https://wikidocs.net/22886
https://ratsgo.github.io/natural%20language%20processing/2017/03/09/rnnlstm/
순환 신경망(RNN, Recurrent Neural Network)
RNN은 입력과 출력을 시퀀스 단위로 처리하는 시퀀스 모델이다. 예를 들어 번역기와 같이 번역하고자 하는 단어의 시퀀스인 문장을 넣어 번역한 문장을 도출하는 시퀀스 등을 처리하기 위한 모델이 시퀀스 모델이다. RNN 중 대표적으로 LSTM 모델이 있으며, 해당 모델을 함께 정리해볼 예정이다.
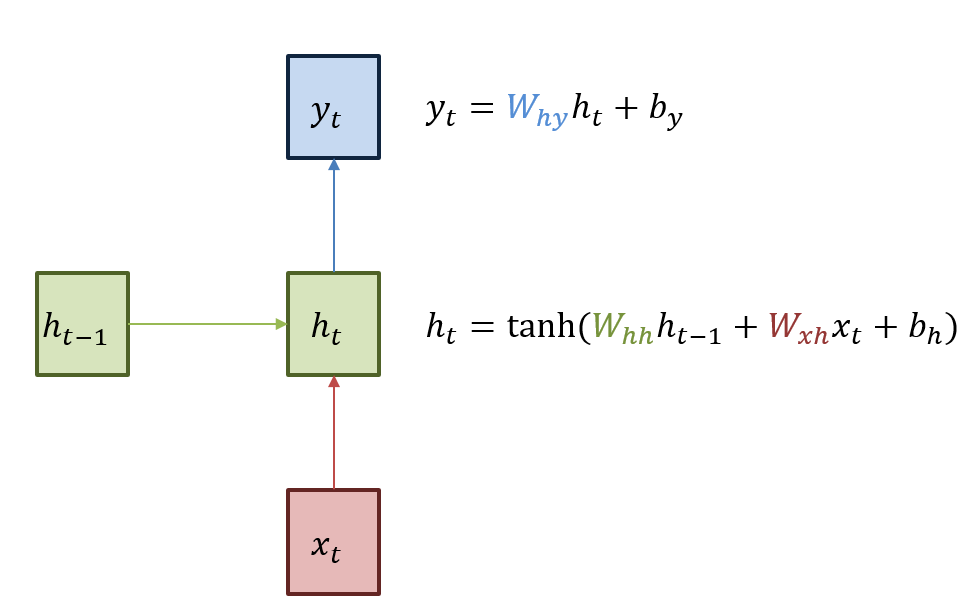
RNN은 히든 노드가 방향을 가진 엣지로 연결돼서 순환구조를 이루는 인공신경망의 한 종류이다. 위 그림은 RNN의 기본 구조를 나타내며, 녹색박스는 히든 state, 빨간박스는 인풋 x, 파란박스는 아웃풋 y이다. 현재상태의 히든 state ht는 직전 시점의 히든 state ht-1를 받아서 갱신된다. 그리고 현재 상태의 아웃풋 yt는 ht를 전달받아 갱신되는 구조이다. 또한 히든 state의 활성화함수는 하이퍼볼릭탄젠트를 사용한다.
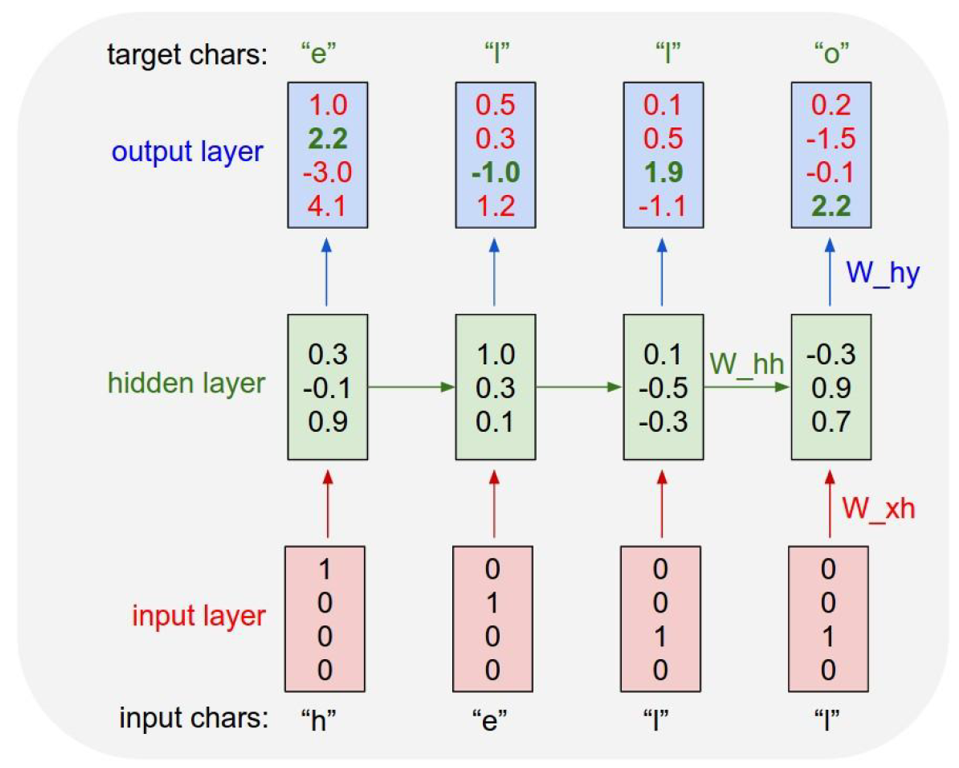
위 그림을 예시로 들어 구조를 설명하면, hell 다음 o라는 글자를 예측하고 싶은 상황이다. 이때 각 알파벳들은 원핫벡터로 표현하여 입력레이어로 들어가게 되는데, 먼저 x1인 (1,0,0,0)을 기반으로 h1인 (0.3, -0.1, 0.9)를 만들게 된다. 이것을 바탕으로 y1인 (1.0, 2.2, -3.0, 4.1)을 생성한다. 이 과정으로 2, 3, 4번째 단계들도 모두 갱신하게 되는데, 이 과정을 순전파라고 한다.
이때 다음 글자를 예측하고자 하므로 h 다음 정답은 e, e 다음정답은 l 이런식으로 정답에 해당하는 인덱스 (그림에서 output layer에 초록색으로 표시된 각각의 숫자들) 를 기준으로 역전파를 진행할 수 있다.
RNN 수식 정리
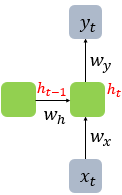
현재 시점 t에서의 히든state값을 ht라고 정의하고, 히든레이어의 메모리셀은 ht를 계산하기 위해 총 두개의 가중치를 가진다. 하나는 입력층을 위한 가중치 Wx 이고, 하나는 이전시점 t-1의 히든state 값인 ht-1을 위한 가중치 Wh이다.
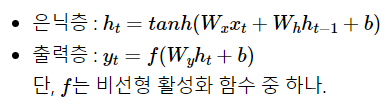
RNN의 은닉층 연산을 벡터와 행렬 연산으로 이해할 수 있다. 입력 x1의 차원을 d라고 하고, 히든 state의 크기를 Dh라 했을 때 각 벡터와 행렬의 크기는 아래와 같다.
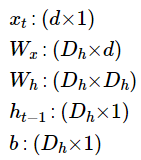

그리고 위 그림은 d와 Dh값 모두 4로 가정하고 표현한 히든레이어 연산을 그림으로 표현한 모습이다.
LSTM (Long Short-Term Memory models)
RNN은 관련정보와 그 정보를 사용하는 지점 사이 거리가 멀 경우에 역전파시 그래디언트가 점점 줄어 학습능력이 크게 저하되는 것으로 알려져 있다. 이 문제를 해결하기 위해 고안된 것이 LSTM이다. LSTM은 RNN의 히든 state에 cell-state를 추가한 구조이다.
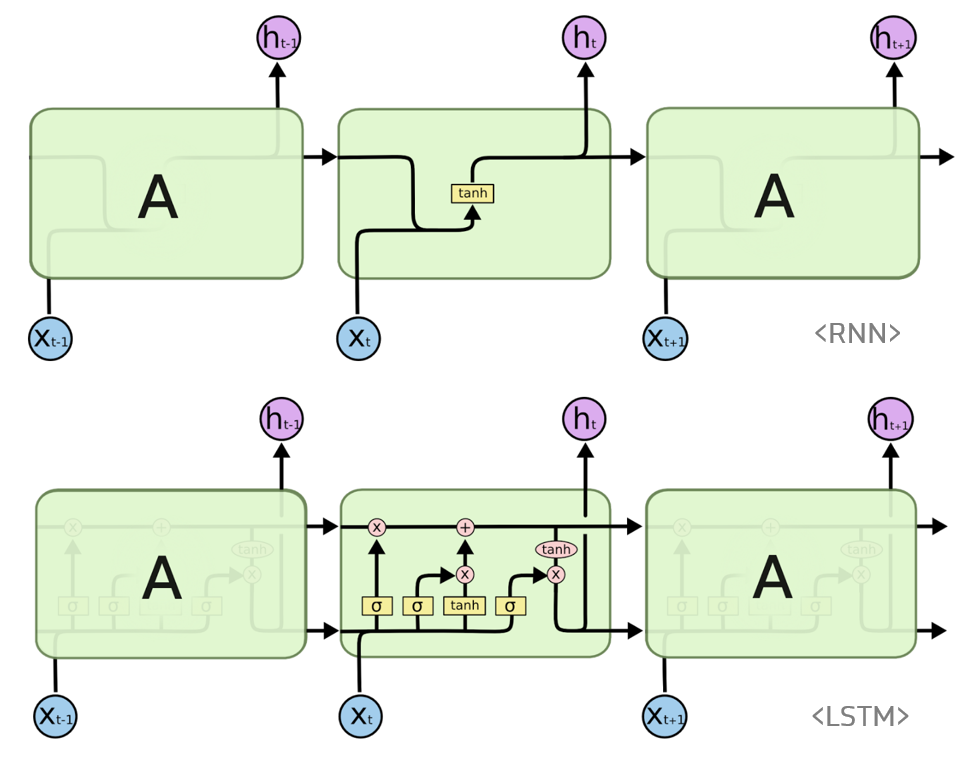
cell state는 일종의 컨베이어 벨트 역할을 한다. 덕분에 state가 꽤 오래 경과하더라도 그래디언트가 비교적 전파가 잘 되게 된다.
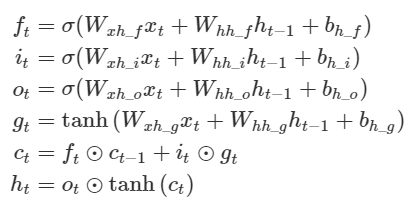
LSTM 셀의 수식을 하나씩 작성한 사진이며,
forget gate ft는 '과거정보를 잊기'를 위한 게이트이다. ht-1과 xt를 받아서 시그모이드 취해준 값이 바로 forget gate가 내보내는 값이 된다.
input gate it⊙gt 는 '현재정보를 기억하기'위한 게이트이다. ht-1과 xt를 받아서 시그모이드를 취하고 또 같은 입력으로 tanh를 취해준 다음 hadamard product연산을 한 값이 바로 input gate가 내보내는 값이 된다. (hadamard product: 같은 크기의 두 행렬의 각 성분을 곱하는 연산)
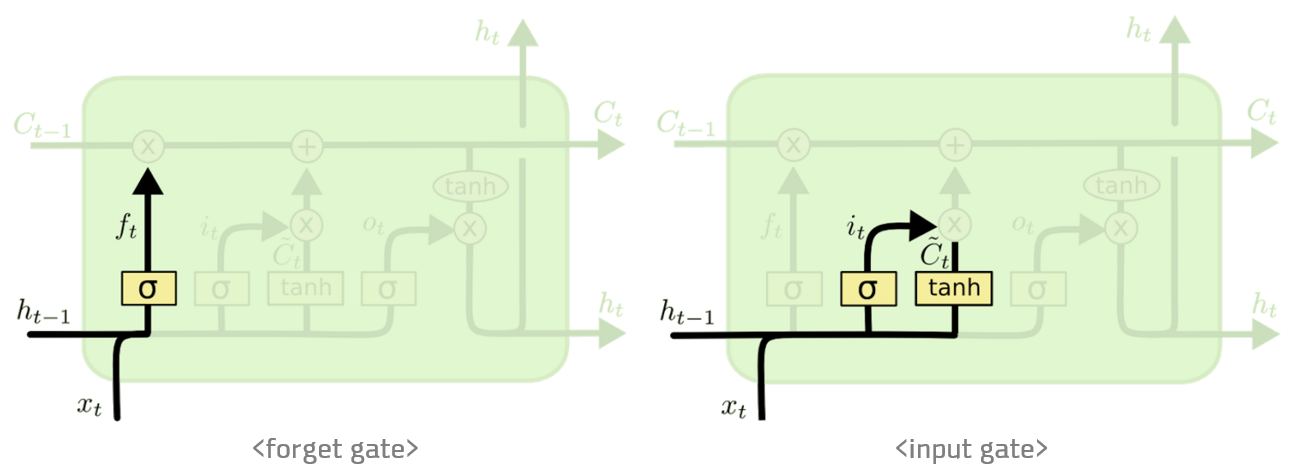

단계별 LSTM 구조
forget gate layer
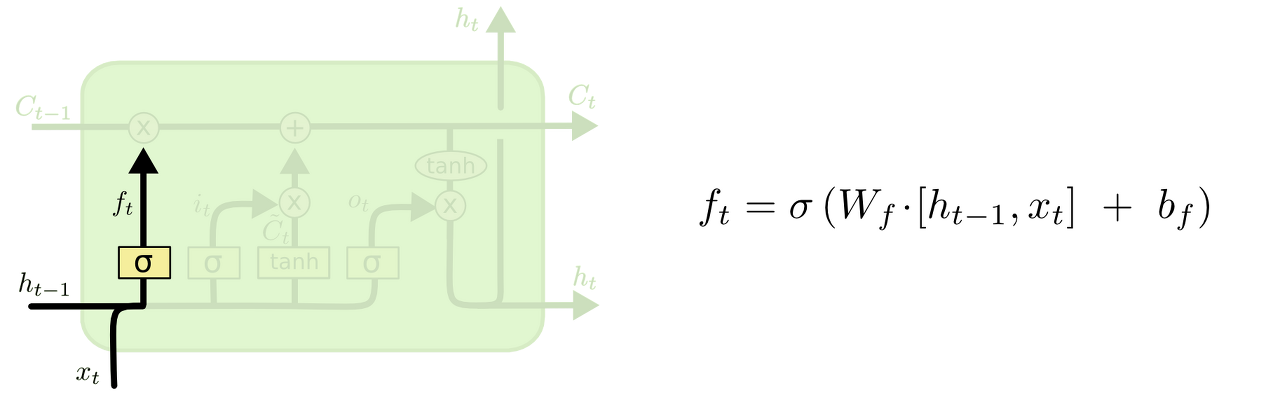
먼저 앞에서 수식과 함께 살펴봤던 forget gate layer이다. cell state로부터 어떤 정보를 버릴 것인지 정하는 것으로, sigmoid layer에 의해 결정된다. 값이 1이라면 모든 정보를 보존, 0이라면 모든 정보를 버리라는 뜻이다.
input gate layer
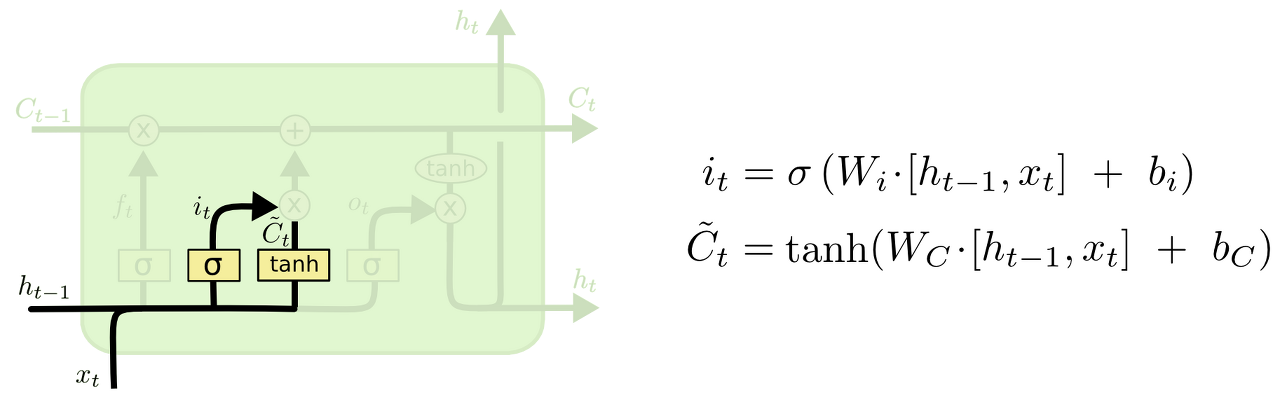
다음은 input gate layer이다. 앞으로 들어오는 새로운 정보들 중에 어떤 것을 cell state에 저장할 것인지를 정하는 것이다. 먼저 input gate layer라고 불리는 시그모이드 layer가 어떤 값을 업데이트할지 정하고, 그다음 tanh layer가 새로운 후보 값들인 Ct라는 벡터를 만들어 cell state에 더할 준비를 한다.
cell state 업데이트
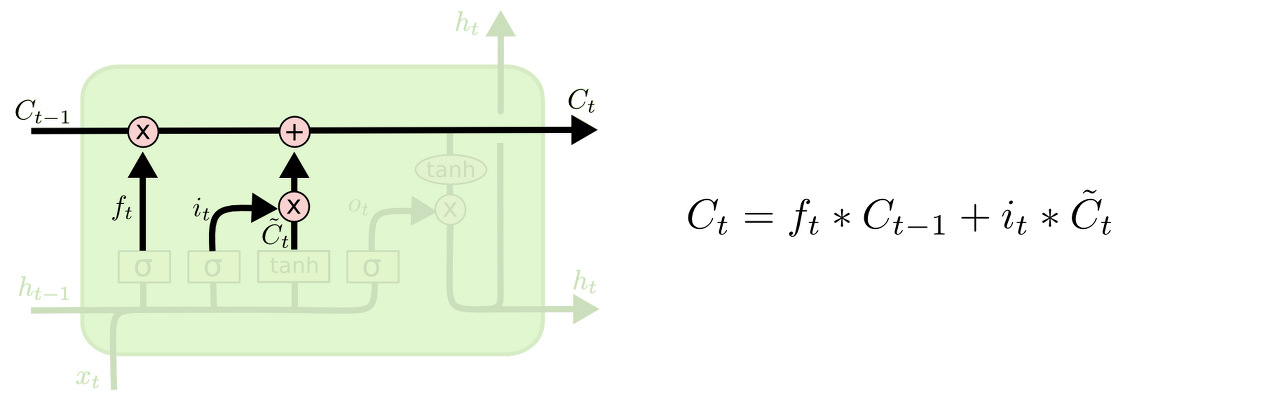
과거 state인 Ct-1를 업데이트해서 새로운 cell state인 Ct를 만들게 된다. 이때 forget gate에서 잊어버린 것들은 잊어버리고, it * Ct를 더하게 된다. 이 더하는 값이 앞서 업데이트 한 값을 얼마나 업데이트 할지 정한만큼 scale한 값이다.
output gate layer
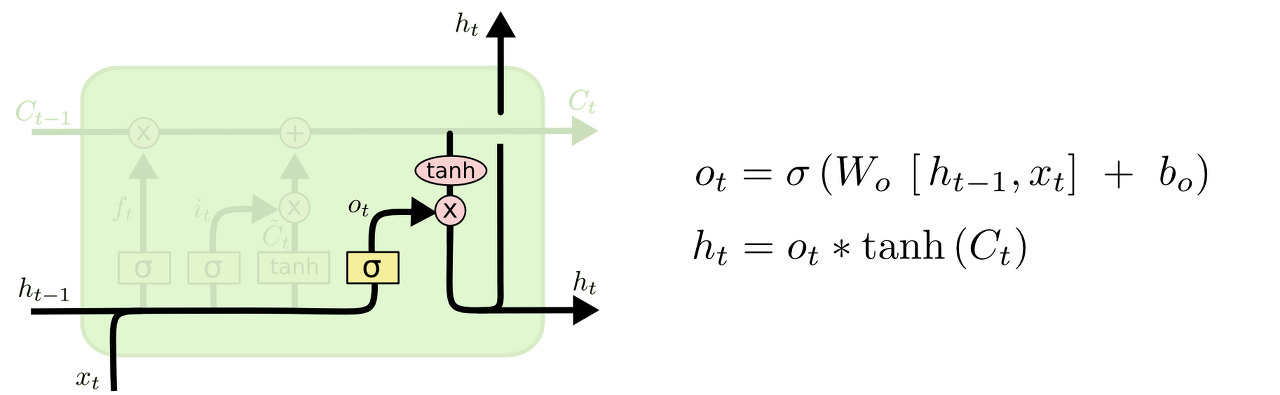
마지막으로, 무엇을 output 으로 내보낼지 정하게 되는데, 먼저 시그모이드 layer에 input데이터를 태워서 cell state의 어떤 부분을 output으로 내보낼지를 정한다. 그 후 cell state를 tanh layer에 태워서 -1과 1사이의 값을 받은 뒤에 sigmoid gate의 output과 곱해준다. 이렇게 해서 output으로 보내고자 하는 부분만 내보내게 된다.
