하둡이란?
- 분산 처리를 하기 위한 오프 소스 소프트웨어
- MapReduce(데이터 처리 모델), HDFS(데이터 저장 처리)를 사용

Jobtracker
- 클러스터의 다른 노드들에게 맵, 리듀스 Task할당
- Job : 수행작업 기본단위
-> 각 task는 YARN을 통해 스케줄링 진행
하둡의 구조(Master-Worker)
- 하둡은 master-work구조롤 동작되며, 마스터노드&워커노드로 구성
master node
- DFS(Distribute File System:분산파일 시스템) 정보 보유
- 자율 할당 조절
- Name node : DFS관리, 자원 관리
- Resource Manager : 스케줄링, worker node 관리
worker node
- 실제 데이터 보유하는 node
- Data node : Name Node에 물리적으로 저장된 실제 데이터 관리
- Node Manage : 노드의 task 실행
MapReduce
- 여러 노드에 태스크를 분배하는 데이터 처리 모델
- 데이터를 특정 크기의 블록으로 나누고 각 블록에 대해 Map Task와 Reduce Task를 수행
Map
- 처리한 데이터를 key, value의 형태로 변환하는 작업 수행
- 해당 데이터를 리스트 형태로 반환
Reduce
- Map으로 처리한 데이터에서 중복된 Key값을 지니는 데이터를 제거하여 합치고, 원하는 데이터를 추출하는 작업 수행
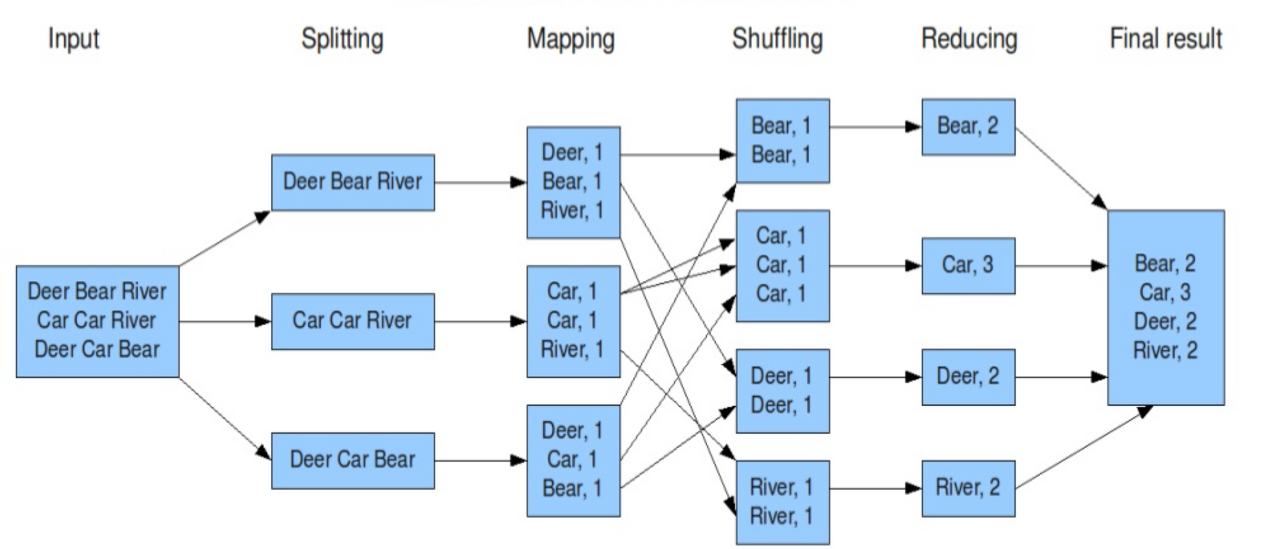
MapReduce 데이터 처리 흐름
- Input : 데이터 입력
- Spliting : 데이터를 분할하여 HDFS에 저장
- Map : key:value로 저장
- Shuffle : map 함수의 결과를 reduce에 전달하는 과정
- Reduce : 정령 및 그룹화
- Output : 출력
참고자료
https://mangkyu.tistory.com/129
https://12bme.tistory.com/154
하둡 완벽 가이드데이터의 숨겨진 힘을 끌어내는 최고의 클라우드 컴퓨팅 기술, 4판(2017)
