
개요
OpenAI 에서 최근에 발표한 새로운 버전의 GPT. 텍스트 베이스의 웹 브라우징 환경을 통해서 GPT3를 파인튜닝 하고, 긴 맥락을 가진 질문에 대해서 답을 할수 있는 모델을 제안했다. 이러한 과정에서 이미테이션 러닝이나 강화학습의 개념을 사용였다.
모델의 평가는 ELI5 데이터 셋을 이용하였고, ELI5데이터는 레딧의 유저들의 질문들로 이루어진 데이터세트이다.
파인튜닝 과정에서 언어모델이 인터넷 브라우징을 하기 위해 사람의 행동을 따라했으며(behavior cloning) 사람의 선호를 예측하기 위한 reward model을 학습하기 위해 rejection sampling을 수행했다.
결과적으로 모델이 생성한 답변에 대해서 56%의 인간 demonstrator가 답변한것보다, 69%의 레딧에서 가장 많은 표를 받은 답변보다 사람들이 선호했다.
1. 소개
최근 자연어처리 분야에서 long-form question answering(LFQA) 해결하기 어려운 문제로 남아 있었다. LFQA 시스템은 사람이 세상에 대해 배우는것과 같은 방식을 가졌지만 현재 시스템 측면에서 사람과 비교했을 때 부족한 점이 많이 있다 [최근paper]. 최근의 논문들에서는 정보를 추출하고 합성하는 두가지 컴포넌트로 구성해 해결하고자 하였다.
WebGPT에서는 한발 더 나아가서 이러한 과정에서 이점을 얻기위해 document retrieval 과정에서 MS Bing Web Search API 를 사용한다.
https://www.microsoft.com/en-us/bing/apis/bing-web-search-api
그리고 기존에 학습된 GPT-3를 fine-tuning 하고, 사람의 피드백을 활용해서 답변의 퀄리티를 옵티마이즈 한다.
Key Contributions
- WebGPT에서는 text-based web browsing environment를 개발했다. 이 개발한 브라우징 환경은 파인튜닝된 언어모델과 상호작용할 수 있다. 그리고 이 환경은 이미테이션 러닝과 강화학습을 통해retrieval과 synthesis 모두 개선할 수 있음을 보였다.
- WebGPT에서는 reference를 통해 답변을 생성한다: 브라우징을 이용해 웹페이지로 부터 모델이 passage를 추출한다. 이것은 라벨러가 정답의 실제 정확도를 판단 하는데 중요한 역할을 한다.
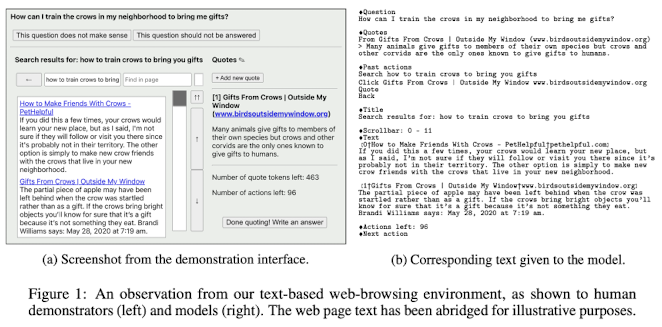
위 화면은 WebGPT에서 사용하는 text-based web-browsing environment이다. 왼쪽의 GUI는 사람이 보는 화면, 오른쪽에 텍스트로 되어있는것은 실제 모델과 상호작용하는 텍스트이다.
WebGPT의 주요한 학습 방법은 ELI5(Explain Like I'm Five)데이터의 질문데 답변하는 것을 통해 학습된다. ELI5 데이터는 Explain Like I'm Five 의 서브 레딧에 대한 질문 데이터이다.
추가적으로 demonstraions 과 comparisons라는 데이터를 수집했는데, demonstraions데이터는 질문에 답변하기 위해 사람이 웹 브라우징 하는 데이터 대한 것이고, comparisions 데이터는 두 모델들이 생성한 답변들에 대해 정확성, 일관성, 유용성들을 평가하는 데이터를 수집했다.
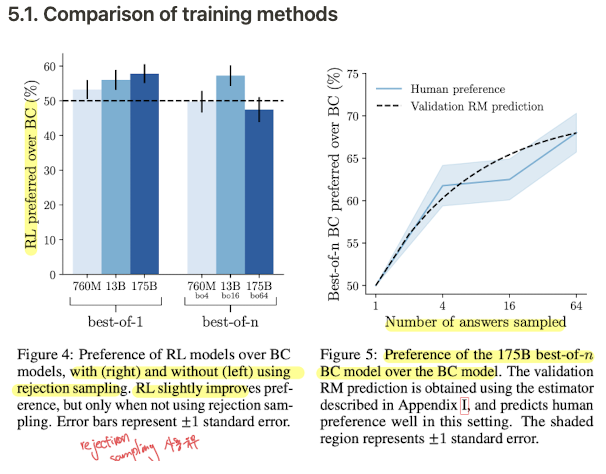
WebGPT에서는 수집한 데이터를 4가지 방법을 실험하는데 사용했다: behavior cloning, reward modeling, reinforcement learning, rejection smapling 그중에 가장 좋은 성능을 보인 모델을 behaviro cloning과 rejection sampling 을 사용한 조합이 가장 좋은 성능을 보였다.
모델을 평가하는데 있어서 3가지 각각 다른 방법을 이용해 평가했다:
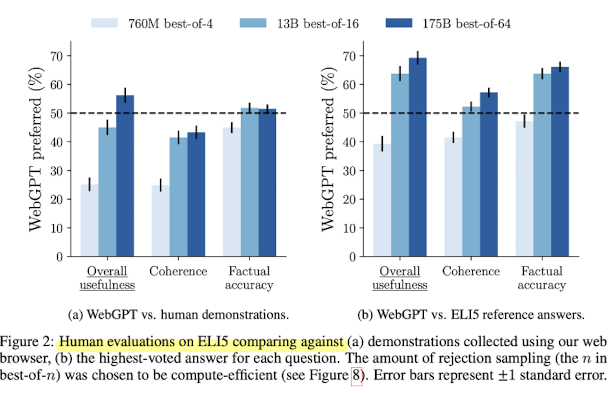
① 모델이 생성한 답변들과 사람이 작성한 답변들에 대해서 비교한다. 이때 모델이 답변한 결과가 56% 더 선호 되었다.
② ELI5 데이터세트로 부터 가장 높은 표를 받은 답변들과 모델이 생성한 답변들을 비교한다. 이 때 공정함을 위해 reference들을 삭제한 후 답변을 생성했다. → 모델의 답변이 69% 더 선호 되었다.
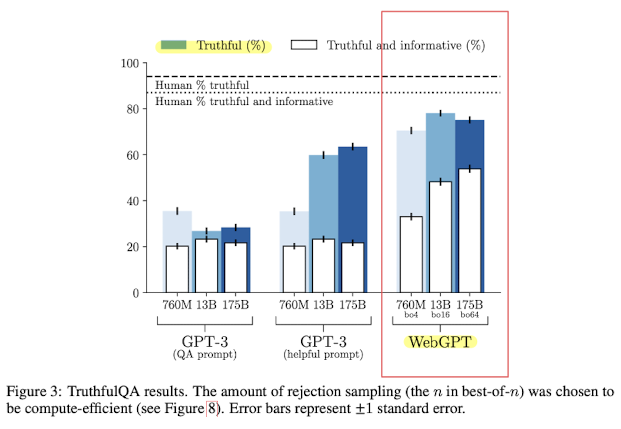
③ TruthfulQA[Lin et al.,2021] 데이터를 통해 평가했다. → 기존 GPT3를 넘고 사람보다는 조금 못한 성능을 보였다.
2. WebGPT의 환경 세팅
기존에는 REALM이나 RAG 논문에서 보여줬듯 주어진 쿼리에 대해 도큐먼트를 retrieval 하는 것에 무게를 두었다. 하지만 WebGPT에서 OpenAI는 documents retrieval 하는 부분은 현대적인 검색엔진(논문에서는 Bing)을 이용했다.
검색 엔진을 사용한 이유는 첫번째로는 이미 너무 잘 동작하기 때문이고, 이 잘 동작하는 검색엔진을 이용한다면 언어모델이 보다 사람을 모사하는데 집중할 수 있기 때문에 검색 엔진을 사용하고자 했다.
하지만 이런 방법을 사용하기 위해서는 텍스트 기반의 웹 브라우징 환경을 개발해야 했다. 언어모델은 환경의 현재 상태, 질문, 커서가 위치하는 현재 페이지의 텍스트, 기타 등등의 정보들을 프롬프트로 사용했다. 그리고 프롬프트 문장들을 통해 모델은 Table 1에서 제시된 명령어를 출력해야한다. 그리고 이 명령어들은 Bing 검색엔진을 사용하기 위한 action들이다.
Table 1. Actions the model can take

이러한 동작들은 새로운 컨텍스트들에 대해서 반복적으로 수행된다. 그리고 컨텍스트 안에서 이전 스텝의 기억은 요약에 기록된 기억들이 유일하다.
모델이 브라우징 하는 동안, 현재 페이지로부터 추출된 정보를 인용하는 것을 하나의 action으로 취할수 있고, 이것이 수행될때 페이지의 제목, 도메인 이름들은 후에 reference 로 저장 된다. 그리고 브라우징은 브라우징이 끝나는 명령어가 출력되거나 최대 액션의 수에 다다르거나, 레퍼런스의 길이가 최대 길이에 도달할때 멈추게 된다.
최종적으로 하나의 레퍼런스라도 있는경우 모델은 질문과 레퍼런스를 프롬프트로 하여 최종 답변을 생성한다.
3. WebGPT가 사용한 방법들
3.1. 데이터 수집
기존의 사전학습된 언어모델들은 논문에서 새로 개발된 텍스트 베이스의 브라우저에 사용할수가 없었기 때문에 질문에 대해 답변하기 위해 사람의 데이터를 수집했다. 이때 수집된 데이터를 demonstraions 라 명명한다. 하지만 이 데이터를 통해 답변의 퀄리티를 직접적으로 최적화 할 수 없었고, 사람의 퍼포먼스를 뛰어넘을수 있을거 같지도 않았다.
따라서 동일한 질문에 대해 모델이 생성한 답변들에 대한 쌍을 수집하였고, 이 쌍에 대해 어느쪽을 더 선호하는지 사람에게 라벨링을 시켰다. 이 데이터를 comparisions 라고 부른다.
위 두 데이터의 대부분의 질문은 ELI5르 기반으로하고, TriviaQA 데이터도 조금 섞어서 사용했다.
Table 2. 랜덤하게 선택된 질문에 대해 175B 모델이 생성한 답변.

사람들이 보다 쉽게 사용하기 위해 그래픽 기반의 인터페이스를 개발했고, 모델에 사용되는 텍스트에서도 동일한 정보를 보여준다.
3.2. 학습
모델의 학습에서는 언어모델의 성능이 매우 중요하기 때문에 기존에 학습된 GPT-3를 사용했다. 모델의 사이즈는 760M, 13B, 175B 모델 사이즈에 맞춰서 학습했다.
학습 방법
- Bahavior Cloning(BC): demonstarations 데이터에 대해 파인튜닝.
- Reward Modeling(RM): BC Model의 마지막 unembedding layer를 제거한 후 레퍼런스들을 이용해 질문과 답변을 통해 학습하는 모델로 출력으로 스칼라 값을 가지는 reward를 반환한다.
- Reinforcement Learning(RL): BC Model을 PPO를 이용해 파인튜닝한다. reward model이 각 에피소드가 끝날때의 reward score에 BC Model과의 KL 페널티를 더해 학습에 사용한다.
- Rejections Sampling(best-of-n): 고정된 숫자(4,16,64)의 답변들을 BC model또는 RL model로 부터 샘플링한다. (만약 부족한경우 BC model을 사용한다.) 그리고 reward model 로부터 가장 높은 점수를 가진것을 사용한다.
4. Evaluation
4.1. ELI5
4.2. TruthfulQA
5. Experiments
5.1. Comparison of training methods
5.2. Scaling experiments
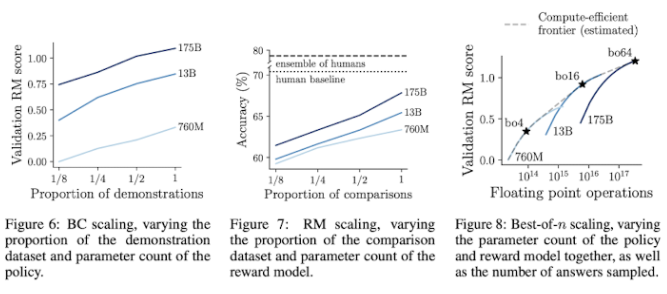
6. Discussion
논문 참고
7. WebGPT 이전의 시도들
머신 러닝 분야에서 외부 지식을 결합하는 기술들은 2010년대 후반 부터 보이기 시작했으며, 대표적으로 DeepQA(IBM Watson)와 같은 시스템들이 있다. IBM의 왓슨은 Jeopardy에서 사람을 물리친 시스템이 되었다.
최근 시도되는 방법들에서는 내적을 이용해 관련된 문서들을 찾고, 주어진 문서들로 답변을 생성하는 방법들을 사용했다. DPR, REALM , RAG 와 같은 방법들이 있다.
이러한 방법들과 다르게 Krishna et al. 2021에서는 ELI5 데이터에 대해서 유사한 시스템을 사용했고, ROUGE-L과 같은 automated metric이 의미 있지 않다는 것을 발견했다. 이러한 부분 때문에 OpenAI WebGPT 저자들이 주요한 metric으로 human comparisions를 사용하는 선택을 하게되었다.
8. 결론
WebGPT는 long-form QA에서 언어모델을 텍스트 기반의 웹 브라우징 환경을 사용해 파인튜닝 하는 새로운 접근 방식의 유효함을 보였다. 이러한 접근 방법을 통해 이미테이션 러닝과 강화학습과 같은 일반적인 방법을 통해 답변의 퀄리티를 직접적으로 높일 수 있음을 보였다. WebGPT의 best model에서는 ELI5 데이터에 대해서 사람의 능력을 뛰어 넘는 성능을 보였다. 하지만 여전히 데이터 바깥에 속하는 질문들에 대해서는 잘 답변하지 못하는 제한 사항도 존재한다.

정말 멋지네요. 질문에 답하기 위해 검색까지 자동으로 한다니, 비서+직원이 따로 없네요. 소개 감사합니다.