
Meta Learning이란?
Learn to learn으로 적은 데이터로 학습하기 위한 방법. 기존에도 존재해 왔으나 Deep Learning과 결합하여 로봇, 강화학습, GPT-3 등에 적용 되며 뛰어난 성능을 보이고 있다. CS330을 통해 학습 및 정리해본다.
Case Study
- Multi Objective learning in Youtube recommendation system
- Few-shot learning from GPT-3
필요한 내용
- CS229 강의
- RL 지식
- Tensorflow 2.0
다루는 주제
- Multi-task learning, transfer learning basics
- Meta-learning algorithms
(black-box approaches, optimization-based meta-learning, metric learning) - Advanced meta-learning topics
(meta-overfitting, unsupervised meta-learning) - Hierarchical Bayesian models & meta-learning
- Multi-task RL, goal-conditioned RL
- Meta-reinforcement learning
- Hierarchical RL
- Lifelong learning
- Open problems
왜 멀티 태스크 러닝과 메타러닝을 배워야 하는가?
딥러닝이 가진 장점
이미지, 언어, 센서 등과 같이 구조화 되지 않은 입력을 다룰때, 적은 도메인 지식들과 사람이 일일이 조정해야하는 부분이 적기 때문에 딥러닝이 많은 장점을 가진다.
그 예로 이미지 처리에서는 사람이 수많은 feature들을 수작업하고, SVM 모델에 사용해 분류 했지만, 지금은 딥러닝을 통해 보다 사람 손이 덜 가게 동작한다.
메타러닝과 멀티태스크 러닝을 왜 배워야 하는가?
현재의 대부분 딥러닝 시스템들은 일종의 한가지 태스크에 대해 잘 하는 스페셜리스트라고 볼수있다.
하지만 사람은 어떤한 일에도 잘 학습하는 제너럴리스트라고 볼수 있다.
실제 환경에서는 다양하고 큰 데이터 세트를 가진 환경이 아닌, 제한된 사항에서 범용적으로 적용할 수 있는 시스템들에 대한 필요하고, 아래와 같은 경우에 메타러닝이 적절한 방법이 될수 있다.
데이터가 많지 않는 경우
이미지넷이나, GPT-2와 같이 많고 다양한 데이터들을 가진 경우,아래 이미지와 같이 generalization을 충분히 잘 할 수 있다.

하지만 우리가 많은 데이터를 갖지 못한 경우 어떻게 학습할 수 있을까? 의료 이미지, 로봇, 희귀 언어에 대한 번역, 추천 등 여러 분야들에 대해서는 데이터가 많지 못한 경우가 많다.
데이터들의 분포가 적은 데이터들로 길게 늘어져 있는경우
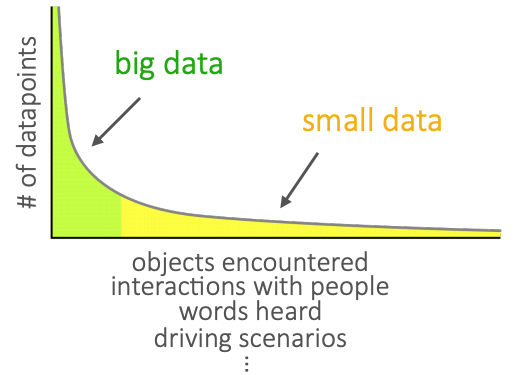
위와 같이 small data인 분야들에 대해서는 일반적인 machine learning을 적용하기 어려운 점들이 존재한다.
새로운 것을 빨리 배워야 하는 경우

위와 같이 바로크와 세잔의 그림을 적은 데이터 수를 가지고 맞춰야 하는 경우 어떻게 할 수 있는가?
보다 범용적인 AI 시스템을 원하는 경우
태스크란?
기존의 태스크들은
- 데이터셋 와 Loss 함수을 이용해
- model 를 학습하였다.
서로 다른 태스크들은 object, people, objectives, light conditions, word, language 들에 따라 다를 수 있지만 단지 다른 태스크들이 아니다
Critical Assumption
-
안좋은점: 서로 다른 태스크들은 어떤 구조들의 공유가 필요하다.
-
만약 그렇지 않다면 single-task learning을 사용하는 것이 더 낫다.
-
강의에서도 구조를 공유할 수 없는 경우 처음부터 배우는 것보다 더 빨리 배울 수 없다고 한다.
-
-
좋은점: 구조들을 공유하는 많은 태스크들이 있는것이다

뚜껑을 덮는것, 뚜껑을 조이는것, 후추 그라인더를 돌리는것과 같은 세가지 동작에서 같지만 서로다른 부분이 있고, 이중에서도 공통으로 생각되는 구조들이 있다.
관련없지만 어떤 구조적인 공통적인 것을 갖는것들
- 현실 데이터에 기반한 물리 법칙들
- 사람은 모두 어떠한 의도를 가진 유기체라는것
- 영어 언어 데이터에 기반한 영어의 법칙들
- 많은 언어들이 비슷한 목적으로 개발된 점.
중요한 점은 어떤 공유될 수 있는 구조를 찾는것이 중요하고, 만약 그렇지 못한다면 메타러닝의 목적에 맞게 빨리 배우지도 못할것이며, 싱글 태스크 러닝을 사용하는 것보다 못할 수도 있을것이다.
대략적인 문제 정의
보다 공식적인 문제 정의는 다음 강의에서 진행할것으로, 먼저 대략적으로 핵심 아이디어를 전달하기 위해 사용.
- Multi-task learning: 모든 태스크들에 대해 독립적으로 학습하는 것, 보다 빠르고 효율적으로 학습하는것
- Meta-learning: 이전 태스크들에서 주어진 데이터와 경험들을 바탕으로 새로운 태스크들을 보다 빠르고 효율적으로 학습하는것
왜 지금 배워야 하는가
- 오래전부터 있던 방법으로 새로운 알고리즘은 아니다.
- 하지만 메타 러닝의 경우 적은 데이터셋으로 학습할 수 있고, 최근 딥러닝과 결합되어 여러가지 분야에서도 많이 접목되어 사용되고, 성과를 보이고 있다.
- 그리고 적은 데이터를 기반으로 학습할수 있는것은 큰 장점이기 때문
