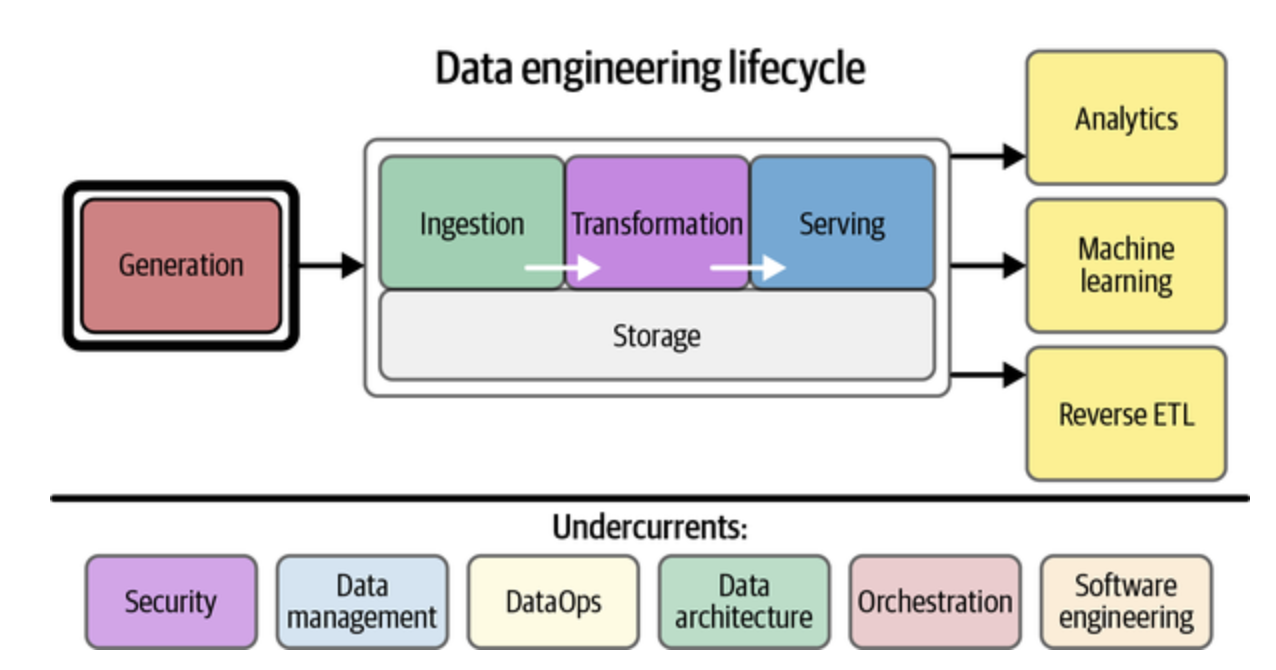
출처: Fundamentals of Data Engineering by Joe Reis, Matt Housley
데이터엔지니어링 수명주기는 기술에서 벗어나, 데이터 자체와 데이터가 제공해야 하는 최종 목표에 관한 논의로 전환한다. 데이터 엔지니어링 수명주기의 단계는 다음과 같다.
- 데이터 생성(Generation)
- 데이터 저장(storage)
- 데이터 수집(Ingestion)
- 데이터 변환(transformation)
- 데이터 서빙(Serving)
데이터 엔지니어링 수명주기는 전체 수명주기의 중요한 아이디어인 드러내지 않는 요소(Undercurrents) 라는 개념을 포함한다.
