
how to generate text 를 보며 정리
huggingface의 transformer 라이브러리를 보면 GPT2 부분에 generate 함수가 있다. 이 generate 함수를 이용해서 문장 생성 하는데 보다 적은 노력으로 훌륭한 문장을 생성할 수 있다.
auto-regressive
문장(시퀀스)의 확률

- 문장A: GPT2는 문장을 생성한다
문장을 확률로 표현하고 싶을때, 위 문장 A를 예를 들면, 이 문장의 확률은 과 같이 조건부 확률의 곱으로 생각할 수 있다.
auto-regressive
auto-regressive은 문장의 확률값을 구하듯이 이전의 단어들로 다음 단어의 확률을 예측하면서 방식을 말한다. 현재 transformers에서 auto-regressive 언어 생성을 사용할 수 있는 모델은 GPT2, XLNet, CTRL, TransfoXL, Bart, T5등이 있다.
원 글에서는 tf로 작성했지만 torch로 변환
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)Greedy Search
이전 단어로 예측한 다음 단어의 확률값 중 가장 높은 확률 값을 지닌 단어를 선택하는것.
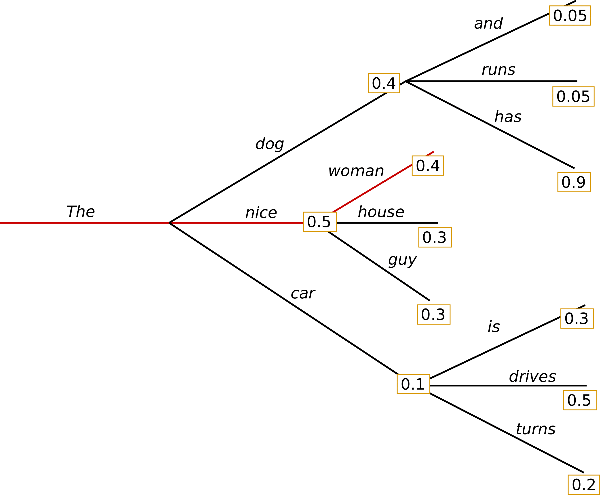
위 사진에서 가장 큰 값을 따라가게 되면 The, nice, woman이 선택되게 되고 이때 생성된 문장의 확률값은 the다음에 nice의 0.5 * the nice 다음에 woman의 확률값 0.4를 곱한 0.2이다.
Greedy Search 예
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='tf')
# generate text until the output length (which includes the context length) reaches 50
greedy_output = model.generate(input_ids, max_length=50)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))결과
결과 뒤쪽에서 볼수 있듯이 생각보다 빠르게 반복이 생긴다.
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with my dog. I'm not sure if I'll ever be able to walk with my dog.문제점
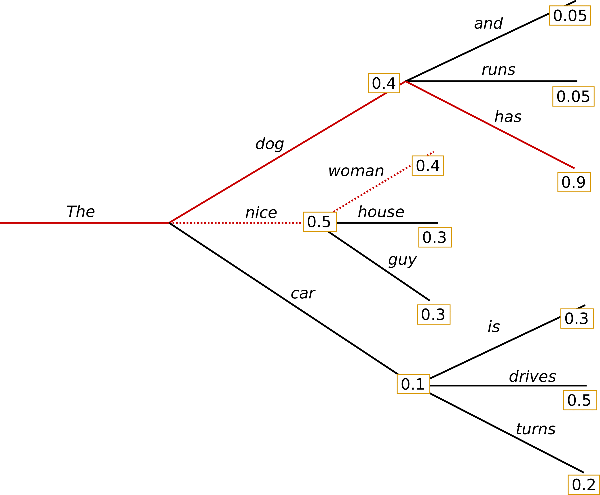
greedy 탐색의 문제는 그 뒤에 나오는 높은 확률 값의 문장을 놓치게 되는 점이 있다.
예를 들면 (the, nice, woman)과 (the, dog, has)의 값을 비교 해보면 the dog has의 값이 0.4 * 0.9 = 0.36으로 the, nice, woman의 값보다 높지만 생략되게 된다.
그래서 Beam Search 방법을 이용해 그리디 탐색의 문제를 완화할 수 있다.
Beam Search
빔서치는 탐색 중에 뒤에 숨겨진 높은 확률을 가진 값을 놓치는 것을 줄여준다. 이때 빔 값은 매번 선택하는 단어의 갯수이다. 선택은 확률 값이 높은 순서대로 하며, num_beams가 2인 경우, 다음 2가지 확률값이 높은 단어에 대해서 탐색한다.
("The","dog","has") 에서는 0.36 ("The","nice","woman")에서는 0,2로 위 빔 서치와는 다르게 ("The","dog","has")값이 선택 되었다.
사용예
# activate beam search and early_stopping
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
early_stopping=True
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))결과와 n-grams penalty
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again. I'm not sure if I'll ever be able to walk with him again. I'm not sure if I'll앞선 결과보다 조금 낫지만 여전히 후반부에는 반복을 포함하고 있다. 그래서 n-grams penalty 방법을 이용한다. n-grams penalty는 n-gram 에서 두번 나오는것을 방지한다.
n-grams penalty 사용 예
n-gram = 2로 세팅한 경우
# set no_repeat_ngram_size to 2
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
early_stopping=True
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
{kind=link}