🛒 Python Crawling
- 오늘은 친구의 부탁으로 웹 상의 정보를 긁어와 엑셀에 정리하는 작업을 해 보았다.
- crawling은 requests, beautifulsoup4 패키지가 필요로 하다.
- python crawling 결과를 엑셀에 저장하는 것은 openpyxl 패키지가 필요로 하다.
- 이에 대해 알아보고 직접 크롤링 해보자~!
- 참고 블로그 : 간토끼의 기술블로그
🎁 패키지 이해하기
Requests
- 가져오고자 하는 데이터가 담긴 웹 사이트를 파이썬을 통해 요청할 수 있다.
- 즉, 웹 사이트 url을 인식하여 데이터를 요청하고, 요청한 데이터를 받아온다.
- 설치 방법 :
pip install requests requests.get(URL)
BeautifulSoup4
- HTML 코드를 인식하여 원하는 데이터를 선택하고 수집할 수 있다. (이를 파싱 Parsing 이라고 한다.)
- 설치 방법 :
pip install beutifulsoup4 BeautifulSoup(requests로 받아온 정보, "html.parser")
Openpyxl
- 본래 엑셀 같은 스프레드 시트 형식의 데이터를 다룰 수 있는 패키지는 판다스(Pandas)로 잘 알려져 있다.
- 판다스를 통해 python으로도
데이터 프레임 형식을 다룰 수 있도록 해준다.(R처럼) - 이와는 살짝 달리 openpyxl의 경우에는
엑셀을 파이썬에서 다룰 수 있도록 하는 패키지이다. - 설치 방법 :
pip install openpyxl wb = openpyxl.Workbook(),sheet = wb.active,sheet.append(arr)...
💡 Crawling
웹 페이지 분석
-
위에서 설명된 패키지들을 이용하여 웹 상의 정보를 가져와보자.
-
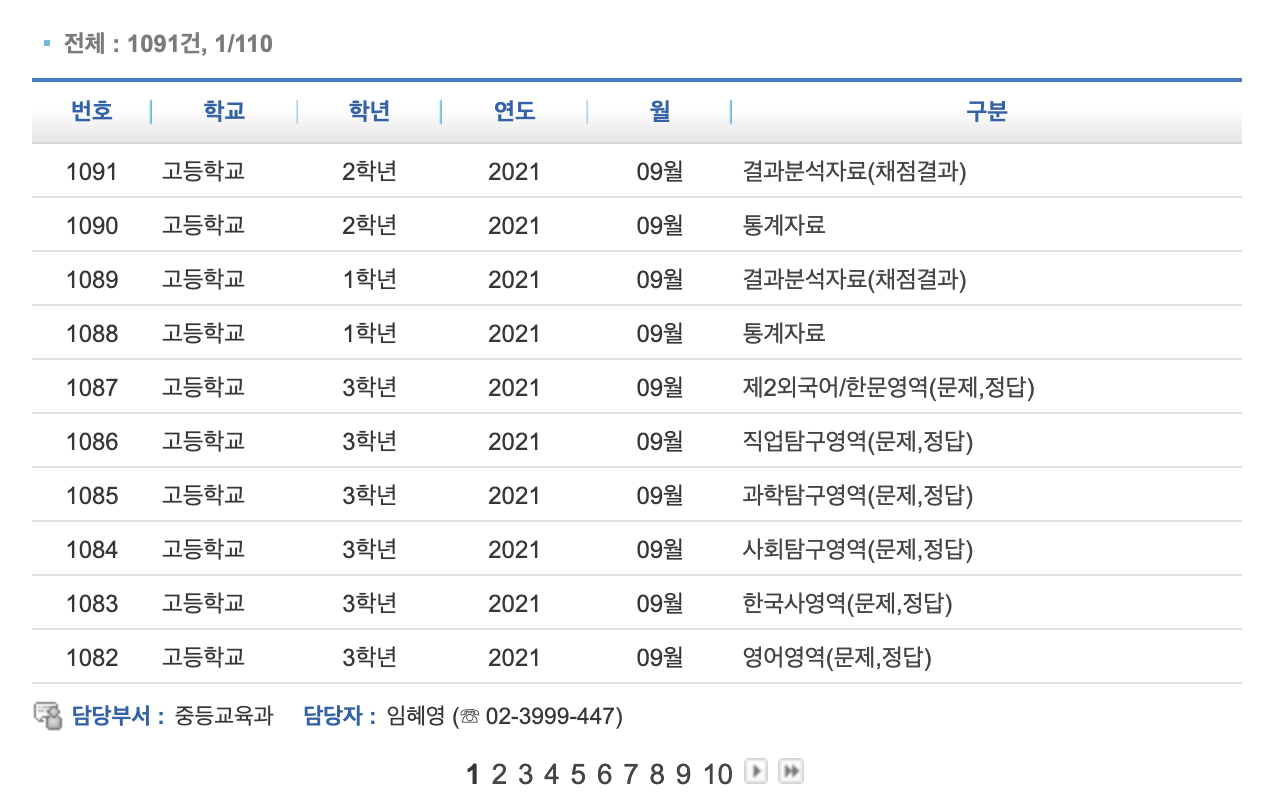
우선 웹 상에서 표 데이터에 해당하는 정보를 그대로 옮겨볼 것이다.
-
표를 그대로 옮기면 되기 때문에 비교적 쉬운 난이도이다.
-
데이터는 한 페이지 당 10개씩 있고, 총 110페이지가 존재한다.
-
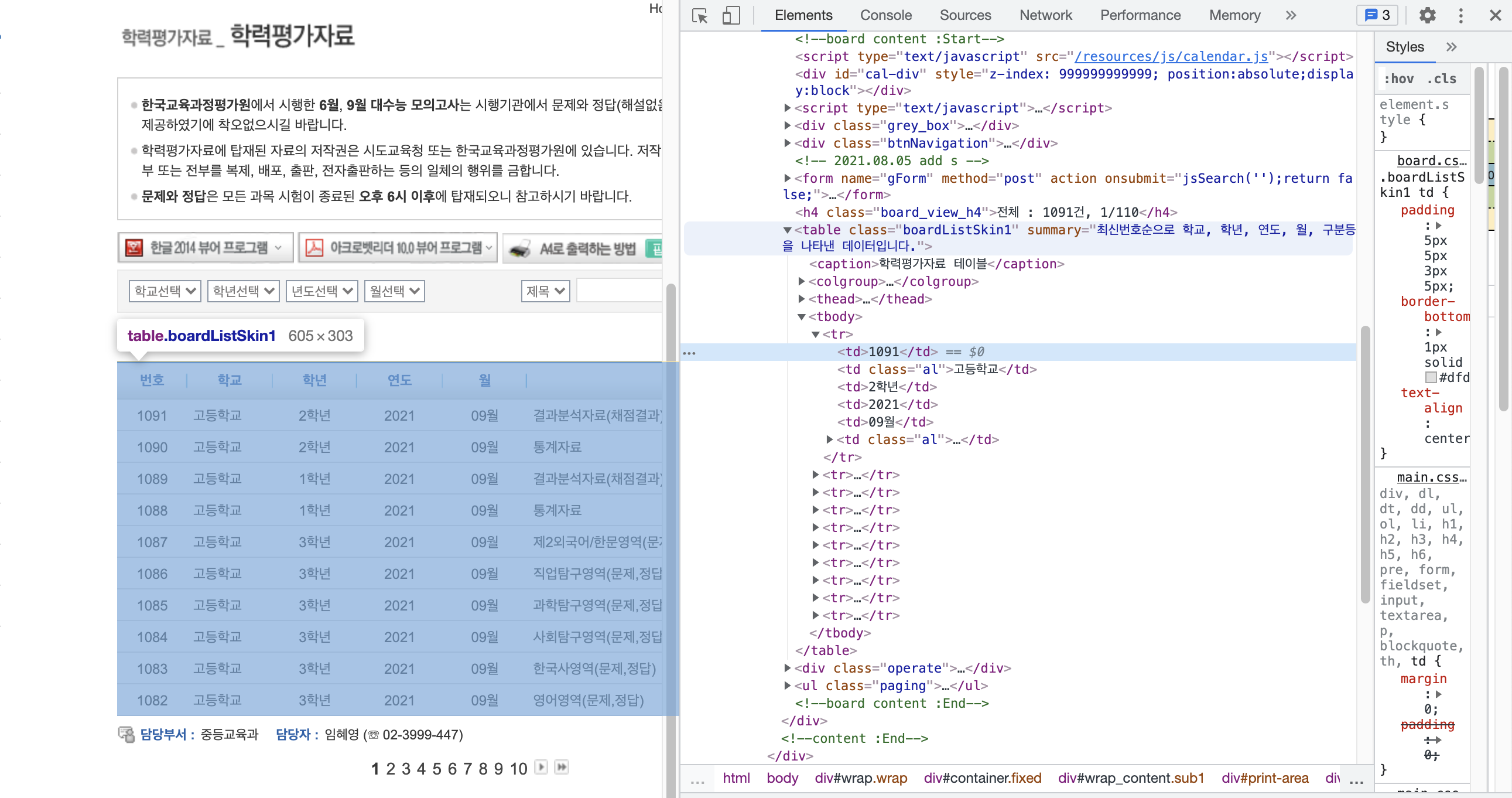
내가 가져오고자 하는 데이터의 HTML 태그를 분석한다.
-
html tag
table.boardListSkin1 > tbody > tr > td🐍 Python Code
- 위 분석을 바탕으로 코드를 짜보자.
# 서울특별시 교육청 학력평가 자료 목록 크롤링 후 엑셀 파일 저장
# 1. 패키지 install
# pip install requests
# pip install beutifulsoup4
# pip install openpyxl
import requests
from bs4 import BeautifulSoup
import openpyxl
# 2. 내가 작업할 Workbook 생성하기
wb = openpyxl.Workbook()
# 3. 작업할 Workbook 내 Sheet 활성화
sheet = wb.active
# 4. 데이터 프레임 내 header(변수명) 생성
sheet.append(["번호", "학교", "학년", "연도", "월", "구분"])
# 데이터 크롤링 과정
for p in range(1, 111, 1):
if p != 1:
p = int(str(p-1) + "1") # 1 11 21 31 ... 1091 이렇게 증가함
raw = requests.get(f"https://www.sen.go.kr/web/services/bbs/bbsList.action?bbsBean.bbsCd=105&searchBean.searchKey=&appYn=&searchBean.searchVal=&searchBean.startDt=&startDt=&searchBean.endDt=&endDt=&ctgCd=&sex=&school=&grade=&year=&month=&schoolDiv=&establDiv=&hopearea=&searchBean.deptCd=&searchBean.currentPage={p}")
html = BeautifulSoup(raw.text, "html.parser")
container = html.select("table.boardListSkin1 tbody tr")
for c in container:
temp = c.find_all("td")
arr = []
for t in temp:
arr.append(t.text)
sheet.append(arr)
# 작업 마친 후 파일 저장(파일명 저장시 확장자 - .xlsx 필수!)
wb.save("new_test.xlsx")- 페이지 url path가 1, 11, 21, 31, ... 1091(총 페이지 수 110)으로 변하기 때문에 파이썬을 통해 for문을 돌 때 변수로 잘 들어갈 수 있도록 설정해주었다.
- 해당 정보를
select(html 태그)를 통하여 container에 담아주고, container의 원소를 하나씩 꺼내서 td 속의 text를 추출하였다. - 그리고 임시 리스트에 순서대로 넣어 준 뒤
sheet에 append 해주었다.
📊 Excel
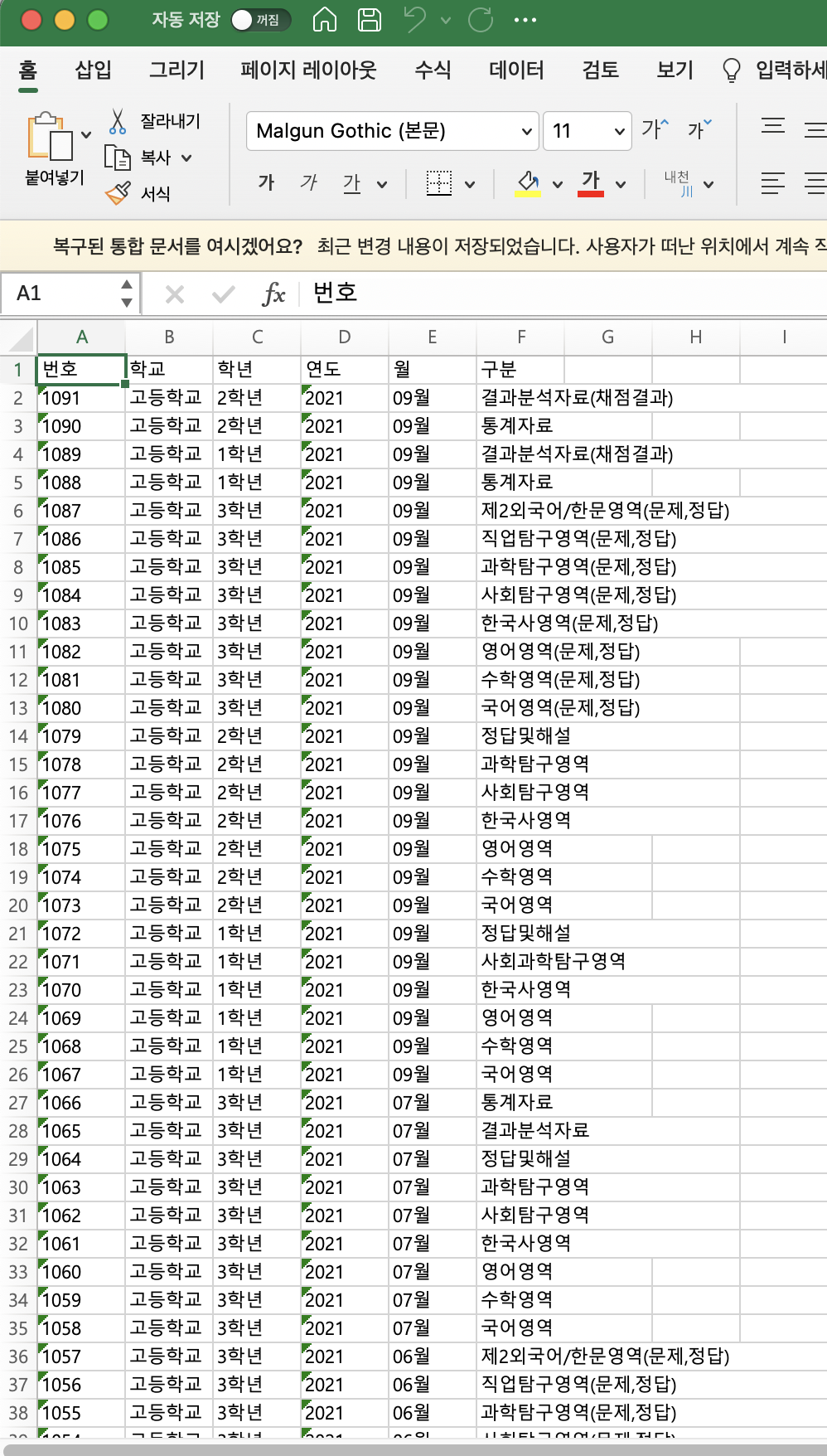
- 위의 파이썬 코드를 실행시켜보면 아래와 같이 잘 저장됨을 확인할 수 있다!
😊 느낀점
친구의 부탁으로 도전해 보았다. 사실 크롤링을 작년 이맘때 쯤 살짝 맛만 본 상태라 자신이 없었지만, 표를 엑셀로 그대로 옮기면 된다는 생각이 들어 시도하게 되었다.
생각보다 구현하는 것이 간단했고, 가져오려는 웹의 url이 페이지마다 어떻게 변하는지를 체크하고, 어떤 html tag로 구성이 되어있는지를 확인하는 것이 핵심이었다.
이번 기회를 통해 도전하는 것에 대한 자신감이 생겼고, 어떤 일이 있더라도 구글링과 사전 지식의 조합으로 해결 할 수 있을 것이란 믿음이 생겼다.
다음 번에는 selenium을 통해 직접 웹을 driver로 켜보고, 자동으로 클릭 및 동작을 하는 것을 해보려고 한다.

나는 날마다 모든 면에서 점점 더 나아지고 있다.