하둡 Cluster 생성

Hadoop On-premise생성
- 데이터 엔지니어링 수업 과정 중 Hadoop Spark수업을 진행하기에 앞서 희망하는 사람들을 대상으로 Hadoop전용 노트북을 받아서 클러스터를 생성
- 총 8대의 컴퓨터를 대여하여 Ubuntu22.04버전 운영체제로 설치하고, 각 컴퓨터를 namenode, secondnode, datanode1~5, client를 설정
클러스터 생성 방법
운영체제 설치 및 설정
Ubuntu22.04 운영체제 설치
- 강사님이 주신 Ubuntu22.04 usb로 운영체제 설치
- 터미널에서
ibus-setup입력 후 한글 사용 가능 설정
hadoop user 생성
sudo adduser hadoop
- 아이디 : hadoop
- 비밀번호 : hadoop
hadoop클러스터 ssh키 생성
ssh 키 생성 이유
- 인증 및 보안 : ssh키를 이용하여 클러스터 노드 간에 안전한 통신을 위해 설정
- 자동 접속 : ssh키를 사용하여 각 노드별 공유시 암호를 입력하지 않고 원격 노드에 접속 가능
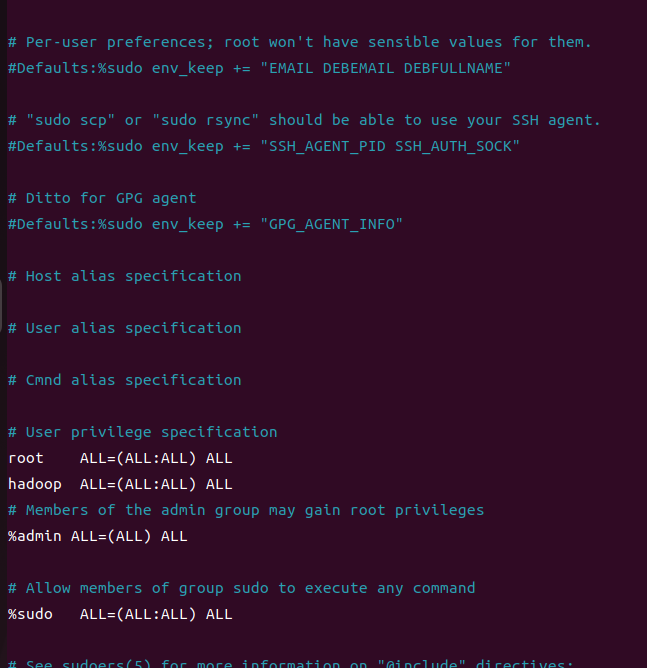
sudo apt install openssh-serverssh-keygen -t rsa: ssh 키 생성- 키 생성 후
cat id_rsa_pub >> authorized_keys입력 후 ssh키를 가진 authorized_keys 생성chmod 600 ./authorized_keys: 소유자에게만 읽기, 쓰기 적용visudo입력 후 hadoop ALL = (ALL:ALL) ALL 추가
방화벽 해제 및 고정 IP설정
방화벽
ufw란?
- 리눅스 시스템에서 사용되는 방화벽 관리 도구 (네트워크 트래픽 제어 및 보호)
hadoop클러스터 설정 시 ufw를 비활성화하는 이유
- 네트워크 통신 : 클러스터의 노드 간의 데이터 송수신이 되어야 하는데, ufw가 활성화되어 있으면 클러스터 노드 가의 통신이 제한될 가능성이 있음
- port 접근 : HDFS는 데이터 전송을 특정 포트(50070)를 사용하는데, ufw가 활성화 되있을 시 클러스터의 성능에 영향을 줄 수 있음
sudo apt install ufw
sudo systemctl stop ufw #방화벽 서비스 일시 중지
sudo systemctl disable ufw #시스템 부팅 시 ufw가 자동으로 시작 되지 않도록 설정 고정 IP설정
고정 IP설정 이유
- 식별성 및 안전성 : 각 노드별 식별 확인을 위해서 설정
- 네트워크 통신 : 고정 IP주소 설정 시 노드 간 통신에 필요한 IP주소를 미리 알 수 있어, 이를 기반으로 통신설정 가능
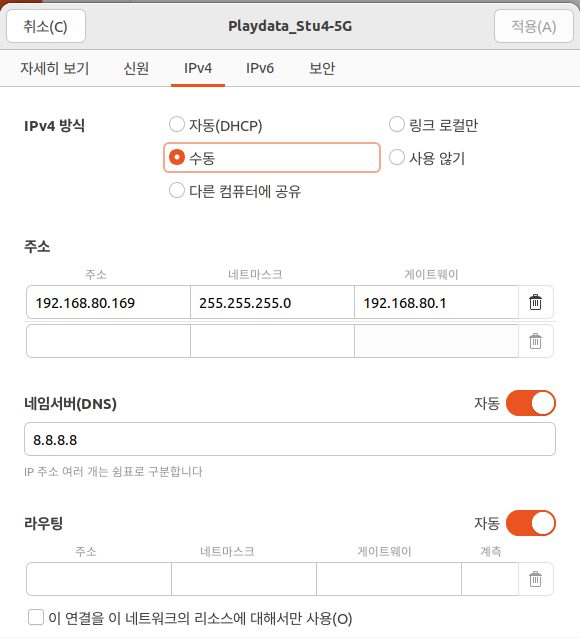
- 터미널에서 현재 컴퓨터의 ID주소 확인
- 우분투 네트워크 설정에 접속하여 IPv4를
수동으로 설정 후주소에 본인의 IP주소, 넷마스크는 255.255.255.0, 게이트웨이는192.168.80.1로 모든 노드 동일하게 설정
hadoop 설치
JAVA 설치 및 설정
sudo apt install java-1.8.0-openjdk ant -y: java 설치vim ~/.bashrc터미널에서 입력 후 경로 지정을 위해 아래 명령어 입력
-export JAVA_HOME="/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.372.b07-1.el7_9.x86_64"
hadoop 설치 및 설정
sudo apt install wget
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
tar xzf hadoop-3.2.1.tar.gz
mv ./hadoop-3.2.1 ./hadoop- hadoop 설치 후 경로 설정
export SPARK_HOME=/home/hadoop/spark
export HADOOP_HOME=/home/hadoop/hadoop
export HIVE_HOME=/home/hadoop/hive
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$HIVE_HOME/bin
노드 간 통신 설정
- ssh 퍼블릭 키를 1개로 모아서 모든 노드에 전달
- 총 8대의 노드들 모두 생성 후 ssh키를 공유하고서 하나의 authorized_keys로 생성 후 전달
scp ./authorized_keys client:/home/hadoop/.ssh/
scp ./authorized_keys namenode:/home/hadoop/.ssh/
scp ./authorized_keys secondnode:/home/hadoop/.ssh/
scp ./authorized_keys datanode1:/home/hadoop/.ssh/
scp ./authorized_keys datanode2:/home/hadoop/.ssh/
scp ./authorized_keys datanode3:/home/hadoop/.ssh/
scp ./authorized_keys datanode4:/home/hadoop/.ssh/
scp ./authorized_keys datanode5:/home/hadoop/.ssh/vim /etc/hosts: hosts파일 수정
192.168.80.14 datanode1
192.168.80.150 datanode2
192.168.80.169 datanode3
192.168.80.160 datanode4
192.168.80.155 datanode5
192.168.80.170 client
192.168.80.4 namenode
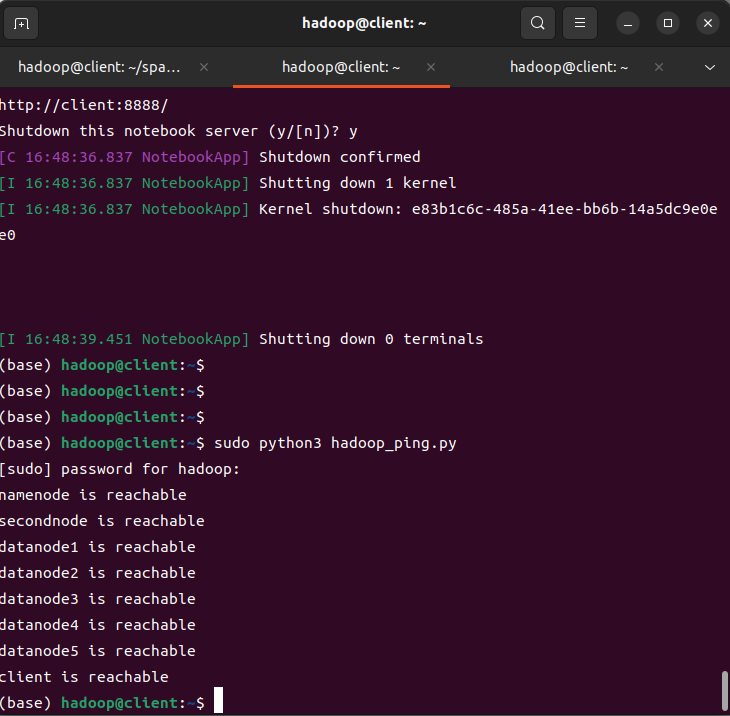
192.168.80.28 secondnodehadoop 데이터노드 ping 확인용 파이썬 실행파일 생성
- 각 노드별 핑을 확인하는 파이썬 코드 생성
from pythonping import ping
node_list = ['namenode',
'secondnode',
'datanode1',
'datanode2',
'datanode3',
'datanode4',
'datanode5',
'client']
for hostname in node_list :
response = ping(hostname)
if response.success():
print(f"{hostname} is reachable")
else:
print(f"{hostname} is unreachable")sudo python3 hadoop_ping.py을 입력하면 각 노드별 상태를 확인 가능함