
나의 첫 TIL, 오늘 배운 내용을 회고해 보겠다.
Git
Git이란?
깃이란 형상관리 도구(Version control system) 중 하나로 파일을 트래킹하는 방식이며, 깃허브랑은 다른 개념이다.(이에 비해 github는 깃파일들을 업로드 하는 등의 다양한 기능을 제공하는 플랫폼이다)
병렬적인 개발이 가능하여 협업에 장점을 가지며 체계적으로 버전을 관리하기 용이한 장점이 있다.
Git 명령어
처음에 git명령어를 배웠으나 VSC의 깃관리 툴을 자주 사용하다보니 가물가물해졌다. 이 기회에 제대로 알아보자.
- add : 수정한 코드를 working area(작업 공간)에서 staging area(커밋될 예정인 영역)으로 스테이징하는 명령어이다. (add . : 모든 수정사항을 스테이징)
- commit : 변경사항을 확정하고 git commit -m "메세지" 를 이용해 설명을 추가할 수 있다.
- branch : 깃 브랜치를 다루는 명령어 ( -r : 원격 브랜치 목록 보기, -a : 로컬 브랜치 목록 보기, -m : 브랜치 이름 바꾸기, -d : 브랜치 삭제하기 )
- checkout : 브랜치를 선택하는 명령어로, 구버전의 명령어이다. (현재는 밑에서 소개하는 switch와 restore로 나누어졌다고 한다)
- switch : 브랜치를 변경/생성하는 명령어 (추가로, -c를 붙여주면 새로 생성할 수 있다 )
- restore : 작업 트리에서의 수정 내용을 취소하는 명령어 (추가로, --staged 파일명 : 스테이징 사항을 되돌릴 수 있다)
- merge : 여러 브랜치를 헤드에 통합하는 명령어 (여기서 헤드란 여러 저장소와 브랜치 사이에서 자신이 어디서 작업 중인지 알려주는 포인터와 같은 역할을 한다)
Git 명령어 사용 과정
- 깃허브에서 새로운 레포지토리를 만든다.
- 콘솔을 사용하여 적당한 위치로 이동해준다. (cd 디렉토리명)
- git clone URL <생성할 디렉토리명>을 입력하여 레포지토리를 해당 위치에 복사한다.
- 파일 수정 후 git add 를 이용해 스테이징화 해준다 ( 보통은 git add . 로 전부 스테이징화)
- git commit -m "설명" 을 이용해 로컬 저장소에 커밋해준다.
- git push origin <브랜치명> 입력하여 원격저장소에 푸쉬해준다. (겹치는 커밋으로 인해 오류가 생기는 경우 -f를 추가하여 강제 푸쉬를 해주기도 한다)
* git add와 git commit시 Git의 내부 동작
-
git object
git object는 크게 3가지가 있는데, 파일의 내용을 담는 blob, 스테이지 영역의 정보를 저장하는 tree, 커밋 정보를 저장하는 commit이 있다. -
git add
git add 명령은 현재 작업공간의 파일과 commit된 버전과의 차이가 있음을 알려주는 동작으로서 스테이징 영역에 추가하게 되고 파일을 blob 오브젝트로 저장한다. 저장된 파일은 .git/index 파일에 <파일모드> <해시> <파일명> 형태로 기록된다. -
git commit
git commit 명령은 git에 변경된 파일이 있음을 명시하는 동작이다. 따라서 commit을 하면, 그 전까지 add한 파일들이 해당 commit에 기록된다. git commit -m "message" 가 실행되면 새로운 tree 오브젝트를 생성하고 커밋된 시점의 index 정보를 저장한다.
생성된 tree 오브젝트를 SHA-1 알고리즘으로 해시하고 .git/objects 디렉토리에 저장한다.
SHA-1
SHA-1은 SHA-0의 압축 함수에 비트 회전 연산을 추가한 것이다. SHA-0와 SHA-1은 최대 264비트의 메시지로부터 160비트의 해시값을 만들어 낸다. 로널드 라이베스트가 만든 MD4와 MD5 해시함수에서 사용했던 것과 비슷한 방법에 기초한다.
우분투 WSL2의 Git 버전 이슈
우분투 WSL2의 git은 2.17버전으로 설치되어 있어서 새로운 명령어인 switch와 restore를 사용할 수 없다. 따라서 버전업을 해주었다.
- sudo add-apt-repository ppa:git-core/ppa (레포지토리 추가)
- sudo apt-get update (업데이트)
- sudo apt-get install git (새로 깃 설치)
Branch란?
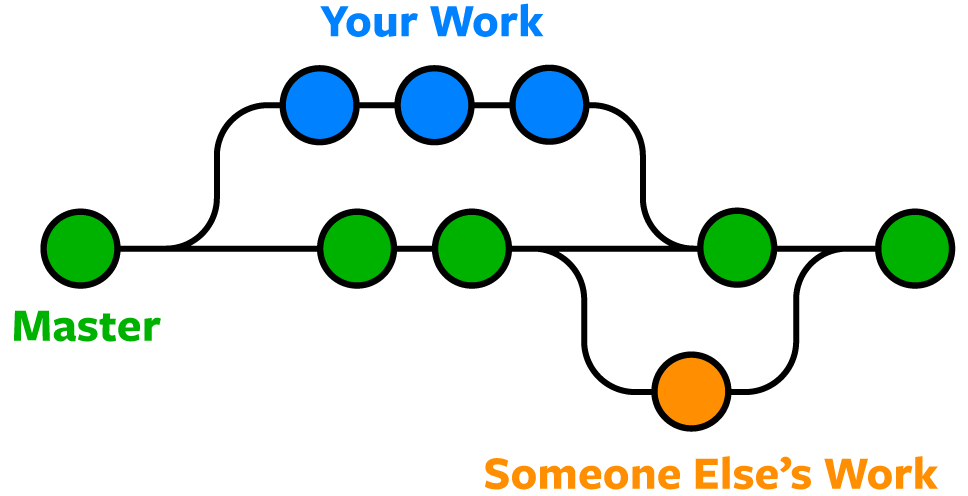
위에서 살펴본 바와 같이 개발자들이 git을 통해 동일한 소스코드 위에서 개발을 할 때에 동시에 병렬적으로 다양한 작업을 할 수 있게 만들어 주는 기능이 바로 '브랜치(branch)'이다. 각자의 저장소 안에서 분리되어 개발을 하고 실험적인 버전을 만들기도 하며, 변경된 내용은 원래의 버전과 병합하여 하나로 모을 수도 있고, 각 브랜치는 다른 브랜치의 영향을 받지 않으며 브랜치를 만드는 시점을 조절할 수도 있다. 위의 그림이 이를 참 잘 나타낸 것 같다.
여러 명이 협업하는 경우 메인 브랜치에서 자신만의 작업 브랜치를 만든 후 개발을 진행하고 변경사항을 자신의 브랜치에 적용하여 독립적으로 작업을 수행할 수 있다. 이를 통한 결과는 병합하여 하나로 모아나가는 방식으로 개발을 진행할 수 있을 것이다. 이렇게 하면 중간에 생긴 문제를 점검하거나 개선해 나아가는 데에 유리할 것이다.
* gitflow workflow
(우아한 형제들의 나동호 님의 기술 블로그 글을 참고하였습니다)
workflow 종류 중 Git-flow만을 살펴본다.
Git-flow에는 5가지 브랜치가 존재한다. 메인 브랜치인 master(main), develop과 일정 기간 동안만 유지되는 보조 브랜치인 feature, release, hotfix가 있다.
master(main) 브랜치는 제품으로 출시될 수 있는 버전,
develop 브랜치는 다음 출시 버전을 개발하는 브랜치,
feature은 기능 개발,
release는 이번 출시 버전을 준비하는 브랜치,
hotfix는 출시 버전에서 발생한 버그를 긴급하게 수정하는 브랜치이다.
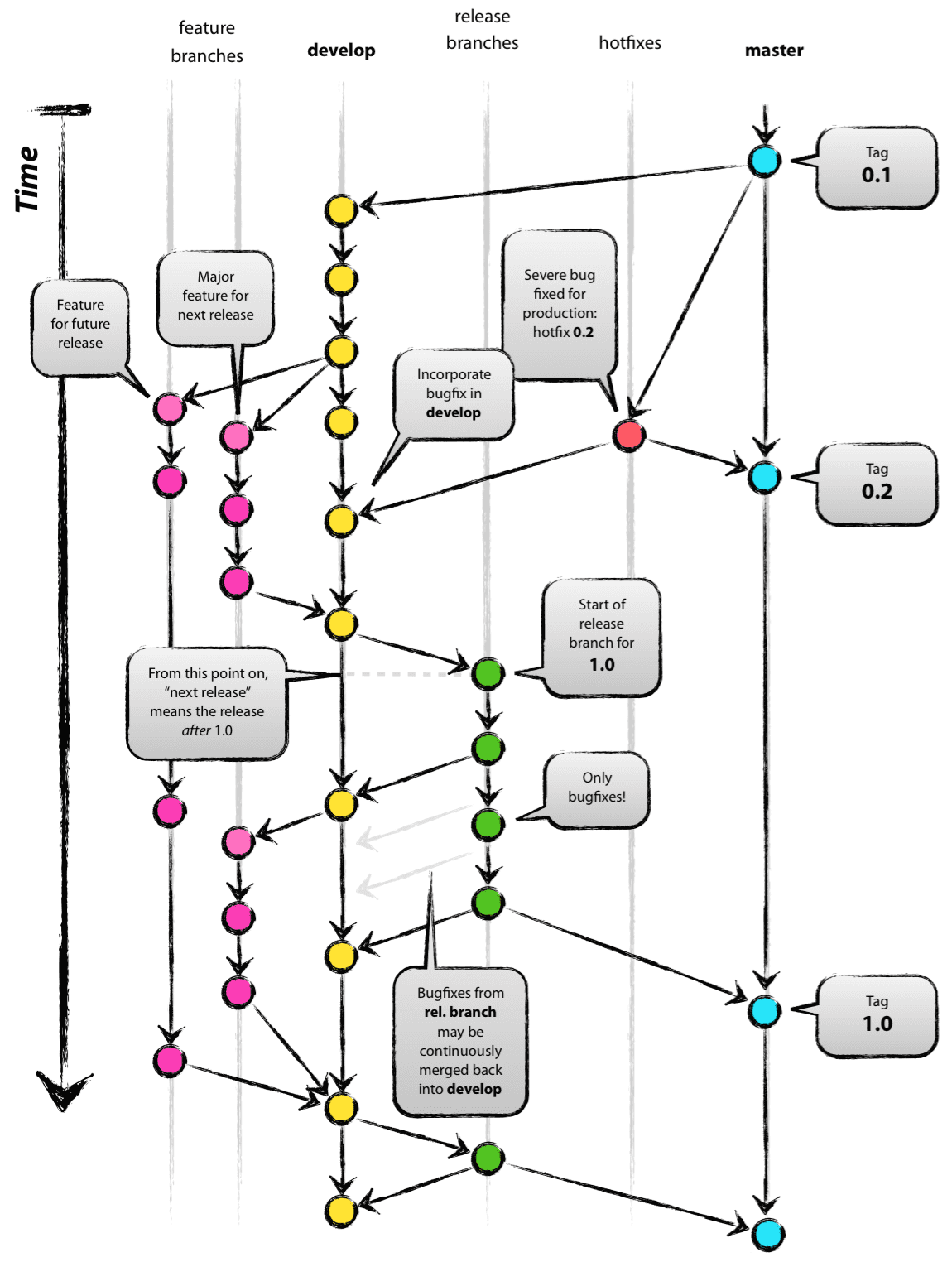
위 그림을 보면, 처음에 master와 master로 파생된 develop 브랜치가 존재하며 develop 브랜치에서는 상시로 버그를 수정한 커밋들이 추가된다.
새로운 기능 추가시 develop에서 feature 브랜치를 생성하여 추가하고 완료되면 develop브랜치를 병합한다.
모든 기능이 병합되면 QA(Quality Assurance)를 위해 release 브랜치를 생성하여 QA를 통해 발생한 버그들을 release 브랜치에 수정한다. QA가 끝나면 이를 master와 develop 브랜치로 병합하고 마지막으로 출시된 master에서 버전 태그를 추가한다.
왜 이런 전략이 필요할까?
다른 워크플로우와 마찬가지로 중앙 저장소를 사용하여 로컬에서 작업하고 중앙 저장소로 푸쉬하는 것을 동일하나 브랜치의 구조가 다르다. 이와 같이 중앙 저장소로부터 로컬에서 작업하는 워크플로우들의 경우 개발자들이 실험적인 개발을 시도해볼 수 있다.(중앙집중식 워크플로우의 경우 실험하기에는 위험이 따르기 때문) 특히 Git-flow 방식은 대형 프로젝트에서도 적용하여 개발의 체계화를 높여 빠른 대응이가능하고 이해하기 쉽고 팀 구성원이 분기 및 릴리스 프로세스에 대한 공통된 이해를 바탕으로 개발할 수 있는 우아한 멘탈 모델을 형성할 수 있다.
최근, 이를 구상한 Vincent Driessen은 최근 웹앱의 개발의 경우 Github-flow를 추천한다고 반성문(?)을 올린 바 있다. Github-flow 보러가기
IDE란?
프로그램 개발에 관련된 모든 작업을 하나의 프로그램 안에서 처리하는 환경을 제공하는 소프트웨어이다. (컴파일, 텍스트 편집, 디버그 등..)
파이참이나 VSC 밖에 써보질 못했으나 VSC의 다양한 확장 프로그램이나 인터페이스는 참 편한 것 같다.
LTS버전?
장기 지원 버전(Long Term Support). 오픈소스 프로젝트에서 적용되는 것으로 유지보수기간을 길게 지원하고 새로운 버전의 배포에 따른 위험부담을 줄이고 소프트웨어의 신뢰성을 높이기 위함이다.
Javascript
Javascript의 배열
자바스크립트의 배열은 각각 메모리의 크기가 같지 않아도 되고 연속적이 아닐 수 있는 해시테이블로 구현된 객체라고 한다. 따라서 일반적인 배열과 달리 인덱스로 접근시 느리나, 특정 요소를 찾거나 삽입/삭제를 하는 경우에는 일반적인 배열보다 빠르다.
최근에는 모던 엔진들이 인덱스를 통한 접근시에도 최적화를 하여, 인덱스로 접근시 객체보다 빠르다. (이웅모, "모던 자바스크립트 Deep Dive", 위키북스 참고)
따라서 배열의 인덱스를 이용해 값을 다루는 것도 물론 필요하지만
filter, forEach, map과 같은 함수를 적극 이용하는 것도 필요하다고 생각한다.
ES6를 이용해 배열 깊은 복사하기
최신 문법 ES6에서는 [...Arr]를 이용해 배열의 깊은 복사가 가능해졌다.
<예시>
// 얕은 복사
const A = [1,2,3];
const B = A;
A.push(4);
console.log(A) // 결과값 [1,2,3,4]
console.log(B) // 결과값 [1,2,3,4]
// 깊은 복사
const A = [1,2,3];
const B = [...A];
A.push(4);
console.log(A) // 결과값 [1,2,3,4]
console.log(B) // 결과값 [1,2,3]확인할 사항
문자열과 숫자의 정렬
자바스크립트 sort() 함수에서, 배열 내부의 요소가 문자열 또는 숫자인 경우 취급이 문제될 수 있다.
<숫자의 경우>
const A = [3,4,5,2];
A.sort();
console.log(A); // 결과값 [2,3,4,5]
<문자열의 경우>
const A = ['abc','cc','b','A','D'];
A.sort();
console.log(A); // 결과값 ["A", "D", "abc", "b", "cc"]이렇듯 문자열의 경우 sort함수만으로도 꽤나 좋은 성능을 낼 수 있다. 다만 문제가 있다.
<문자열로 주어진 숫자의 경우 정렬 문제>
const A = ['15','3','11','5','2'];
A.sort();
console.log(A); // 결과값 ["11", "15", "2", "3", "5"]위에서 보듯이, 숫자로 주어진 문자열의 경우 문자열로 취급하여 정렬하다보니 숫자의 대소를 판단하지 않는다.
그래서, 위와 같은 문제를 해결하기 위해 나는 다음과 같은 정렬 함수를 정의했다.
참고 sort(compareFunction)
- compareFunction(a, b)이 0보다 작은 경우 a를 b보다 낮은 색인으로 정렬합니다. 즉, a가 먼저옵니다. :오름차순 정렬
- compareFunction(a, b)이 0을 반환하면 a와 b를 서로에 대해 변경하지 않고 모든 다른 요소에 대해 정렬합니다.
<정렬 함수>
const ascSort = (arr) =>
arr.sort((a, b) => {
// 둘다 숫자인 경우 값을 비교해서 오름차순 정렬
if (!isNaN(a) && !isNaN(b)) return a - b; // '5'-'3' === 2 :true
// 둘다 문자열인 경우
if (isNaN(a) && isNaN(b)) {
// 길이가 다른 경우 길이순 오름차순 정렬
if (a.length !== b.length) return a.length - b.length;
// 길이가 같은 경우 아스키코드 오름차순 정렬
else return a.charCodeAt() - b.charCodeAt();
} else return isNaN(a) - isNaN(b); // 그 외의 경우, 숫자가 앞으로 오도록 정렬
});여기서 isNaN 함수는 is Not a Number의 약자로, 값이 숫자만으로 이루어진 경우에는 false를 그 외의 경우 true를 반환한다.
마지막 줄의 isNaN(a)의 값이 true인 경우 1의 값을, isNaN(b)가 false인 경우 0의 값을 가지므로 둘이 같은 형태의 경우 정렬하지 않게 되고 숫자가 문자보다 앞으로 정렬되게 된다.
함수 분리의 기준
함수를 나눌 때, 나는 하나의 함수는 최대한 하나의 기능만 하도록 정의한다. 예를 들어, 정렬 함수는 정렬만, 집합을 만드는 함수는 집합만 만드는 것처럼 말이다. 이후에 알게된 것이지만 이는 순수함수를 만족시킬 수 있는 조건이다.
느낀점
공부한 것을 정리하다보니 내가 아는 것으로 착각하고 있는 부분이 상당히 많았다. 모르는 것을 모두 다 배울 수는 없지만 적어도 모르는 것을 알게되는 게 중요하다는 의미를 알게 되었다.
