ReZero is All You Need
개요
딥 뉴럴 네트워크는 여러 분야에 걸쳐서 많은 성능 향상을 가져왔지만 종종 기울기가 사라지거나 과도하게 커지거나 하는 문제가 발생한다. 특히 12 레이어를 초과하고 많은 데이터셋과 컴퓨팅 자원이 필요한 트랜스포머 모델들도 이런한 문제에서 예외는 아니며, 저자들은 비효율적인 신호가 학습을 방해하는 것을 발견했다. 특히 트랜스포머의 멀티헤드어텐션에서 주요하게 나타났다.
성과
- ReZero는 백단위 레이어가 넘는 네트워크에 대해서도 학습할수 있게 한다.
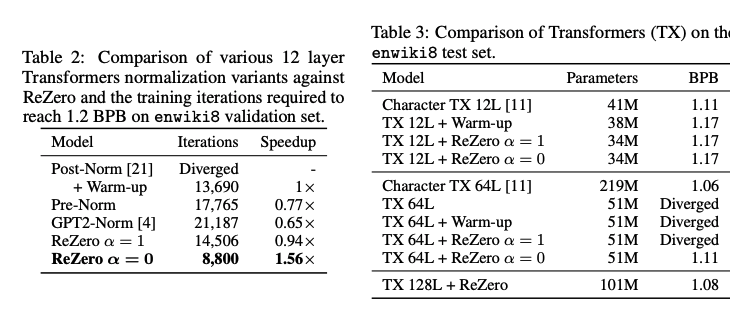
- 12레이어를 가진 트랜스포머에 ReZero를 적용한 경우 enwiki8에서 56% 빠르게 수렴한다.
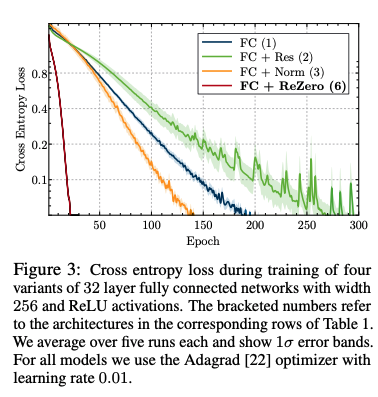
- Deep fully connected network에 1500% 빠르게 수렴할 수 있게 적용수 있으며, CIFAR 10 ResNet-56에 대해 32% 빠르게 수렴하게 한다.
적용
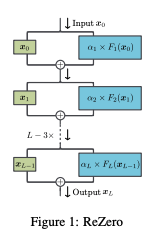
Rezero is all you need 논문은 간단한 방법을 통해 ResNet을 효과적으로 개선하는 방법을 제안 한다. 기존에 Residual Connection에서 레이어의 출력에 residual parameter라는 새로운 숫자 하나를 곱해주어 ResNet을 수행한다.
이때 Residual Parameter를 0으로 초기화 하고, 모델을 학습하는동안 학습 될수 있는 파라미터가 되게 한다.
ReZero는 추가적으로 기존의 뉴럴넷에 작은 변경을 통해 적용할 수 있다. 레이어에서 residual connection이 있는 곳에 입력 에 대해서 학습할수 있는 파라미터 을 이용해 아래와 같은 수식으로 적용할 수 있다.
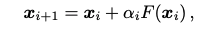
처음에 으로 초기화 되어 학습을 거친다. 최초에는 함수 의 모든 파라미터들에 대해 그래디언트 값이 희미하지만 학습에 초기 부분에 드라마틱하게 값이 안정적으로 변하는 것을 볼수 있다.
ReZero 장점
-
Deeper learning: 일반 fully connected network에는 10000 레이어를 학습할 수 있다. 그리고 트랜스포머 모델 학습시에 learning rate 웜업과 LayerNorm을 사용하지 않고, 100개의 레이어를 학습할 수 있다.
-
Faster convergence: ReZero를 사용한 네트워크의 경우 기존의 residual 네트워크와 normalization을 사용한 것에 비해 빠르게 수렴한것을 확인했다.
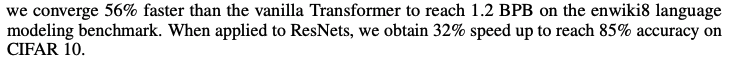
마무리
ReZero에 대해 간략하게 알아보았고, 논문에서 제시한 소스 코드를 통해 기존에 사용하는 트랜스포머 모델 개선에 적용해본다.
참고
자세한 내용은 하단의 논문 링크를 참조.